 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA spatial-temporal short-term traffic flow prediction model based on dynamical-learning graph convolution mechanism
May 10, 2022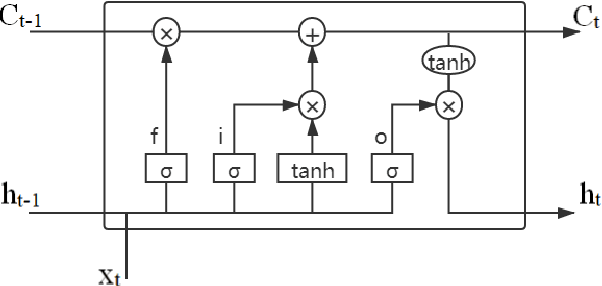



Short-term traffic flow prediction is a vital branch of the Intelligent Traffic System (ITS) and plays an important role in traffic management. Graph convolution network (GCN) is widely used in traffic prediction models to better deal with the graphical structure data of road networks. However, the influence weights among different road sections are usually distinct in real life, and hard to be manually analyzed. Traditional GCN mechanism, relying on manually-set adjacency matrix, is unable to dynamically learn such spatial pattern during the training. To deal with this drawback, this paper proposes a novel location graph convolutional network (Location-GCN). Location-GCN solves this problem by adding a new learnable matrix into the GCN mechanism, using the absolute value of this matrix to represent the distinct influence levels among different nodes. Then, long short-term memory (LSTM) is employed in the proposed traffic prediction model. Moreover, Trigonometric function encoding is used in this study to enable the short-term input sequence to convey the long-term periodical information. Ultimately, the proposed model is compared with the baseline models and evaluated on two real word traffic flow datasets. The results show our model is more accurate and robust on both datasets than other representative traffic prediction models.
Feature selection for classification with class-separability strategy and data envelopment analysis
Feb 01, 2015



In this paper, a novel feature selection method is presented, which is based on Class-Separability (CS) strategy and Data Envelopment Analysis (DEA). To better capture the relationship between features and the class, class labels are separated into individual variables and relevance and redundancy are explicitly handled on each class label. Super-efficiency DEA is employed to evaluate and rank features via their conditional dependence scores on all class labels, and the feature with maximum super-efficiency score is then added in the conditioning set for conditional dependence estimation in the next iteration, in such a way as to iteratively select features and get the final selected features. Eventually, experiments are conducted to evaluate the effectiveness of proposed method comparing with four state-of-the-art methods from the viewpoint of classification accuracy. Empirical results verify the feasibility and the superiority of proposed feature selection method.
Feature Selection with Redundancy-complementariness Dispersion
Feb 01, 2015
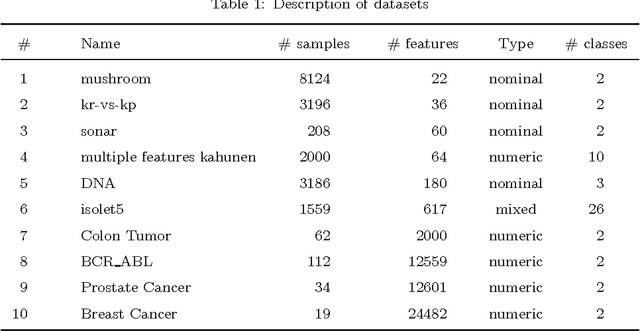
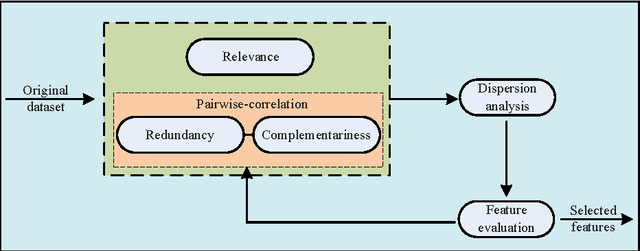
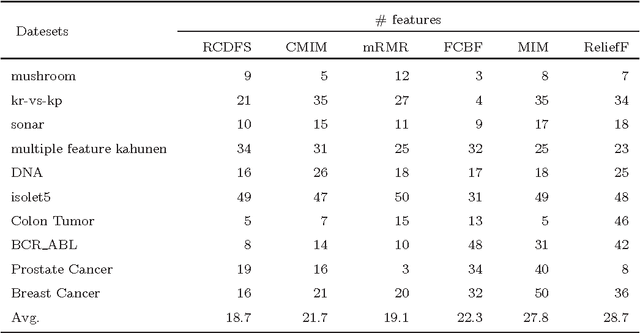
Feature selection has attracted significant attention in data mining and machine learning in the past decades. Many existing feature selection methods eliminate redundancy by measuring pairwise inter-correlation of features, whereas the complementariness of features and higher inter-correlation among more than two features are ignored. In this study, a modification item concerning the complementariness of features is introduced in the evaluation criterion of features. Additionally, in order to identify the interference effect of already-selected False Positives (FPs), the redundancy-complementariness dispersion is also taken into account to adjust the measurement of pairwise inter-correlation of features. To illustrate the effectiveness of proposed method, classification experiments are applied with four frequently used classifiers on ten datasets. Classification results verify the superiority of proposed method compared with five representative feature selection methods.