 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraSP-VLA: Graph-based Symbolic Action Representation for Long-Horizon Planning with VLA Policies
Nov 06, 2025Deploying autonomous robots that can learn new skills from demonstrations is an important challenge of modern robotics. Existing solutions often apply end-to-end imitation learning with Vision-Language Action (VLA) models or symbolic approaches with Action Model Learning (AML). On the one hand, current VLA models are limited by the lack of high-level symbolic planning, which hinders their abilities in long-horizon tasks. On the other hand, symbolic approaches in AML lack generalization and scalability perspectives. In this paper we present a new neuro-symbolic approach, GraSP-VLA, a framework that uses a Continuous Scene Graph representation to generate a symbolic representation of human demonstrations. This representation is used to generate new planning domains during inference and serves as an orchestrator for low-level VLA policies, scaling up the number of actions that can be reproduced in a row. Our results show that GraSP-VLA is effective for modeling symbolic representations on the task of automatic planning domain generation from observations. In addition, results on real-world experiments show the potential of our Continuous Scene Graph representation to orchestrate low-level VLA policies in long-horizon tasks.
Real-Time Scene Graph Generation
May 25, 2024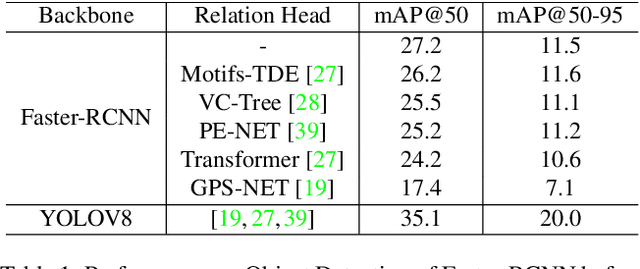



Scene Graph Generation (SGG) can extract abstract semantic relations between entities in images as graph representations. This task holds strong promises for other downstream tasks such as the embodied cognition of an autonomous agent. However, to power such applications, SGG needs to solve the gap of real-time latency. In this work, we propose to investigate the bottlenecks of current approaches for real-time constraint applications. Then, we propose a simple yet effective implementation of a real-time SGG approach using YOLOV8 as an object detection backbone. Our implementation is the first to obtain more than 48 FPS for the task with no loss of accuracy, successfully outperforming any other lightweight approaches. Our code is freely available at https://github.com/Maelic/SGG-Benchmark.
Fine-Grained is Too Coarse: A Novel Data-Centric Approach for Efficient Scene Graph Generation
May 30, 2023



Learning to compose visual relationships from raw images in the form of scene graphs is a highly challenging task due to contextual dependencies, but it is essential in computer vision applications that depend on scene understanding. However, no current approaches in Scene Graph Generation (SGG) aim at providing useful graphs for downstream tasks. Instead, the main focus has primarily been on the task of unbiasing the data distribution for predicting more fine-grained relations. That being said, all fine-grained relations are not equally relevant and at least a part of them are of no use for real-world applications. In this work, we introduce the task of Efficient SGG that prioritizes the generation of relevant relations, facilitating the use of Scene Graphs in downstream tasks such as Image Generation. To support further approaches in this task, we present a new dataset, VG150-curated, based on the annotations of the popular Visual Genome dataset. We show through a set of experiments that this dataset contains more high-quality and diverse annotations than the one usually adopted by approaches in SGG. Finally, we show the efficiency of this dataset in the task of Image Generation from Scene Graphs. Our approach can be easily replicated to improve the quality of other Scene Graph Generation datasets.
