 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Pruning of Fine-tuning Datasets for Transformer-based Language Models
Jul 11, 2024Transformer-based language models have shown state-of-the-art performance on a variety of natural language understanding tasks. To achieve this performance, these models are first pre-trained on general corpus and then fine-tuned on downstream tasks. Previous work studied the effect of pruning the training set of the downstream tasks on the performance of the model on its evaluation set. In this work, we propose an automatic dataset pruning method for the training set of fine-tuning tasks. Our method is based on the model's success rate in correctly classifying each training data point. Unlike previous work which relies on user feedback to determine subset size, our method automatically extracts training subsets that are adapted for each pair of model and fine-tuning task. Our method provides multiple subsets for use in dataset pruning that navigate the trade-off between subset size and evaluation accuracy. Our largest subset, which we also refer to as the winning ticket subset, is on average $3 \times$ smaller than the original training set of the fine-tuning task. Our experiments on 5 downstream tasks and 2 language models show that, on average, fine-tuning on the winning ticket subsets results in a $0.1 \%$ increase in the evaluation performance of the model.
Faster Inference of Integer SWIN Transformer by Removing the GELU Activation
Feb 02, 2024SWIN transformer is a prominent vision transformer model that has state-of-the-art accuracy in image classification tasks. Despite this success, its unique architecture causes slower inference compared with similar deep neural networks. Integer quantization of the model is one of the methods used to improve its inference latency. However, state-of-the-art has not been able to fully quantize the model. In this work, we improve upon the inference latency of the state-of-the-art methods by removing the floating-point operations, which are associated with the GELU activation in Swin Transformer. While previous work proposed to replace the non-integer operations with linear approximation functions, we propose to replace GELU with ReLU activation. The advantage of ReLU over previous methods is its low memory and computation complexity. We use iterative knowledge distillation to compensate for the lost accuracy due to replacing GELU with ReLU. We quantize our GELU-less SWIN transformer and show that on an RTX 4090 NVIDIA GPU we can improve the inference latency of the quantized SWIN transformer by at least $11\%$ while maintaining an accuracy drop of under $0.5\%$ on the ImageNet evaluation dataset.
