 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstracting Geo-specific Terrains to Scale Up Reinforcement Learning
Mar 25, 2025Multi-agent reinforcement learning (MARL) is increasingly ubiquitous in training dynamic and adaptive synthetic characters for interactive simulations on geo-specific terrains. Frameworks such as Unity's ML-Agents help to make such reinforcement learning experiments more accessible to the simulation community. Military training simulations also benefit from advances in MARL, but they have immense computational requirements due to their complex, continuous, stochastic, partially observable, non-stationary, and doctrine-based nature. Furthermore, these simulations require geo-specific terrains, further exacerbating the computational resources problem. In our research, we leverage Unity's waypoints to automatically generate multi-layered representation abstractions of the geo-specific terrains to scale up reinforcement learning while still allowing the transfer of learned policies between different representations. Our early exploratory results on a novel MARL scenario, where each side has differing objectives, indicate that waypoint-based navigation enables faster and more efficient learning while producing trajectories similar to those taken by expert human players in CSGO gaming environments. This research points out the potential of waypoint-based navigation for reducing the computational costs of developing and training MARL models for military training simulations, where geo-specific terrains and differing objectives are crucial.
Adaptive Synthetic Characters for Military Training
Jan 06, 2021
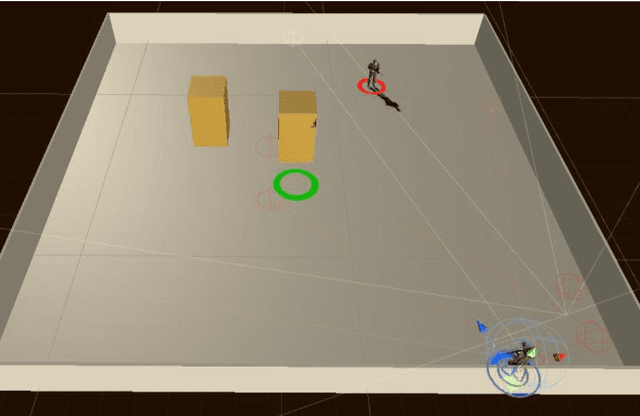
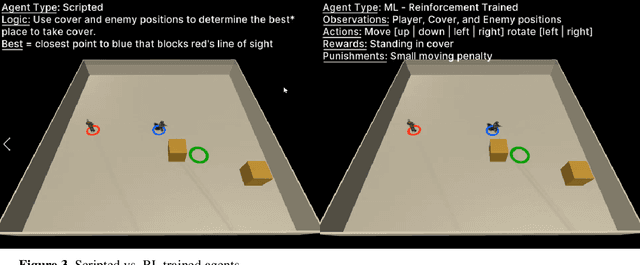
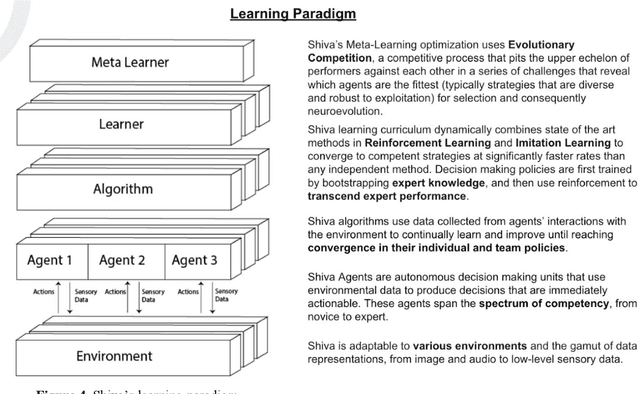
Behaviors of the synthetic characters in current military simulations are limited since they are generally generated by rule-based and reactive computational models with minimal intelligence. Such computational models cannot adapt to reflect the experience of the characters, resulting in brittle intelligence for even the most effective behavior models devised via costly and labor-intensive processes. Observation-based behavior model adaptation that leverages machine learning and the experience of synthetic entities in combination with appropriate prior knowledge can address the issues in the existing computational behavior models to create a better training experience in military training simulations. In this paper, we introduce a framework that aims to create autonomous synthetic characters that can perform coherent sequences of believable behavior while being aware of human trainees and their needs within a training simulation. This framework brings together three mutually complementary components. The first component is a Unity-based simulation environment - Rapid Integration and Development Environment (RIDE) - supporting One World Terrain (OWT) models and capable of running and supporting machine learning experiments. The second is Shiva, a novel multi-agent reinforcement and imitation learning framework that can interface with a variety of simulation environments, and that can additionally utilize a variety of learning algorithms. The final component is the Sigma Cognitive Architecture that will augment the behavior models with symbolic and probabilistic reasoning capabilities. We have successfully created proof-of-concept behavior models leveraging this framework on realistic terrain as an essential step towards bringing machine learning into military simulations.