 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparent Anomaly Detection via Concept-based Explanations
Nov 01, 2023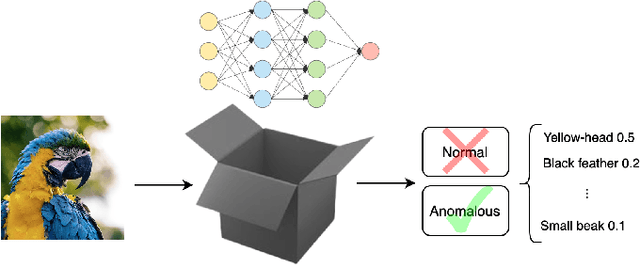
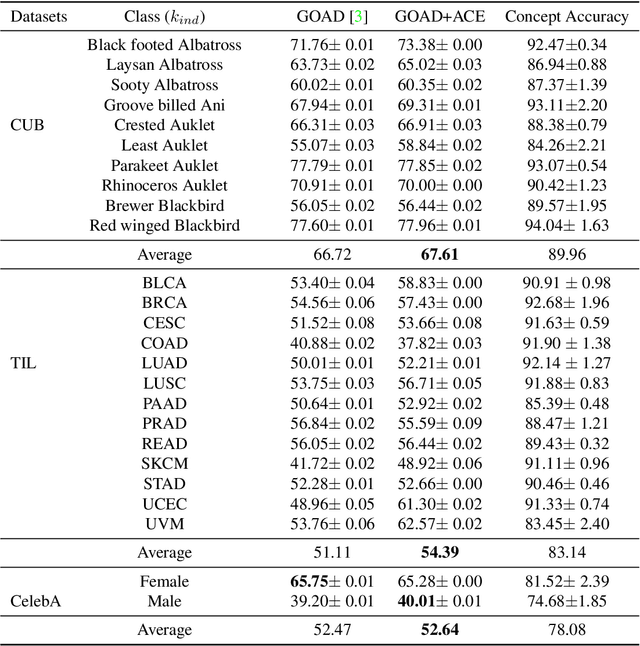
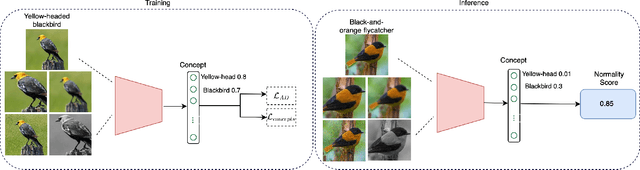
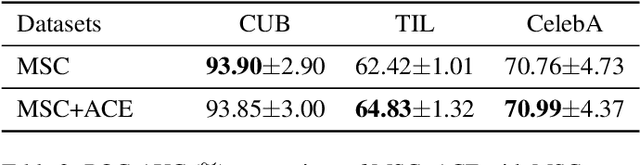
Advancements in deep learning techniques have given a boost to the performance of anomaly detection. However, real-world and safety-critical applications demand a level of transparency and reasoning beyond accuracy. The task of anomaly detection (AD) focuses on finding whether a given sample follows the learned distribution. Existing methods lack the ability to reason with clear explanations for their outcomes. Hence to overcome this challenge, we propose Transparent {A}nomaly Detection {C}oncept {E}xplanations (ACE). ACE is able to provide human interpretable explanations in the form of concepts along with anomaly prediction. To the best of our knowledge, this is the first paper that proposes interpretable by-design anomaly detection. In addition to promoting transparency in AD, it allows for effective human-model interaction. Our proposed model shows either higher or comparable results to black-box uninterpretable models. We validate the performance of ACE across three realistic datasets - bird classification on CUB-200-2011, challenging histopathology slide image classification on TIL-WSI-TCGA, and gender classification on CelebA. We further demonstrate that our concept learning paradigm can be seamlessly integrated with other classification-based AD methods.
