 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Invariant Inter-pixel Correlations for Superpixel Generation
Feb 28, 2024



Deep superpixel algorithms have made remarkable strides by substituting hand-crafted features with learnable ones. Nevertheless, we observe that existing deep superpixel methods, serving as mid-level representation operations, remain sensitive to the statistical properties (e.g., color distribution, high-level semantics) embedded within the training dataset. Consequently, learnable features exhibit constrained discriminative capability, resulting in unsatisfactory pixel grouping performance, particularly in untrainable application scenarios. To address this issue, we propose the Content Disentangle Superpixel (CDS) algorithm to selectively separate the invariant inter-pixel correlations and statistical properties, i.e., style noise. Specifically, We first construct auxiliary modalities that are homologous to the original RGB image but have substantial stylistic variations. Then, driven by mutual information, we propose the local-grid correlation alignment across modalities to reduce the distribution discrepancy of adaptively selected features and learn invariant inter-pixel correlations. Afterwards, we perform global-style mutual information minimization to enforce the separation of invariant content and train data styles. The experimental results on four benchmark datasets demonstrate the superiority of our approach to existing state-of-the-art methods, regarding boundary adherence, generalization, and efficiency. Code and pre-trained model are available at https://github.com/rookiie/CDSpixel.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020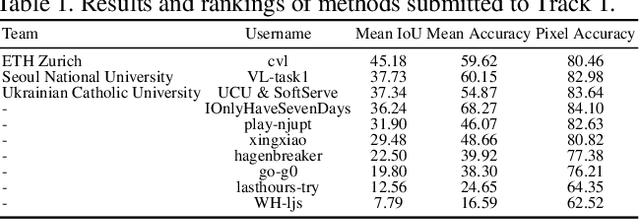
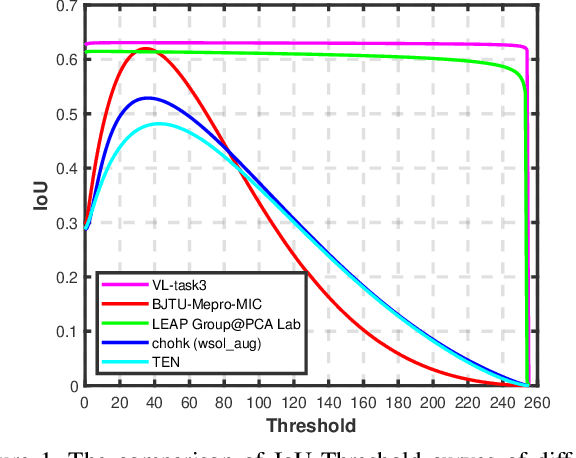

Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
VehicleNet: Learning Robust Visual Representation for Vehicle Re-identification
Apr 14, 2020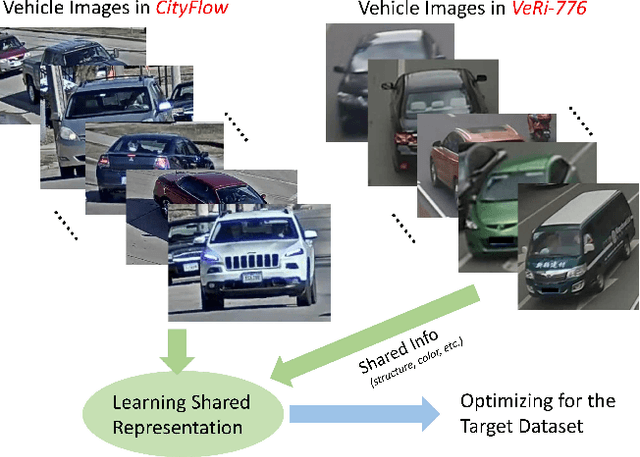
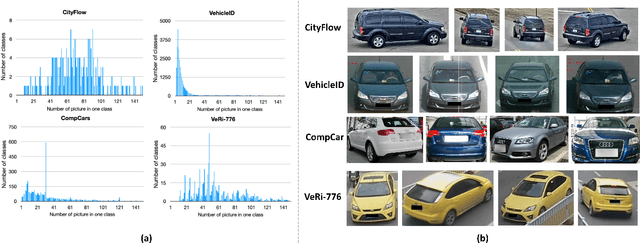
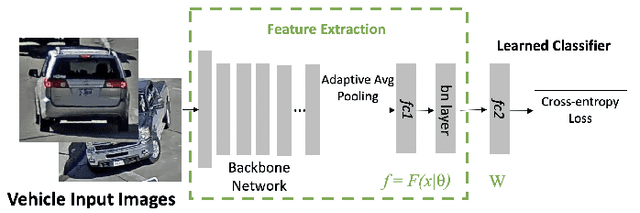
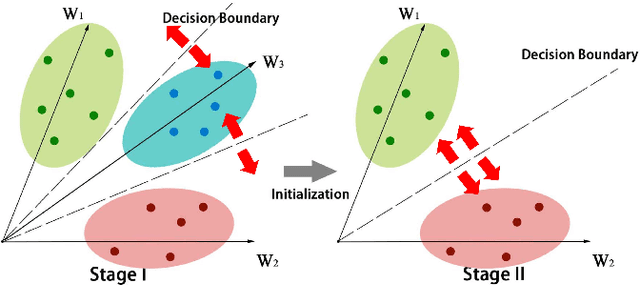
One fundamental challenge of vehicle re-identification (re-id) is to learn robust and discriminative visual representation, given the significant intra-class vehicle variations across different camera views. As the existing vehicle datasets are limited in terms of training images and viewpoints, we propose to build a unique large-scale vehicle dataset (called VehicleNet) by harnessing four public vehicle datasets, and design a simple yet