 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Robustness Against Adversarial Examples
Paper and Code
Dec 04, 2020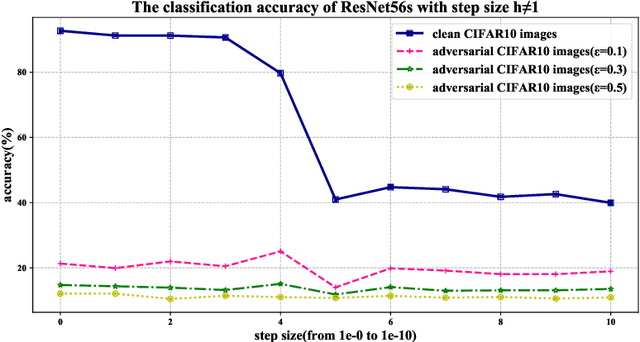
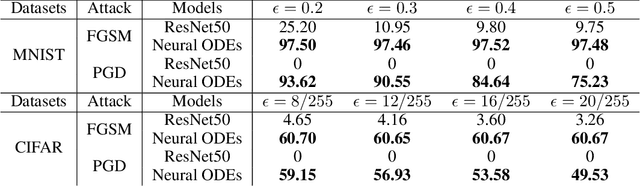
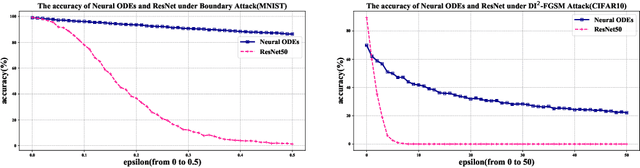

Recent studies have shown that deep neural networks are vulnerable to adversarial examples, but most of the methods proposed to defense adversarial examples cannot solve this problem fundamentally. In this paper, we theoretically prove that there is an upper bound for neural networks with identity mappings to constrain the error caused by adversarial noises. However, in actual computations, this kind of neural network no longer holds any upper bound and is therefore susceptible to adversarial examples. Following similar procedures, we explain why adversarial examples can fool other deep neural networks with skip connections. Furthermore, we demonstrate that a new family of deep neural networks called Neural ODEs (Chen et al., 2018) holds a weaker upper bound. This weaker upper bound prevents the amount of change in the result from being too large. Thus, Neural ODEs have natural robustness against adversarial examples. We evaluate the performance of Neural ODEs compared with ResNet under three white-box adversarial attacks (FGSM, PGD, DI2-FGSM) and one black-box adversarial attack (Boundary Attack). Finally, we show that the natural robustness of Neural ODEs is even better than the robustness of neural networks that are trained with adversarial training methods, such as TRADES and YOPO.