 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRENDy: Temporal Regression of Effective Non-linear Dynamics
Dec 04, 2024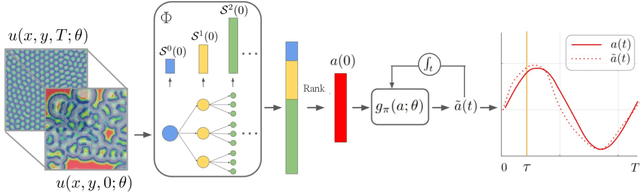
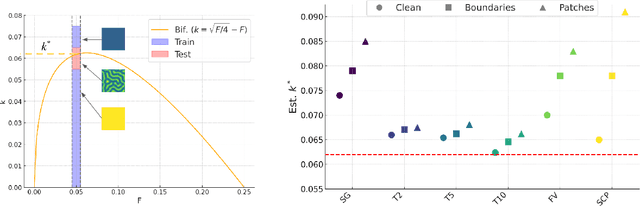
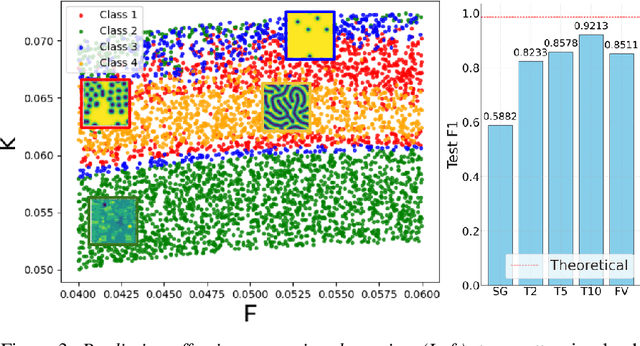
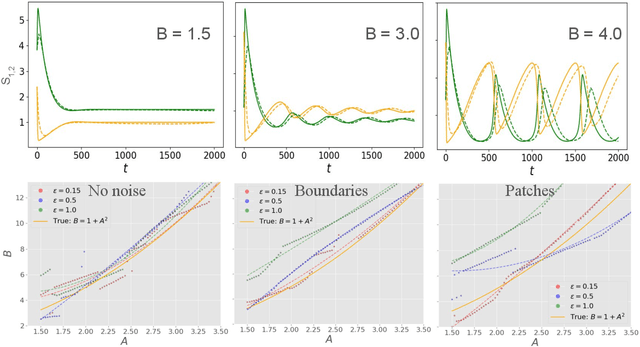
Spatiotemporal dynamics pervade the natural sciences, from the morphogen dynamics underlying patterning in animal pigmentation to the protein waves controlling cell division. A central challenge lies in understanding how controllable parameters induce qualitative changes in system behavior called bifurcations. This endeavor is made particularly difficult in realistic settings where governing partial differential equations (PDEs) are unknown and data is limited and noisy. To address this challenge, we propose TRENDy (Temporal Regression of Effective Nonlinear Dynamics), an equation-free approach to learning low-dimensional, predictive models of spatiotemporal dynamics. Following classical work in spatial coarse-graining, TRENDy first maps input data to a low-dimensional space of effective dynamics via a cascade of multiscale filtering operations. Our key insight is the recognition that these effective dynamics can be fit by a neural ordinary differential equation (NODE) having the same parameter space as the input PDE. The preceding filtering operations strongly regularize the phase space of the NODE, making TRENDy significantly more robust to noise compared to existing methods. We train TRENDy to predict the effective dynamics of synthetic and real data representing dynamics from across the physical and life sciences. We then demonstrate how our framework can automatically locate both Turing and Hopf bifurcations in unseen regions of parameter space. We finally apply our method to the analysis of spatial patterning of the ocellated lizard through development. We found that TRENDy's effective state not only accurately predicts spatial changes over time but also identifies distinct pattern features unique to different anatomical regions, highlighting the potential influence of surface geometry on reaction-diffusion mechanisms and their role in driving spatially varying pattern dynamics.
Contrasting Multiple Representations with the Multi-Marginal Matching Gap
May 29, 2024



