 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias after Prompting: Persistent Discrimination in Large Language Models
Sep 09, 2025A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.
ODKE+: Ontology-Guided Open-Domain Knowledge Extraction with LLMs
Sep 04, 2025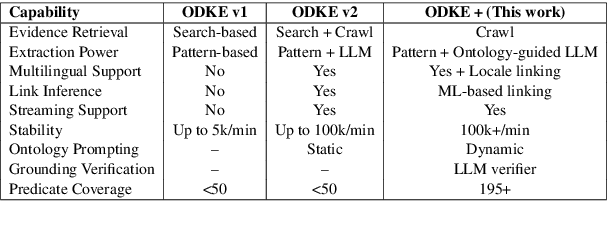
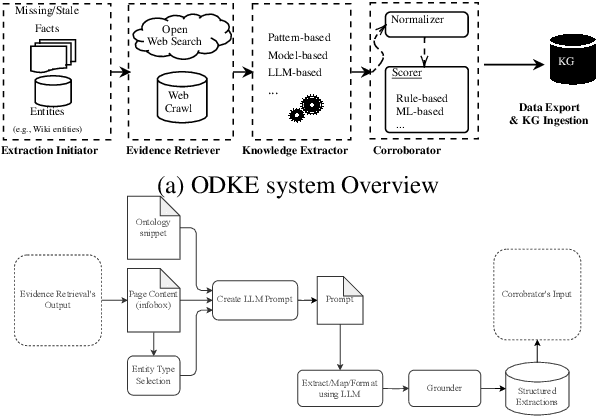
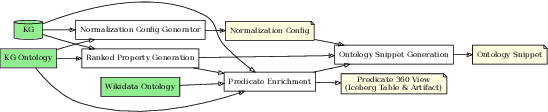

Knowledge graphs (KGs) are foundational to many AI applications, but maintaining their freshness and completeness remains costly. We present ODKE+, a production-grade system that automatically extracts and ingests millions of open-domain facts from web sources with high precision. ODKE+ combines modular components into a scalable pipeline: (1) the Extraction Initiator detects missing or stale facts, (2) the Evidence Retriever collects supporting documents, (3) hybrid Knowledge Extractors apply both pattern-based rules and ontology-guided prompting for large language models (LLMs), (4) a lightweight Grounder validates extracted facts using a second LLM, and (5) the Corroborator ranks and normalizes candidate facts for ingestion. ODKE+ dynamically generates ontology snippets tailored to each entity type to align extractions with schema constraints, enabling scalable, type-consistent fact extraction across 195 predicates. The system supports batch and streaming modes, processing over 9 million Wikipedia pages and ingesting 19 million high-confidence facts with 98.8% precision. ODKE+ significantly improves coverage over traditional methods, achieving up to 48% overlap with third-party KGs and reducing update lag by 50 days on average. Our deployment demonstrates that LLM-based extraction, grounded in ontological structure and verification workflows, can deliver trustworthiness, production-scale knowledge ingestion with broad real-world applicability. A recording of the system demonstration is included with the submission and is also available at https://youtu.be/UcnE3_GsTWs.
Evaluating Gender Bias Transfer between Pre-trained and Prompt-Adapted Language Models
Dec 04, 2024Large language models (LLMs) are increasingly being adapted to achieve task-specificity for deployment in real-world decision systems. Several previous works have investigated the bias transfer hypothesis (BTH) by studying the effect of the fine-tuning adaptation strategy on model fairness to find that fairness in pre-trained masked language models have limited effect on the fairness of models when adapted using fine-tuning. In this work, we expand the study of BTH to causal models under prompt adaptations, as prompting is an accessible, and compute-efficient way to deploy models in real-world systems. In contrast to previous works, we establish that intrinsic biases in pre-trained Mistral, Falcon and Llama models are strongly correlated (rho >= 0.94) with biases when the same models are zero- and few-shot prompted, using a pronoun co-reference resolution task. Further, we find that bias transfer remains strongly correlated even when LLMs are specifically prompted to exhibit fair or biased behavior (rho >= 0.92), and few-shot length and stereotypical composition are varied (rho >= 0.97). Our findings highlight the importance of ensuring fairness in pre-trained LLMs, especially when they are later used to perform downstream tasks via prompt adaptation.
