 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolomonoff-Inspired Hypothesis Ranking with LLMs for Prediction Under Uncertainty
Dec 22, 2025



Reasoning under uncertainty is a key challenge in AI, especially for real-world tasks, where problems with sparse data demands systematic generalisation. Existing approaches struggle to balance accuracy and simplicity when evaluating multiple candidate solutions. We propose a Solomonoff-inspired method that weights LLM-generated hypotheses by simplicity and predictive fit. Applied to benchmark (Mini-ARC) tasks, our method produces Solomonoff-weighted mixtures for per-cell predictions, yielding conservative, uncertainty-aware outputs even when hypotheses are noisy or partially incorrect. Compared to Bayesian Model Averaging (BMA), Solomonoff scoring spreads probability more evenly across competing hypotheses, while BMA concentrates weight on the most likely but potentially flawed candidates. Across tasks, this highlights the value of algorithmic information-theoretic priors for interpretable, reliable multi-hypothesis reasoning under uncertainty.
QueryAdapter: Rapid Adaptation of Vision-Language Models in Response to Natural Language Queries
Feb 26, 2025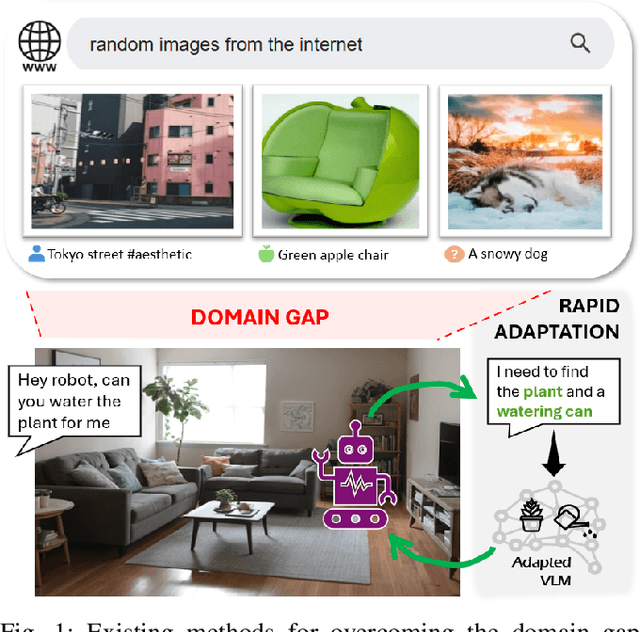


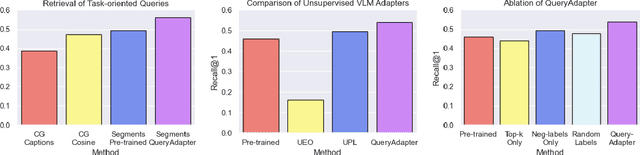
A domain shift exists between the large-scale, internet data used to train a Vision-Language Model (VLM) and the raw image streams collected by a robot. Existing adaptation strategies require the definition of a closed-set of classes, which is impractical for a robot that must respond to diverse natural language queries. In response, we present QueryAdapter; a novel framework for rapidly adapting a pre-trained VLM in response to a natural language query. QueryAdapter leverages unlabelled data collected during previous deployments to align VLM features with semantic classes related to the query. By optimising learnable prompt tokens and actively selecting objects for training, an adapted model can be produced in a matter of minutes. We also explore how objects unrelated to the query should be dealt with when using real-world data for adaptation. In turn, we propose the use of object captions as negative class labels, helping to produce better calibrated confidence scores during adaptation. Extensive experiments on ScanNet++ demonstrate that QueryAdapter significantly enhances object retrieval performance compared to state-of-the-art unsupervised VLM adapters and 3D scene graph methods. Furthermore, the approach exhibits robust generalization to abstract affordance queries and other datasets, such as Ego4D.
Enhancing Embodied Object Detection through Language-Image Pre-training and Implicit Object Memory
Feb 06, 2024Deep-learning and large scale language-image training have produced image object detectors that generalise well to diverse environments and semantic classes. However, single-image object detectors trained on internet data are not optimally tailored for the embodied conditions inherent in robotics. Instead, robots must detect objects from complex multi-modal data streams involving depth, localisation and temporal correlation, a task termed embodied object detection. Paradigms such as Video Object Detection (VOD) and Semantic Mapping have been proposed to leverage such embodied data streams, but existing work fails to enhance performance using language-image training. In response, we investigate how an image object detector pre-trained using language-image data can be extended to perform embodied object detection. We propose a novel implicit object memory that uses projective geometry to aggregate the features of detected objects across long temporal horizons. The spatial and temporal information accumulated in memory is then used to enhance the image features of the base detector. When tested on embodied data streams sampled from diverse indoor scenes, our approach improves the base object detector by 3.09 mAP, outperforming alternative external memories designed for VOD and Semantic Mapping. Our method also shows a significant improvement of 16.90 mAP relative to baselines that perform embodied object detection without first training on language-image data, and is robust to sensor noise and domain shift experienced in real-world deployment.
Predicting Class Distribution Shift for Reliable Domain Adaptive Object Detection
Feb 13, 2023



Unsupervised Domain Adaptive Object Detection (UDA-OD) uses unlabelled data to improve the reliability of robotic vision systems in open-world environments. Previous approaches to UDA-OD based on self-training have been effective in overcoming changes in the general appearance of images. However, shifts in a robot's deployment environment can also impact the likelihood that different objects will occur, termed class distribution shift. Motivated by this, we propose a framework for explicitly addressing class distribution shift to improve pseudo-label reliability in self-training. Our approach uses the domain invariance and contextual understanding of a pre-trained joint vision and language model to predict the class distribution of unlabelled data. By aligning the class distribution of pseudo-labels with this prediction, we provide weak supervision of pseudo-label accuracy. To further account for low quality pseudo-labels early in self-training, we propose an approach to dynamically adjust the number of pseudo-labels per image based on model confidence. Our method outperforms state-of-the-art approaches on several benchmarks, including a 4.7 mAP improvement when facing challenging class distribution shift.