Source-free Domain Adaptation Requires Penalized Diversity
Apr 12, 2023



While neural networks are capable of achieving human-like performance in many tasks such as image classification, the impressive performance of each model is limited to its own dataset. Source-free domain adaptation (SFDA) was introduced to address knowledge transfer between different domains in the absence of source data, thus, increasing data privacy. Diversity in representation space can be vital to a model`s adaptability in varied and difficult domains. In unsupervised SFDA, the diversity is limited to learning a single hypothesis on the source or learning multiple hypotheses with a shared feature extractor. Motivated by the improved predictive performance of ensembles, we propose a novel unsupervised SFDA algorithm that promotes representational diversity through the use of separate feature extractors with Distinct Backbone Architectures (DBA). Although diversity in feature space is increased, the unconstrained mutual information (MI) maximization may potentially introduce amplification of weak hypotheses. Thus we introduce the Weak Hypothesis Penalization (WHP) regularizer as a mitigation strategy. Our work proposes Penalized Diversity (PD) where the synergy of DBA and WHP is applied to unsupervised source-free domain adaptation for covariate shift. In addition, PD is augmented with a weighted MI maximization objective for label distribution shift. Empirical results on natural, synthetic, and medical domains demonstrate the effectiveness of PD under different distributional shifts.
on the effectiveness of generative adversarial network on anomaly detection
Dec 31, 2021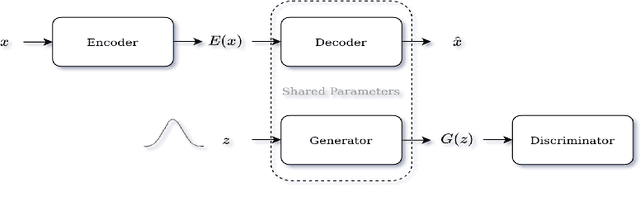

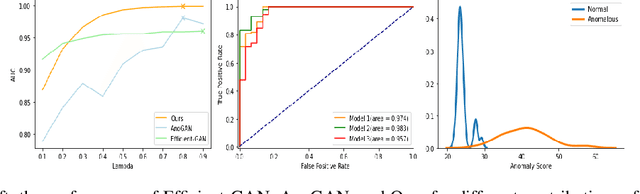
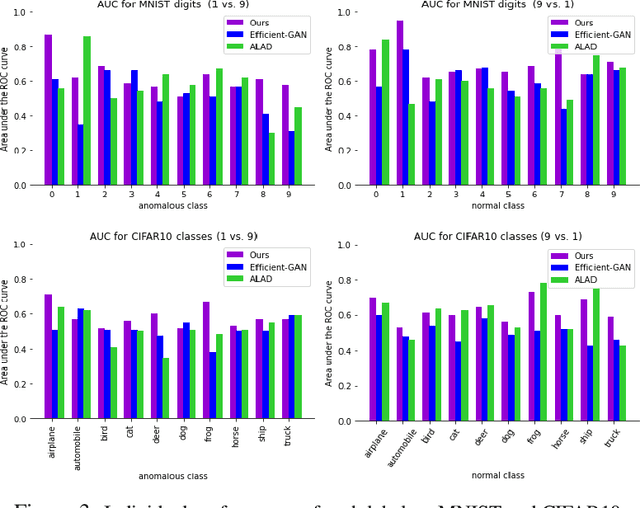
Identifying anomalies refers to detecting samples that do not resemble the training data distribution. Many generative models have been used to find anomalies, and among them, generative adversarial network (GAN)-based approaches are currently very popular. GANs mainly rely on the rich contextual information of these models to identify the actual training distribution. Following this analogy, we suggested a new unsupervised model based on GANs --a combination of an autoencoder and a GAN. Further, a new scoring function was introduced to target anomalies where a linear combination of the internal representation of the discriminator and the generator's visual representation, plus the encoded representation of the autoencoder, come together to define the proposed anomaly score. The model was further evaluated on benchmark datasets such as SVHN, CIFAR10, and MNIST, as well as a public medical dataset of leukemia images. In all the experiments, our model outperformed its existing counterparts while slightly improving the inference time.