Integer Fine-tuning of Transformer-based Models
Sep 20, 2022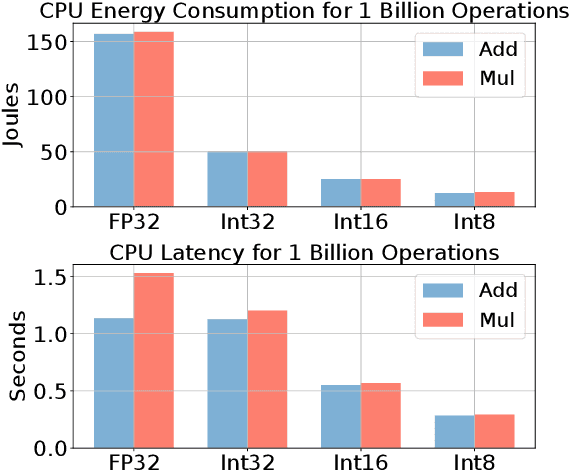
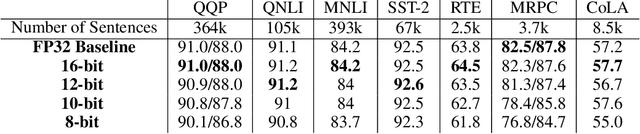
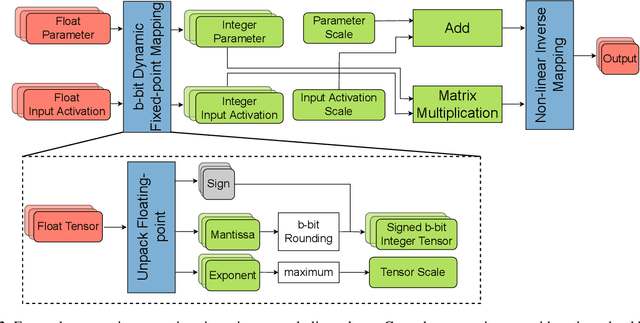
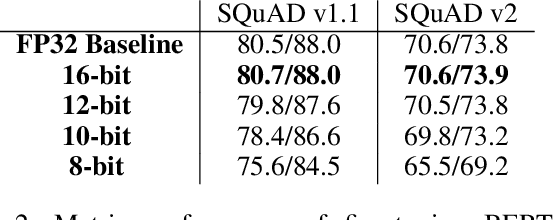
Transformer based models are used to achieve state-of-the-art performance on various deep learning tasks. Since transformer-based models have large numbers of parameters, fine-tuning them on downstream tasks is computationally intensive and energy hungry. Automatic mixed-precision FP32/FP16 fine-tuning of such models has been previously used to lower the compute resource requirements. However, with the recent advances in the low-bit integer back-propagation, it is possible to further reduce the computation and memory foot-print. In this work, we explore a novel integer training method that uses integer arithmetic for both forward propagation and gradient computation of linear, convolutional, layer-norm, and embedding layers in transformer-based models. Furthermore, we study the effect of various integer bit-widths to find the minimum required bit-width for integer fine-tuning of transformer-based models. We fine-tune BERT and ViT models on popular downstream tasks using integer layers. We show that 16-bit integer models match the floating-point baseline performance. Reducing the bit-width to 10, we observe 0.5 average score drop. Finally, further reduction of the bit-width to 8 provides an average score drop of 1.7 points.
Efficient Fine-Tuning of Compressed Language Models with Learners
Aug 03, 2022
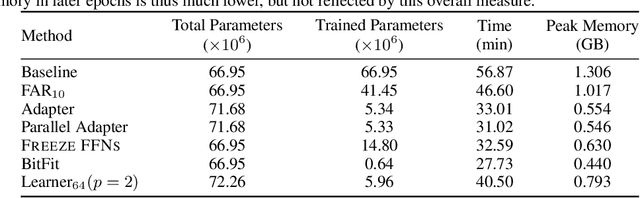

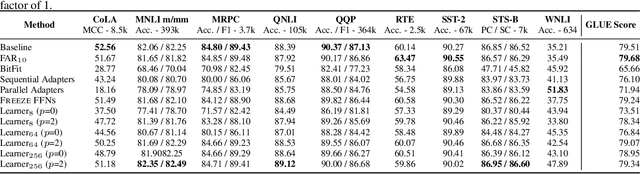
Fine-tuning BERT-based models is resource-intensive in memory, computation, and time. While many prior works aim to improve inference efficiency via compression techniques, e.g., pruning, these works do not explicitly address the computational challenges of training to downstream tasks. We introduce Learner modules and priming, novel methods for fine-tuning that exploit the overparameterization of pre-trained language models to gain benefits in convergence speed and resource utilization. Learner modules navigate the double bind of 1) training efficiently by fine-tuning a subset of parameters, and 2) training effectively by ensuring quick convergence and high metric scores. Our results on DistilBERT demonstrate that learners perform on par with or surpass the baselines. Learners train 7x fewer parameters than state-of-the-art methods on GLUE. On CoLA, learners fine-tune 20% faster, and have significantly lower resource utilization.
Is Integer Arithmetic Enough for Deep Learning Training?
