 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots Learn Increasingly Complex Tasks with Intrinsic Motivation and Automatic Curriculum Learning
Feb 11, 2022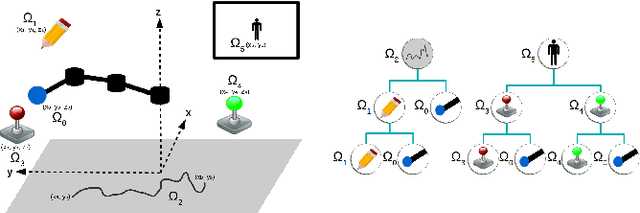
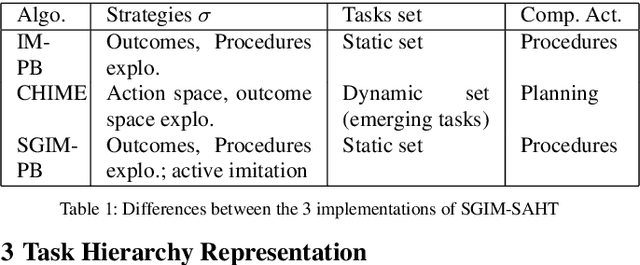

Multi-task learning by robots poses the challenge of the domain knowledge: complexity of tasks, complexity of the actions required, relationship between tasks for transfer learning. We demonstrate that this domain knowledge can be learned to address the challenges in life-long learning. Specifically, the hierarchy between tasks of various complexities is key to infer a curriculum from simple to composite tasks. We propose a framework for robots to learn sequences of actions of unbounded complexity in order to achieve multiple control tasks of various complexity. Our hierarchical reinforcement learning framework, named SGIM-SAHT, offers a new direction of research, and tries to unify partial implementations on robot arms and mobile robots. We outline our contributions to enable robots to map multiple control tasks to sequences of actions: representations of task dependencies, an intrinsically motivated exploration to learn task hierarchies, and active imitation learning. While learning the hierarchy of tasks, it infers its curriculum by deciding which tasks to explore first, how to transfer knowledge, and when, how and whom to imitate.
Intrinsically Motivated Open-Ended Multi-Task Learning Using Transfer Learning to Discover Task Hierarchy
Feb 19, 2021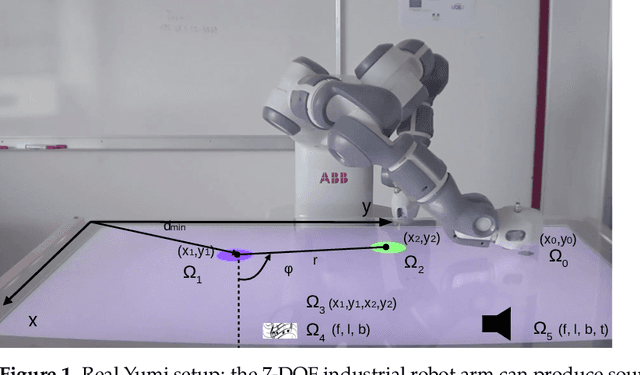


