 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Hard Attention Model For Sequentially Observed Scenes
Paper and Code
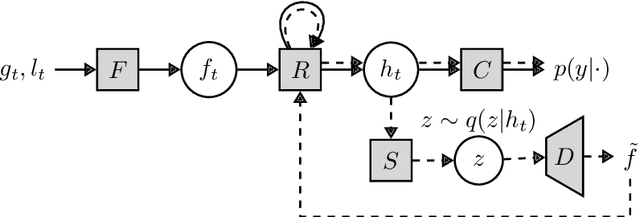
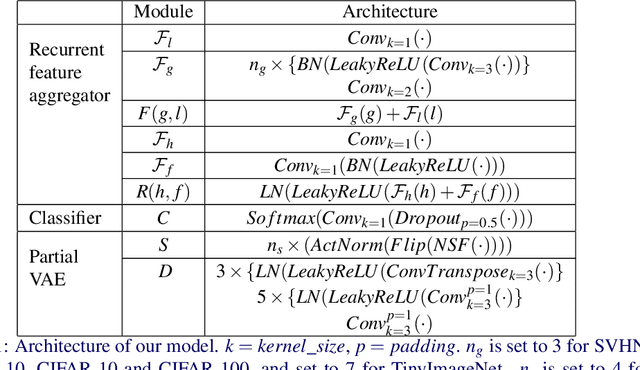
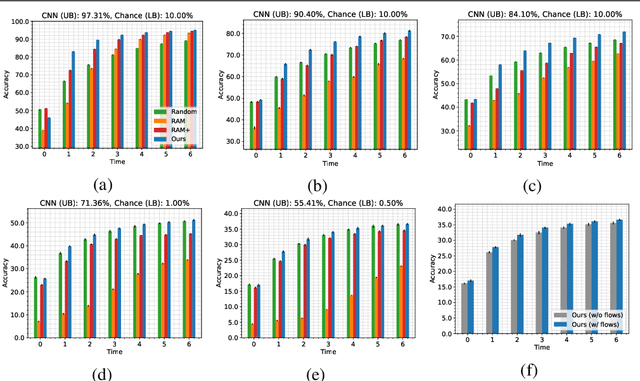
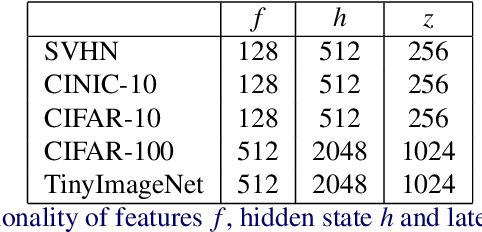
A visual hard attention model actively selects and observes a sequence of subregions in an image to make a prediction. The majority of hard attention models determine the attention-worthy regions by first analyzing a complete image. However, it may be the case that the entire image is not available initially but instead sensed gradually through a series of partial observations. In this paper, we design an efficient hard attention model for classifying such sequentially observed scenes. The presented model never observes an image completely. To select informative regions under partial observability, the model uses Bayesian Optimal Experiment Design. First, it synthesizes the features of the unobserved regions based on the already observed regions. Then, it uses the predicted features to estimate the expected information gain (EIG) attained, should various regions be attended. Finally, the model attends to the actual content on the location where the EIG mentioned above is maximum. The model uses a) a recurrent feature aggregator to maintain a recurrent state, b) a linear classifier to predict the class label, c) a Partial variational autoencoder to predict the features of unobserved regions. We use normalizing flows in Partial VAE to handle multi-modality in the feature-synthesis problem. We train our model using a differentiable objective and test it on five datasets. Our model gains 2-10% higher accuracy than the baseline models when both have seen only a couple of glimpses.