Learning meaningful representations of complex objects that can be seen through multiple ($k\geq 3$) views or modalities is a core task in machine learning. Existing methods use losses originally intended for paired views, and extend them to $k$ views, either by instantiating $\tfrac12k(k-1)$ loss-pairs, or by using reduced embeddings, following a \textit{one vs. average-of-rest} strategy. We propose the multi-marginal matching gap (M3G), a loss that borrows tools from multi-marginal optimal transport (MM-OT) theory to simultaneously incorporate all $k$ views. Given a batch of $n$ points, each seen as a $k$-tuple of views subsequently transformed into $k$ embeddings, our loss contrasts the cost of matching these $n$ ground-truth $k$-tuples with the MM-OT polymatching cost, which seeks $n$ optimally arranged $k$-tuples chosen within these $n\times k$ vectors. While the exponential complexity $O(n^k$) of the MM-OT problem may seem daunting, we show in experiments that a suitable generalization of the Sinkhorn algorithm for that problem can scale to, e.g., $k=3\sim 6$ views using mini-batches of size $64~\sim128$. Our experiments demonstrate improved performance over multiview extensions of pairwise losses, for both self-supervised and multimodal tasks.
Phase2vec: Dynamical systems embedding with a physics-informed convolutional network
Dec 07, 2022



Dynamical systems are found in innumerable forms across the physical and biological sciences, yet all these systems fall naturally into universal equivalence classes: conservative or dissipative, stable or unstable, compressible or incompressible. Predicting these classes from data remains an essential open challenge in computational physics at which existing time-series classification methods struggle. Here, we propose, \texttt{phase2vec}, an embedding method that learns high-quality, physically-meaningful representations of 2D dynamical systems without supervision. Our embeddings are produced by a convolutional backbone that extracts geometric features from flow data and minimizes a physically-informed vector field reconstruction loss. In an auxiliary training period, embeddings are optimized so that they robustly encode the equations of unseen data over and above the performance of a per-equation fitting method. The trained architecture can not only predict the equations of unseen data, but also, crucially, learns embeddings that respect the underlying semantics of the embedded physical systems. We validate the quality of learned embeddings investigating the extent to which physical categories of input data can be decoded from embeddings compared to standard blackbox classifiers and state-of-the-art time series classification techniques. We find that our embeddings encode important physical properties of the underlying data, including the stability of fixed points, conservation of energy, and the incompressibility of flows, with greater fidelity than competing methods. We finally apply our embeddings to the analysis of meteorological data, showing we can detect climatically meaningful features. Collectively, our results demonstrate the viability of embedding approaches for the discovery of dynamical features in physical systems.
The Dual Information Bottleneck
Jun 08, 2020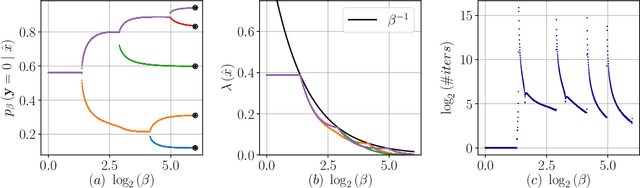
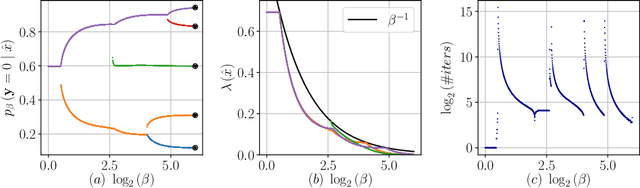
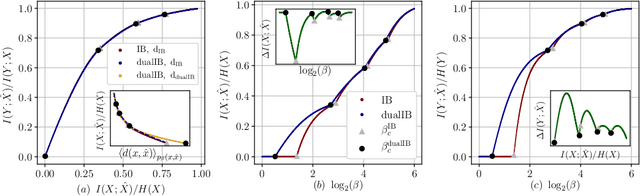

The Information Bottleneck (IB) framework is a general characterization of optimal representations obtained using a principled approach for balancing accuracy and complexity. Here we present a new framework, the Dual Information Bottleneck (dualIB), which resolves some of the known drawbacks of the IB. We provide a theoretical analysis of the dualIB framework; (i) solving for the structure of its solutions (ii) unraveling its superiority in optimizing the mean prediction error exponent and (iii) demonstrating its ability to preserve exponential forms of the original distribution. To approach large scale problems, we present a novel variational formulation of the dualIB for Deep Neural Networks. In experiments on several data-sets, we compare it to a variational form of the IB. This exposes superior Information Plane properties of the dualIB and its potential in improvement of the error.