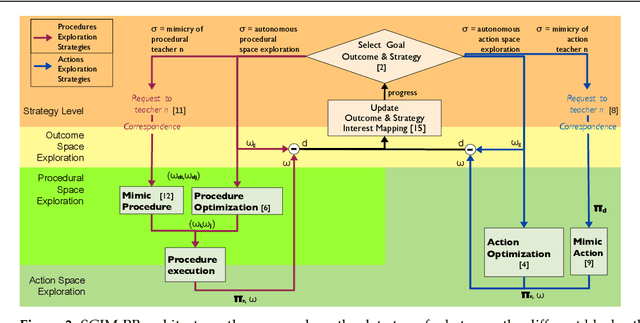
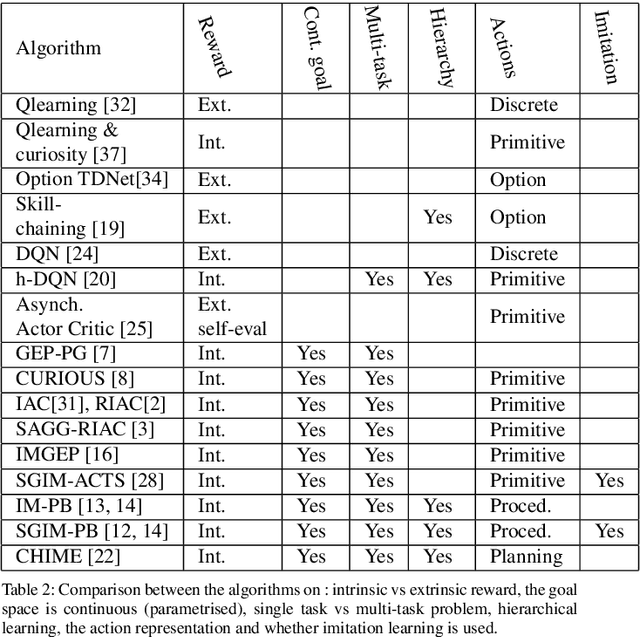
In open-ended continuous environments, robots need to learn multiple parameterised control tasks in hierarchical reinforcement learning. We hypothesise that the most complex tasks can be learned more easily by transferring knowledge from simpler tasks, and faster by adapting the complexity of the actions to the task. We propose a task-oriented representation of complex actions, called procedures, to learn online task relationships and unbounded sequences of action primitives to control the different observables of the environment. Combining both goal-babbling with imitation learning, and active learning with transfer of knowledge based on intrinsic motivation, our algorithm self-organises its learning process. It chooses at any given time a task to focus on; and what, how, when and from whom to transfer knowledge. We show with a simulation and a real industrial robot arm, in cross-task and cross-learner transfer settings, that task composition is key to tackle highly complex tasks. Task decomposition is also efficiently transferred across different embodied learners and by active imitation, where the robot requests just a small amount of demonstrations and the adequate type of information. The robot learns and exploits task dependencies so as to learn tasks of every complexity.
Learning a Set of Interrelated Tasks by Using Sequences of Motor Policies for a Strategic Intrinsically Motivated Learner
Feb 14, 2019



We propose an active learning architecture for robots, capable of organizing its learning process to achieve a field of complex tasks by learning sequences of motor policies, called Intrinsically Motivated Procedure Babbling (IM-PB). The learner can generalize over its experience to continuously learn new tasks. It chooses actively what and how to learn based by empirical measures of its own progress. In this paper, we are considering the learning of a set of interrelated tasks outcomes hierarchically organized. We introduce a framework called 'procedures', which are sequences of policies defined by the combination of previously learned skills. Our algorithmic architecture uses the procedures to autonomously discover how to combine simple skills to achieve complex goals. It actively chooses between 2 strategies of goal-directed exploration : exploration of the policy space or the procedural space. We show on a simulated environment that our new architecture is capable of tackling the learning of complex motor policies, to adapt the complexity of its policies to the task at hand. We also show that our 'procedures' framework helps the learner to tackle difficult hierarchical tasks.
Study of the Importance of Adequacy to Robot Verbal and Non Verbal Communication in Human-Robot interaction
Jun 14, 2012



The Robadom project aims at creating a homecare robot that help and assist people in their daily life, either in doing task for the human or in managing day organization. A robot could have this kind of role only if it is accepted by humans. Before thinking about the robot appearance, we decided to evaluate the importance of the relation between verbal and nonverbal communication during a human-robot interaction in order to determine the situation where the robot is accepted. We realized two experiments in order to study this acceptance. The first experiment studied the importance of having robot nonverbal behavior in relation of its verbal behavior. The second experiment studied the capability of a robot to provide a correct human-robot interaction.