 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics-aware Adversarial Attack of Adaptive Neural Networks
Oct 15, 2022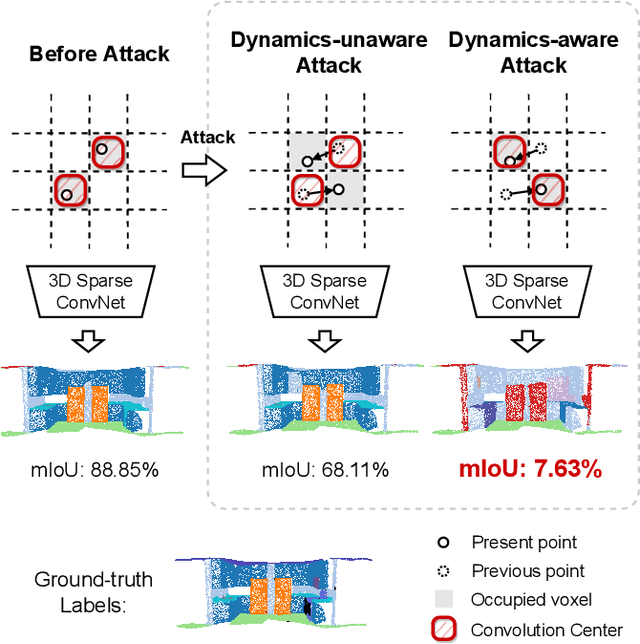



In this paper, we investigate the dynamics-aware adversarial attack problem of adaptive neural networks. Most existing adversarial attack algorithms are designed under a basic assumption -- the network architecture is fixed throughout the attack process. However, this assumption does not hold for many recently proposed adaptive neural networks, which adaptively deactivate unnecessary execution units based on inputs to improve computational efficiency. It results in a serious issue of lagged gradient, making the learned attack at the current step ineffective due to the architecture change afterward. To address this issue, we propose a Leaded Gradient Method (LGM) and show the significant effects of the lagged gradient. More specifically, we reformulate the gradients to be aware of the potential dynamic changes of network architectures, so that the learned attack better "leads" the next step than the dynamics-unaware methods when network architecture changes dynamically. Extensive experiments on representative types of adaptive neural networks for both 2D images and 3D point clouds show that our LGM achieves impressive adversarial attack performance compared with the dynamic-unaware attack methods.
Dynamics-aware Adversarial Attack of 3D Sparse Convolution Network
Dec 17, 2021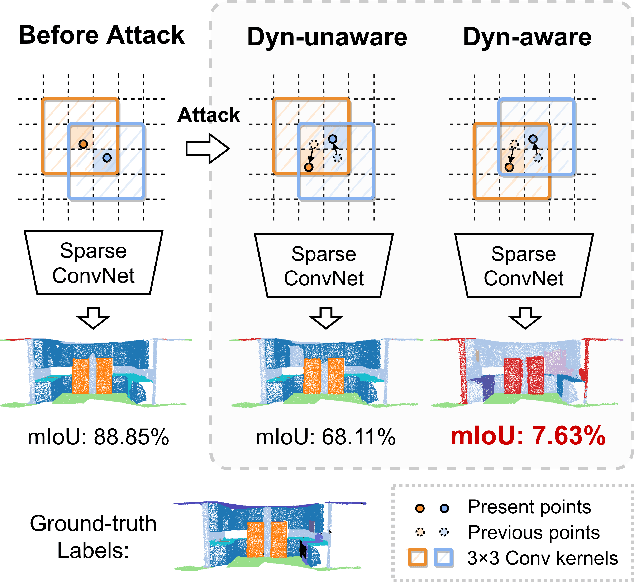