Jul 18, 2022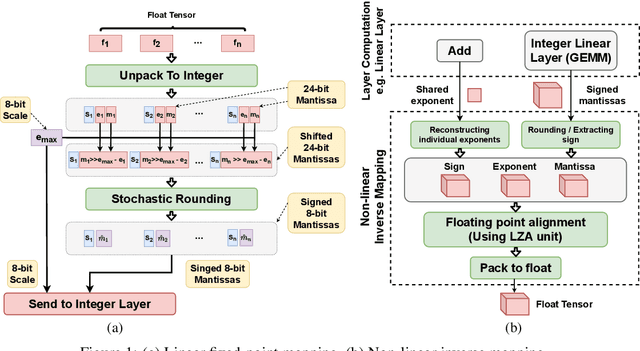
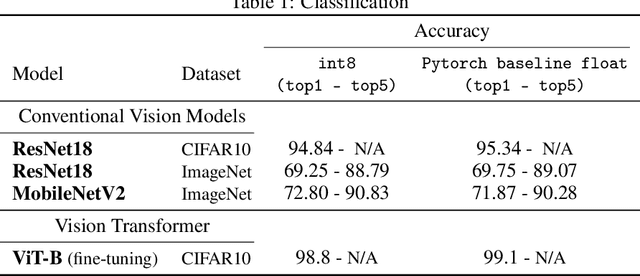
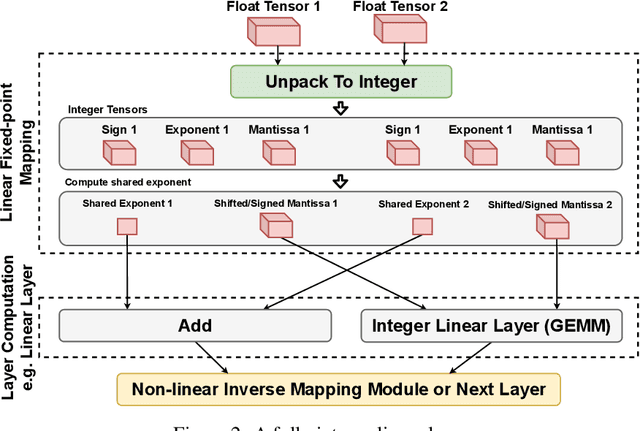
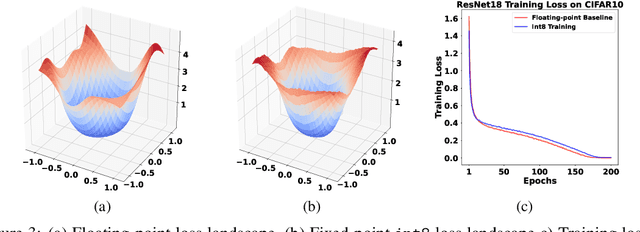
The ever-increasing computational complexity of deep learning models makes their training and deployment difficult on various cloud and edge platforms. Replacing floating-point arithmetic with low-bit integer arithmetic is a promising approach to save energy, memory footprint, and latency of deep learning models. As such, quantization has attracted the attention of researchers in recent years. However, using integer numbers to form a fully functional integer training pipeline including forward pass, back-propagation, and stochastic gradient descent is not studied in detail. Our empirical and mathematical results reveal that integer arithmetic is enough to train deep learning models. Unlike recent proposals, instead of quantization, we directly switch the number representation of computations. Our novel training method forms a fully integer training pipeline that does not change the trajectory of the loss and accuracy compared to floating-point, nor does it need any special hyper-parameter tuning, distribution adjustment, or gradient clipping. Our experimental results show that our proposed method is effective in a wide variety of tasks such as classification (including vision transformers), object detection, and semantic segmentation.
Efficient Fine-Tuning of BERT Models on the Edge
May 03, 2022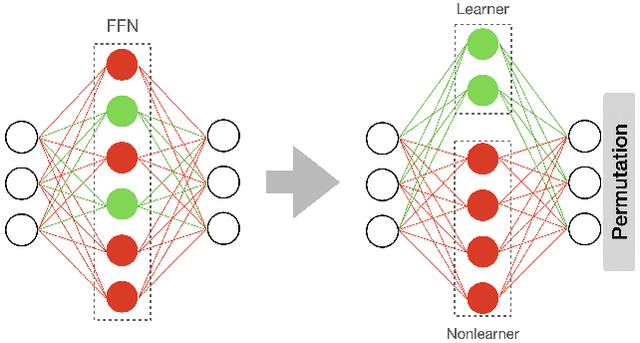
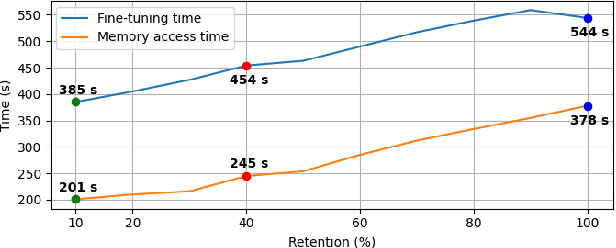

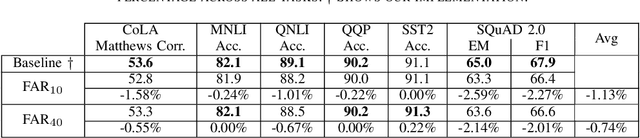
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.