Interactive Machine Learning: A State of the Art Review
Jul 13, 2022
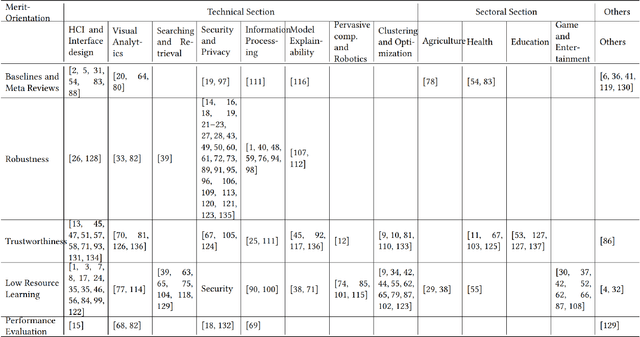
Machine learning has proved useful in many software disciplines, including computer vision, speech and audio processing, natural language processing, robotics and some other fields. However, its applicability has been significantly hampered due its black-box nature and significant resource consumption. Performance is achieved at the expense of enormous computational resource and usually compromising the robustness and trustworthiness of the model. Recent researches have been identifying a lack of interactivity as the prime source of these machine learning problems. Consequently, interactive machine learning (iML) has acquired increased attention of researchers on account of its human-in-the-loop modality and relatively efficient resource utilization. Thereby, a state-of-the-art review of interactive machine learning plays a vital role in easing the effort toward building human-centred models. In this paper, we provide a comprehensive analysis of the state-of-the-art of iML. We analyze salient research works using merit-oriented and application/task oriented mixed taxonomy. We use a bottom-up clustering approach to generate a taxonomy of iML research works. Research works on adversarial black-box attacks and corresponding iML based defense system, exploratory machine learning, resource constrained learning, and iML performance evaluation are analyzed under their corresponding theme in our merit-oriented taxonomy. We have further classified these research works into technical and sectoral categories. Finally, research opportunities that we believe are inspiring for future work in iML are discussed thoroughly.
Commonsense Reasoning for Identifying and Understanding the Implicit Need of Help and Synthesizing Assistive Actions
Feb 23, 2022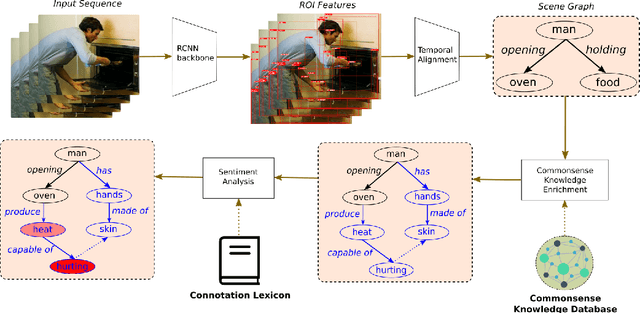
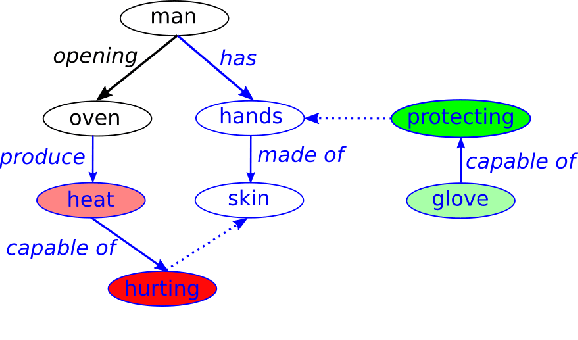
Human-Robot Interaction (HRI) is an emerging subfield of service robotics. While most existing approaches rely on explicit signals (i.e. voice, gesture) to engage, current literature is lacking solutions to address implicit user needs. In this paper, we present an architecture to (a) detect user implicit need of help and (b) generate a set of assistive actions without prior learning. Task (a) will be performed using state-of-the-art solutions for Scene Graph Generation coupled to the use of commonsense knowledge; whereas, task (b) will be performed using additional commonsense knowledge as well as a sentiment analysis on graph structure. Finally, we propose an evaluation of our solution using established benchmarks (e.g. ActionGenome dataset) along with human experiments. The main motivation of our approach is the embedding of the perception-decision-action loop in a single architecture.
