 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
May 06, 2024
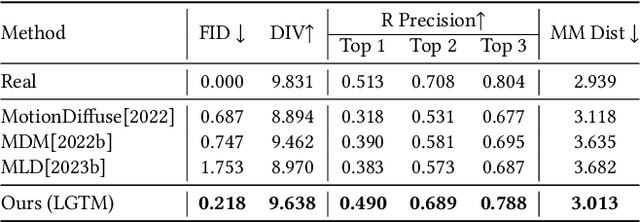

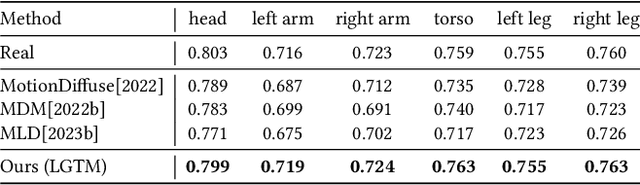
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM