 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparent Anomaly Detection via Concept-based Explanations
Nov 01, 2023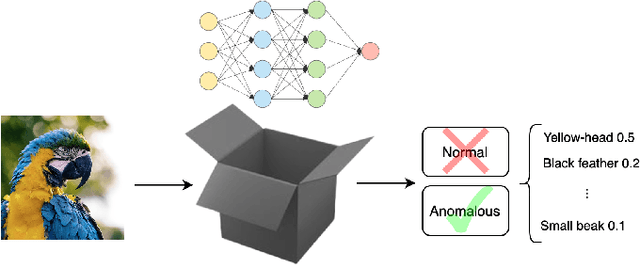
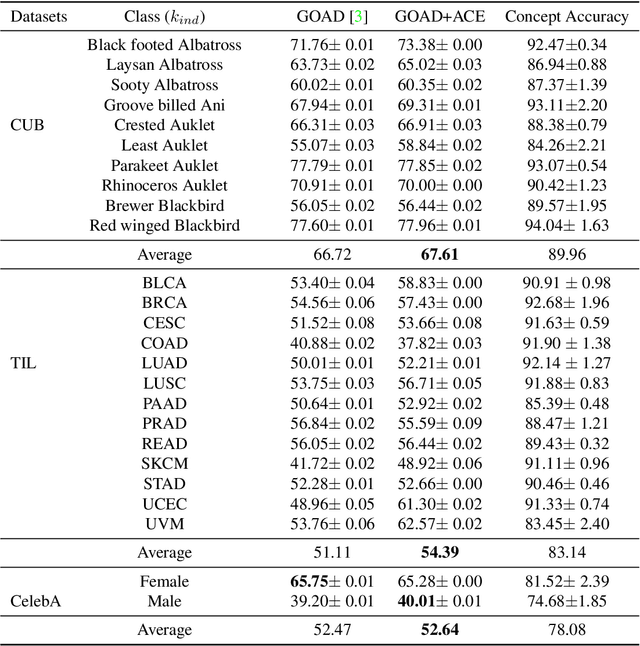
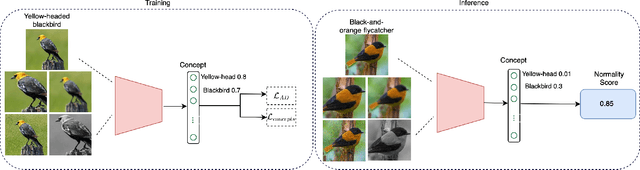
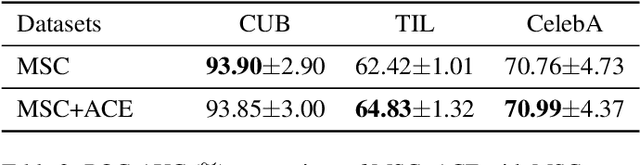
Advancements in deep learning techniques have given a boost to the performance of anomaly detection. However, real-world and safety-critical applications demand a level of transparency and reasoning beyond accuracy. The task of anomaly detection (AD) focuses on finding whether a given sample follows the learned distribution. Existing methods lack the ability to reason with clear explanations for their outcomes. Hence to overcome this challenge, we propose Transparent {A}nomaly Detection {C}oncept {E}xplanations (ACE). ACE is able to provide human interpretable explanations in the form of concepts along with anomaly prediction. To the best of our knowledge, this is the first paper that proposes interpretable by-design anomaly detection. In addition to promoting transparency in AD, it allows for effective human-model interaction. Our proposed model shows either higher or comparable results to black-box uninterpretable models. We validate the performance of ACE across three realistic datasets - bird classification on CUB-200-2011, challenging histopathology slide image classification on TIL-WSI-TCGA, and gender classification on CelebA. We further demonstrate that our concept learning paradigm can be seamlessly integrated with other classification-based AD methods.