Robots Learn Increasingly Complex Tasks with Intrinsic Motivation and Automatic Curriculum Learning
Feb 11, 2022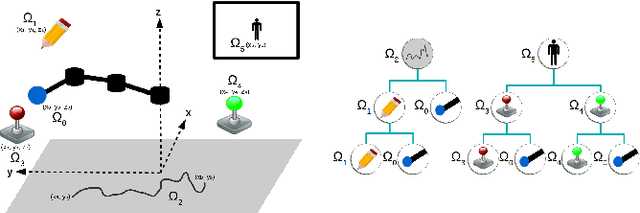
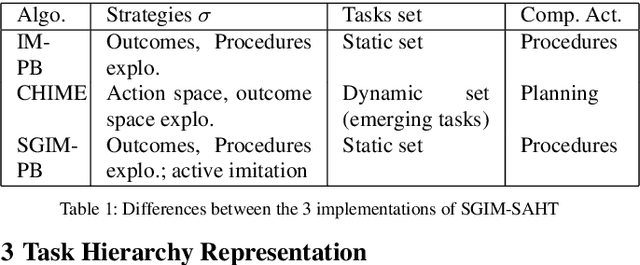

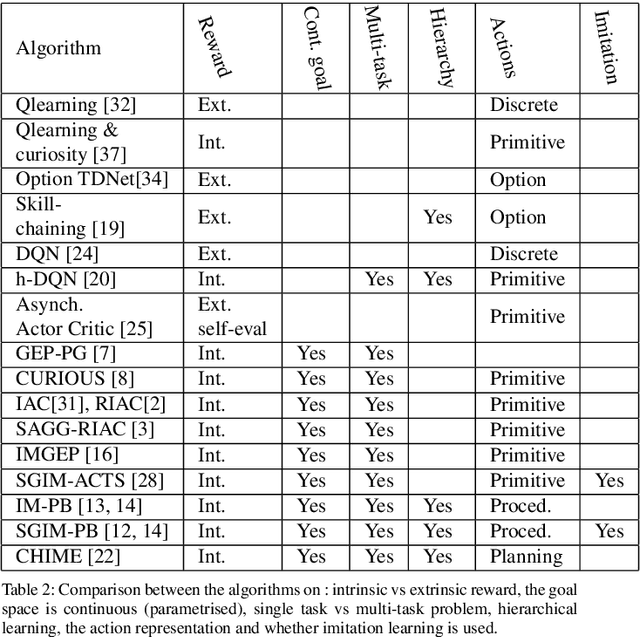
Multi-task learning by robots poses the challenge of the domain knowledge: complexity of tasks, complexity of the actions required, relationship between tasks for transfer learning. We demonstrate that this domain knowledge can be learned to address the challenges in life-long learning. Specifically, the hierarchy between tasks of various complexities is key to infer a curriculum from simple to composite tasks. We propose a framework for robots to learn sequences of actions of unbounded complexity in order to achieve multiple control tasks of various complexity. Our hierarchical reinforcement learning framework, named SGIM-SAHT, offers a new direction of research, and tries to unify partial implementations on robot arms and mobile robots. We outline our contributions to enable robots to map multiple control tasks to sequences of actions: representations of task dependencies, an intrinsically motivated exploration to learn task hierarchies, and active imitation learning. While learning the hierarchy of tasks, it infers its curriculum by deciding which tasks to explore first, how to transfer knowledge, and when, how and whom to imitate.
RoboCup@Home Education 2020 Best Performance: RoboBreizh, a modular approach
Jul 07, 2021


Every year, the Robocup@Home competition challenges teams and robots' abilities. In 2020, the RoboCup@Home Education challenge was organized online, altering the usual competition rules. In this paper, we present the latest developments that lead the RoboBreizh team to win the contest. These developments include several modules linked to each other allowing the Pepper robot to understand, act and adapt itself to a local environment. Up-to-date available technologies have been used for navigation and dialogue. First contribution includes combining object detection and pose estimation techniques to detect user's intention. Second contribution involves using Learning by Demonstrations to easily learn new movements that improve the Pepper robot's skills. This proposal won the best performance award of the 2020 RoboCup@Home Education challenge.