APE: Active Learning-based Tooling for Finding Informative Few-shot Examples for LLM-based Entity Matching
Jul 29, 2024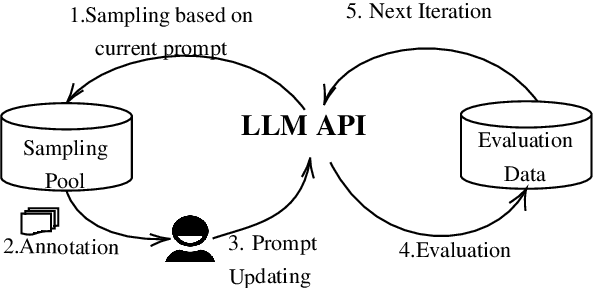
Prompt engineering is an iterative procedure often requiring extensive manual effort to formulate suitable instructions for effectively directing large language models (LLMs) in specific tasks. Incorporating few-shot examples is a vital and effective approach to providing LLMs with precise instructions, leading to improved LLM performance. Nonetheless, identifying the most informative demonstrations for LLMs is labor-intensive, frequently entailing sifting through an extensive search space. In this demonstration, we showcase a human-in-the-loop tool called APE (Active Prompt Engineering) designed for refining prompts through active learning. Drawing inspiration from active learning, APE iteratively selects the most ambiguous examples for human feedback, which will be transformed into few-shot examples within the prompt. The demo recording can be found with the submission or be viewed at https://youtu.be/OwQ6MQx53-Y.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023
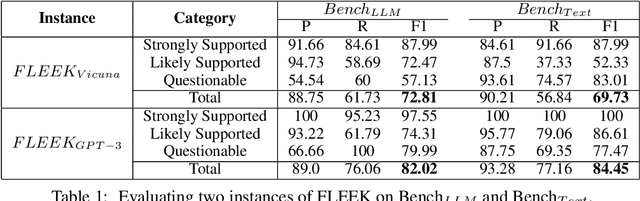
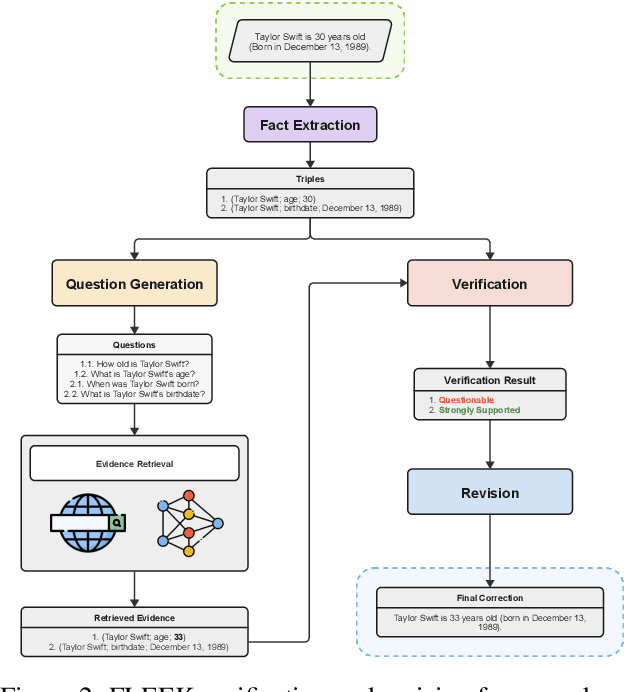
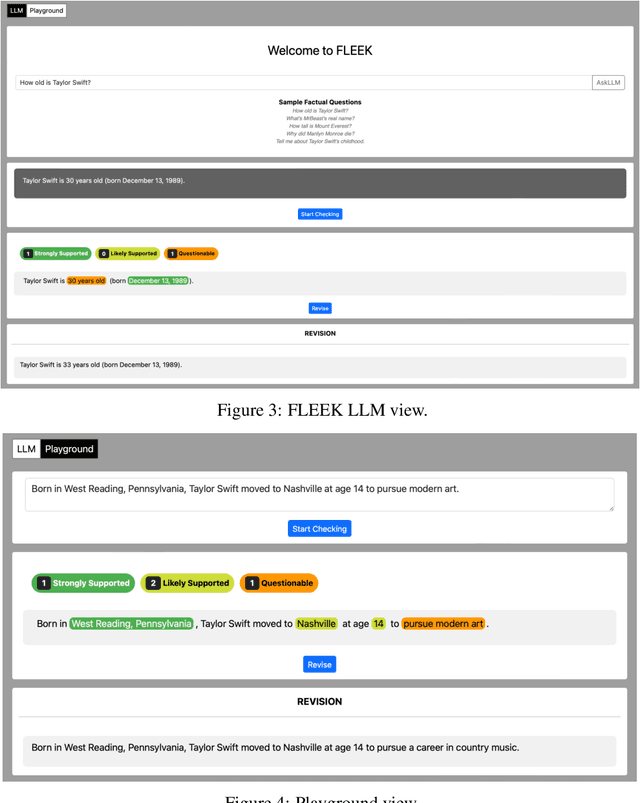
Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.