 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025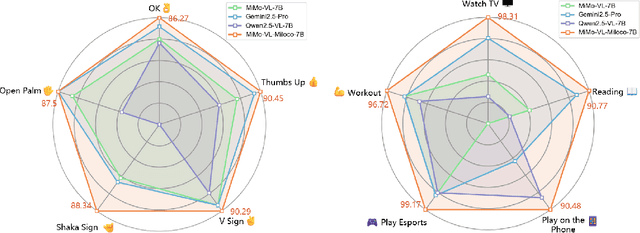
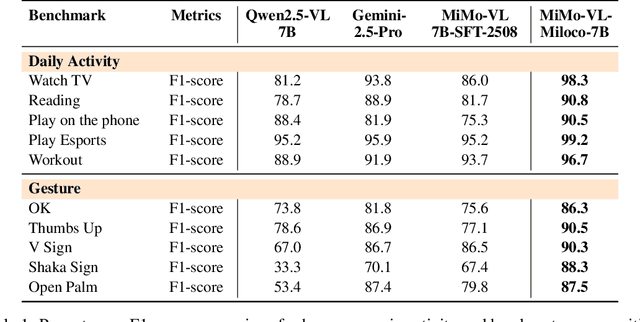

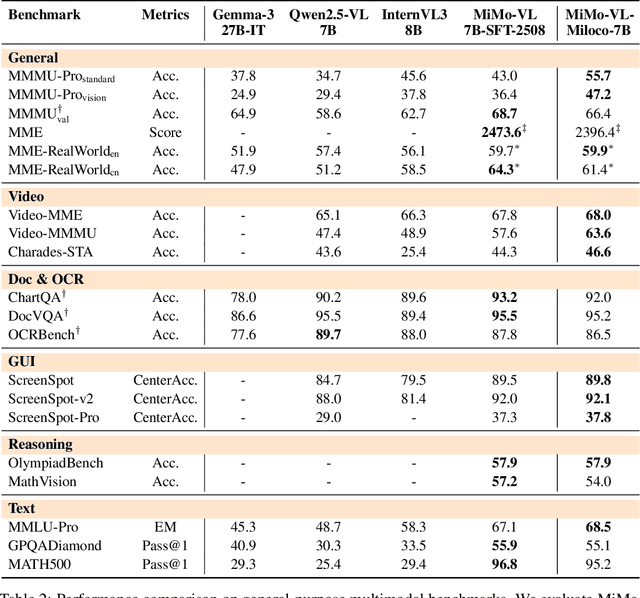
We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
MiniVLN: Efficient Vision-and-Language Navigation by Progressive Knowledge Distillation
Sep 27, 2024
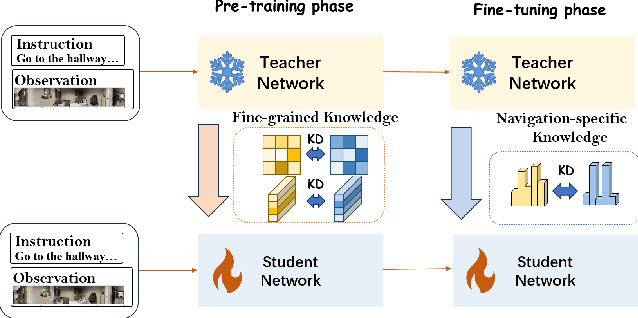

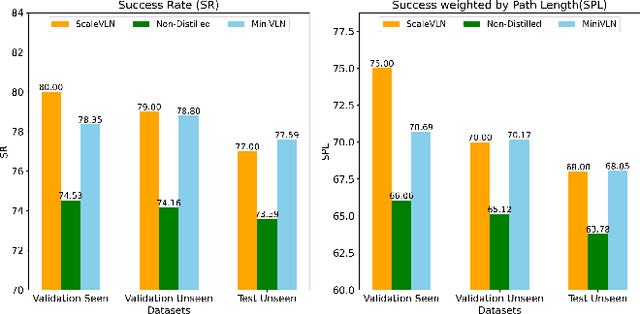
In recent years, Embodied Artificial Intelligence (Embodied AI) has advanced rapidly, yet the increasing size of models conflicts with the limited computational capabilities of Embodied AI platforms. To address this challenge, we aim to achieve both high model performance and practical deployability. Specifically, we focus on Vision-and-Language Navigation (VLN), a core task in Embodied AI. This paper introduces a two-stage knowledge distillation framework, producing a student model, MiniVLN, and showcasing the significant potential of distillation techniques in developing lightweight models. The proposed method aims to capture fine-grained knowledge during the pretraining phase and navigation-specific knowledge during the fine-tuning phase. Our findings indicate that the two-stage distillation approach is more effective in narrowing the performance gap between the teacher model and the student model compared to single-stage distillation. On the public R2R and REVERIE benchmarks, MiniVLN achieves performance on par with the teacher model while having only about 12% of the teacher model's parameter count.