Hierarchical Affordance Discovery using Intrinsic Motivation
Sep 23, 2020

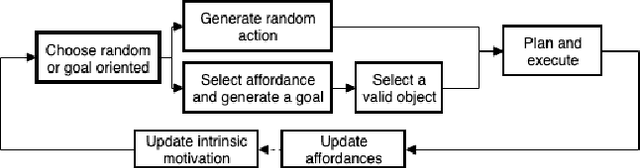

To be capable of lifelong learning in a real-life environment, robots have to tackle multiple challenges. Being able to relate physical properties they may observe in their environment to possible interactions they may have is one of them. This skill, named affordance learning, is strongly related to embodiment and is mastered through each person's development: each individual learns affordances differently through their own interactions with their surroundings. Current methods for affordance learning usually use either fixed actions to learn these affordances or focus on static setups involving a robotic arm to be operated. In this article, we propose an algorithm using intrinsic motivation to guide the learning of affordances for a mobile robot. This algorithm is capable to autonomously discover, learn and adapt interrelated affordances without pre-programmed actions. Once learned, these affordances may be used by the algorithm to plan sequences of actions in order to perform tasks of various difficulties. We then present one experiment and analyse our system before comparing it with other approaches from reinforcement learning and affordance learning.
Towards A Theory-Of-Mind-Inspired Generic Decision-Making Framework
May 20, 2014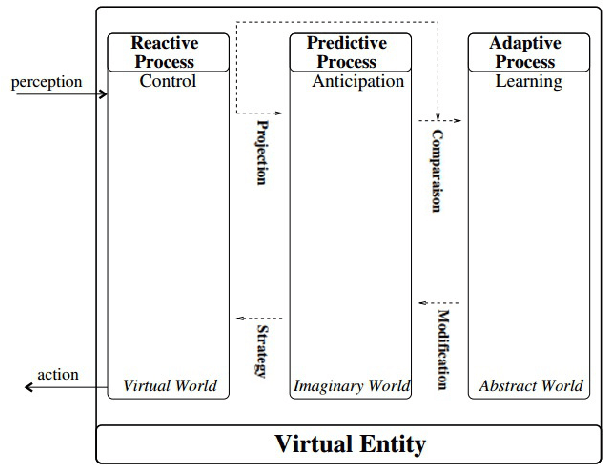
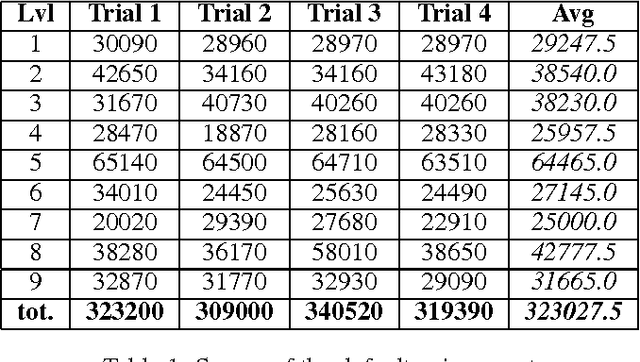
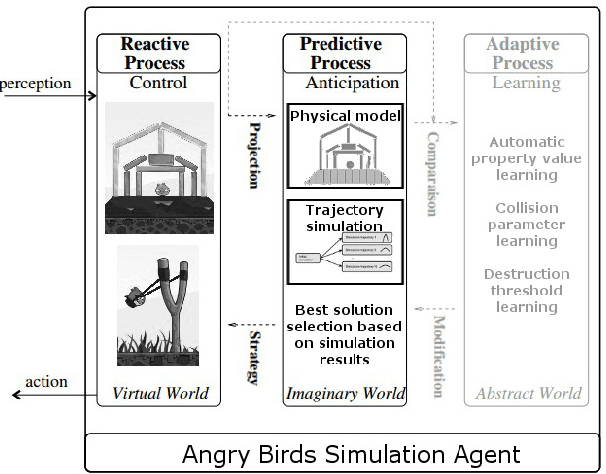
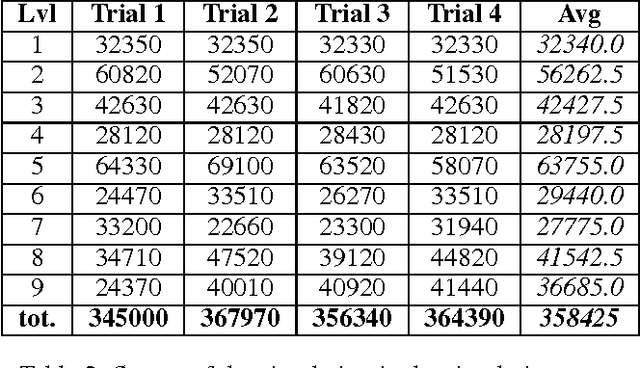
Simulation is widely used to make model-based predictions, but few approaches have attempted this technique in dynamic physical environments of medium to high complexity or in general contexts. After an introduction to the cognitive science concepts from which this work is inspired and the current development in the use of simulation as a decision-making technique, we propose a generic framework based on theory of mind, which allows an agent to reason and perform actions using multiple simulations of automatically created or externally inputted models of the perceived environment. A description of a partial implementation is given, which aims to solve a popular game within the IJCAI2013 AIBirds contest. Results of our approach are presented, in comparison with the competition benchmark. Finally, future developments regarding the framework are discussed.