effective two-stage progressive approach to learning more robust visual representation from VehicleNet. The first stage of our approach is to learn the generic representation for all domains (i.e., source vehicle datasets) by training with the conventional classification loss. This stage relaxes the full alignment between the training and testing domains, as it is agnostic to the target vehicle domain. The second stage is to fine-tune the trained model purely based on the target vehicle set, by minimizing the distribution discrepancy between our VehicleNet and any target domain. We discuss our proposed multi-source dataset VehicleNet and evaluate the effectiveness of the two-stage progressive representation learning through extensive experiments. We achieve the state-of-art accuracy of 86.07% mAP on the private test set of AICity Challenge, and competitive results on two other public vehicle re-id datasets, i.e., VeRi-776 and VehicleID. We hope this new VehicleNet dataset and the learned robust representations can pave the way for vehicle re-id in the real-world environments.
Devil in the Details: Towards Accurate Single and Multiple Human Parsing
Sep 17, 2018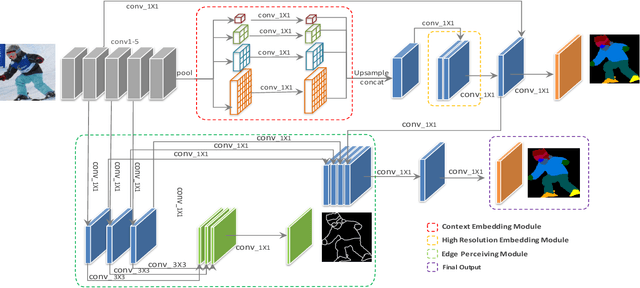
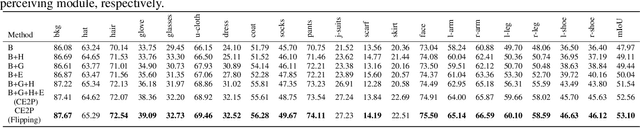
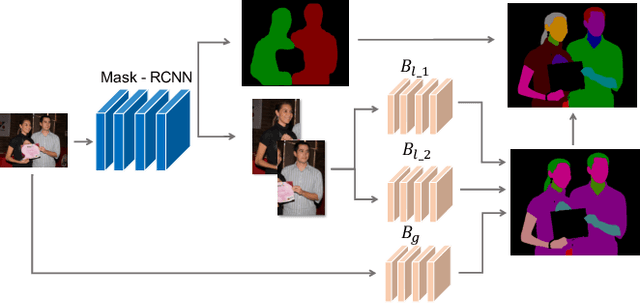
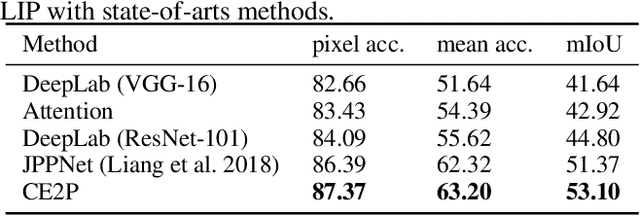
Human parsing has received considerable interest due to its wide application potentials. Nevertheless, it is still unclear how to develop an accurate human parsing system in an efficient and elegant way. In this paper, we identify several useful properties, including feature resolution, global context information and edge details, and perform rigorous analyses to reveal how to leverage them to benefit the human parsing task. The advantages of these useful properties finally result in a simple yet effective Context Embedding with Edge Perceiving (CE2P) framework for single human parsing. Our CE2P is end-to-end trainable and can be easily adopted for conducting multiple human parsing. Benefiting the superiority of CE2P, we achieved the 1st places on all three human parsing benchmarks. Without any bells and whistles, we achieved 56.50\% (mIoU), 45.31\% (mean $AP^r$) and 33.34\% ($AP^p_{0.5}$) in LIP, CIHP and MHP v2.0, which outperform the state-of-the-arts more than 2.06\%, 3.81\% and 1.87\%, respectively. We hope our CE2P will serve as a solid baseline and help ease future research in single/multiple human parsing. Code has been made available at \url{https://github.com/liutinglt/CE2P}.