 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCES-KD: Curriculum-based Expert Selection for Guided Knowledge Distillation
Sep 15, 2022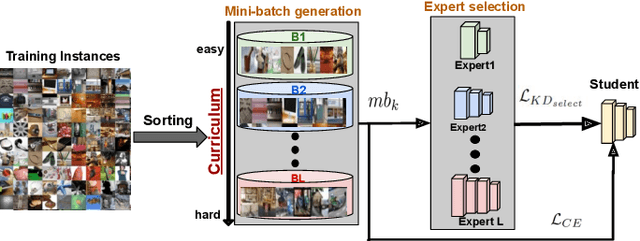
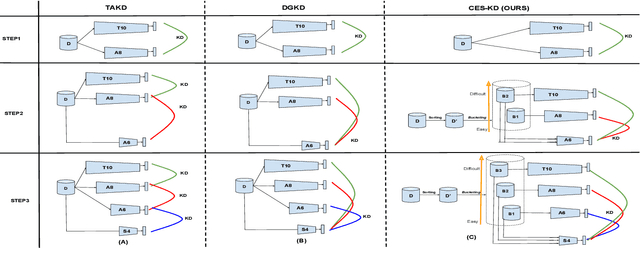
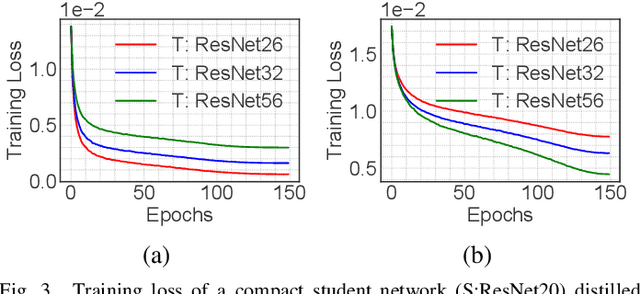
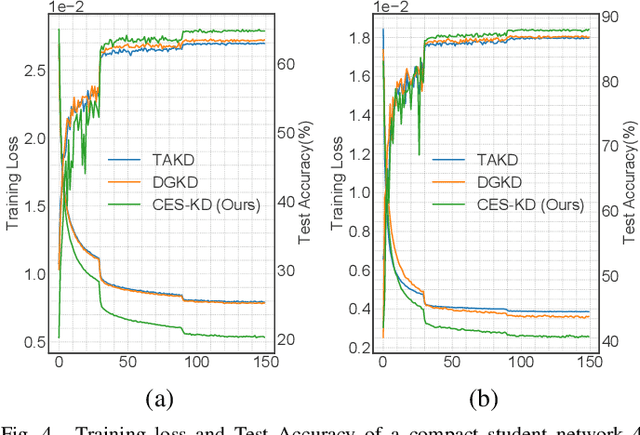
Knowledge distillation (KD) is an effective tool for compressing deep classification models for edge devices. However, the performance of KD is affected by the large capacity gap between the teacher and student networks. Recent methods have resorted to a multiple teacher assistant (TA) setting for KD, which sequentially decreases the size of the teacher model to relatively bridge the size gap between these models. This paper proposes a new technique called Curriculum Expert Selection for Knowledge Distillation (CES-KD) to efficiently enhance the learning of a compact student under the capacity gap problem. This technique is built upon the hypothesis that a student network should be guided gradually using stratified teaching curriculum as it learns easy (hard) data samples better and faster from a lower (higher) capacity teacher network. Specifically, our method is a gradual TA-based KD technique that selects a single teacher per input image based on a curriculum driven by the difficulty in classifying the image. In this work, we empirically verify our hypothesis and rigorously experiment with CIFAR-10, CIFAR-100, CINIC-10, and ImageNet datasets and show improved accuracy on VGG-like models, ResNets, and WideResNets architectures.
Efficient Fine-Tuning of Compressed Language Models with Learners
Aug 03, 2022
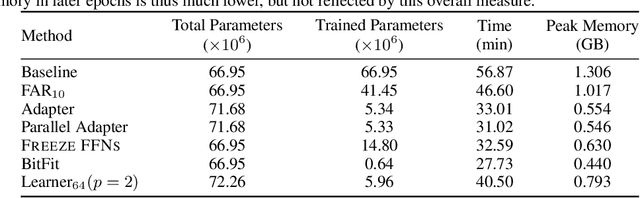

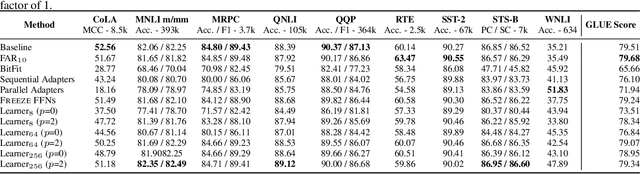
Fine-tuning BERT-based models is resource-intensive in memory, computation, and time. While many prior works aim to improve inference efficiency via compression techniques, e.g., pruning, these works do not explicitly address the computational challenges of training to downstream tasks. We introduce Learner modules and priming, novel methods for fine-tuning that exploit the overparameterization of pre-trained language models to gain benefits in convergence speed and resource utilization. Learner modules navigate the double bind of 1) training efficiently by fine-tuning a subset of parameters, and 2) training effectively by ensuring quick convergence and high metric scores. Our results on DistilBERT demonstrate that learners perform on par with or surpass the baselines. Learners train 7x fewer parameters than state-of-the-art methods on GLUE. On CoLA, learners fine-tune 20% faster, and have significantly lower resource utilization.
Efficient Fine-Tuning of BERT Models on the Edge
May 03, 2022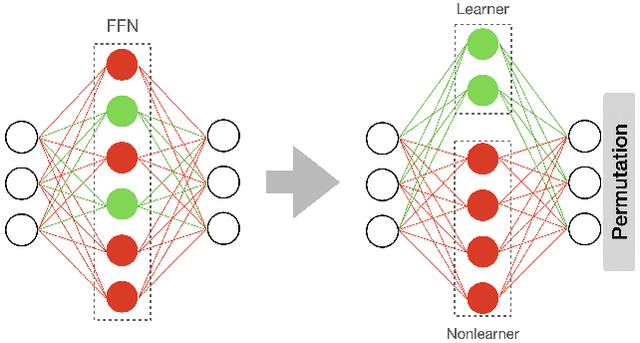
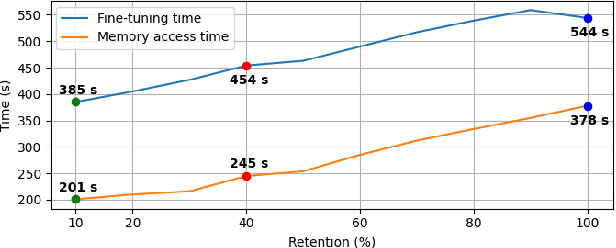

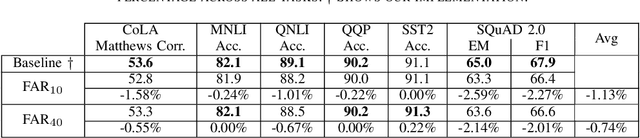
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.