Learning a Representation of a Believable Virtual Character's Environment with an Imitation Algorithm
Dec 29, 2010
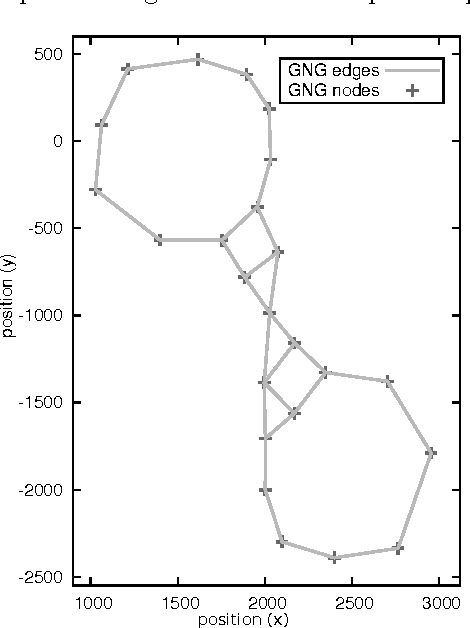
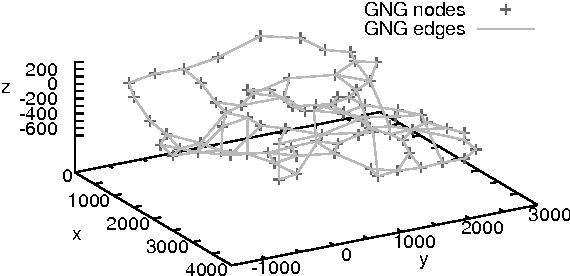
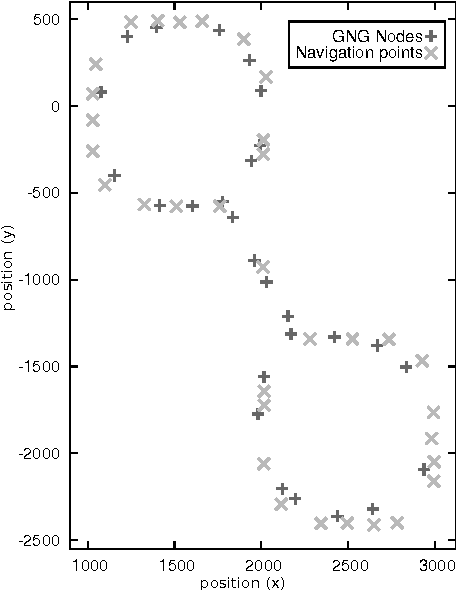
In video games, virtual characters' decision systems often use a simplified representation of the world. To increase both their autonomy and believability we want those characters to be able to learn this representation from human players. We propose to use a model called growing neural gas to learn by imitation the topology of the environment. The implementation of the model, the modifications and the parameters we used are detailed. Then, the quality of the learned representations and their evolution during the learning are studied using different measures. Improvements for the growing neural gas to give more information to the character's model are given in the conclusion.