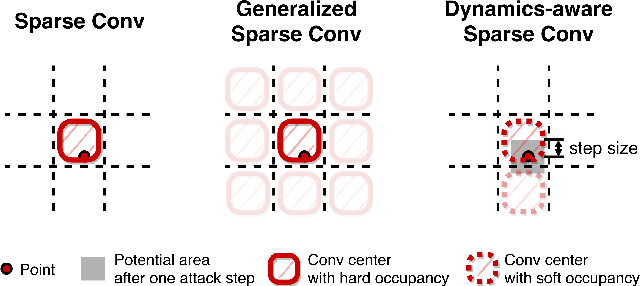
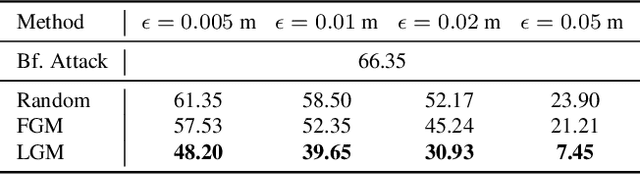
In this paper, we investigate the dynamics-aware adversarial attack problem in deep neural networks. Most existing adversarial attack algorithms are designed under a basic assumption -- the network architecture is fixed throughout the attack process. However, this assumption does not hold for many recently proposed networks, e.g. 3D sparse convolution network, which contains input-dependent execution to improve computational efficiency. It results in a serious issue of lagged gradient, making the learned attack at the current step ineffective due to the architecture changes afterward. To address this issue, we propose a Leaded Gradient Method (LGM) and show the significant effects of the lagged gradient. More specifically, we re-formulate the gradients to be aware of the potential dynamic changes of network architectures, so that the learned attack better "leads" the next step than the dynamics-unaware methods when network architecture changes dynamically. Extensive experiments on various datasets show that our LGM achieves impressive performance on semantic segmentation and classification. Compared with the dynamic-unaware methods, LGM achieves about 20% lower mIoU averagely on the ScanNet and S3DIS datasets. LGM also outperforms the recent point cloud attacks.
SegGroup: Seg-Level Supervision for 3D Instance and Semantic Segmentation
Dec 18, 2020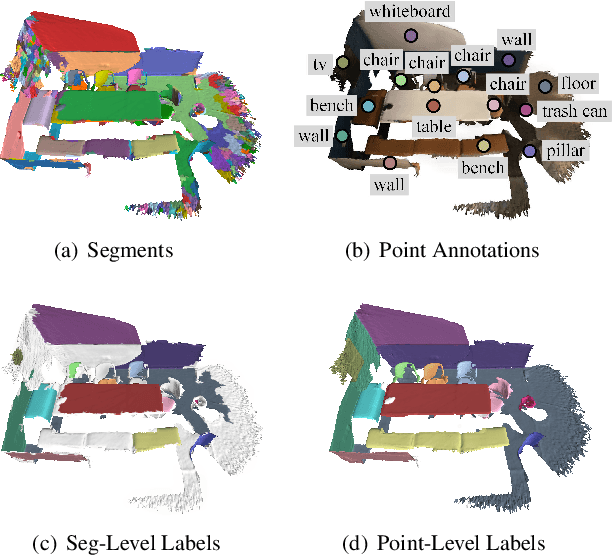

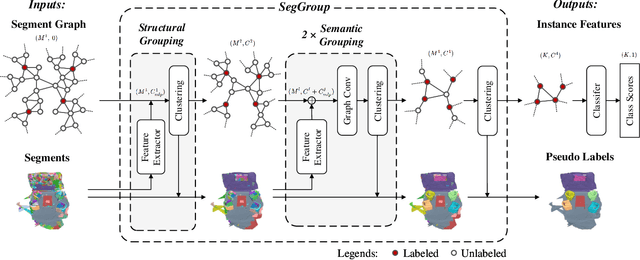
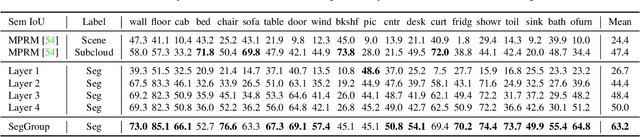
Most existing point cloud instance and semantic segmentation methods heavily rely on strong supervision signals, which require point-level labels for every point in the scene. However, strong supervision suffers from large annotation cost, arousing the need to study efficient annotating. In this paper, we propose a new form of weak supervision signal, namely seg-level labels, for point cloud instance and semantic segmentation. Based on the widely-used over-segmentation as pre-processor, we only annotate one point for each instance to obtain seg-level labels. We further design a segment grouping network (SegGroup) to generate pseudo point-level labels by hierarchically grouping the unlabeled segments into the relevant nearby labeled segments, so that existing methods can directly consume the pseudo labels for training. Experimental results show that our SegGroup achieves comparable results with the fully annotated point-level supervised methods on both point cloud instance and semantic segmentation tasks and outperforms the recent scene-level and subcloud-level supervised methods significantly.