 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Policy Gradients: Direct Optimization of Policies in Discrete Action Spaces
Paper and Code
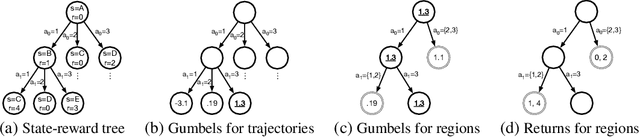
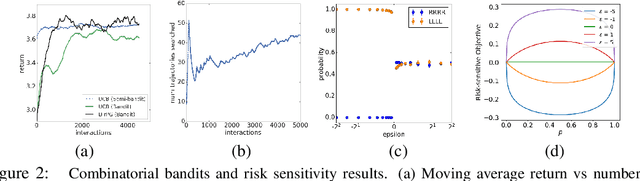
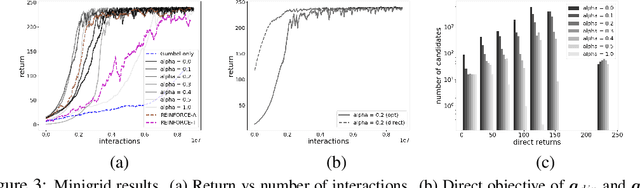
Direct optimization is an appealing approach to differentiating through discrete quantities. Rather than relying on REINFORCE or continuous relaxations of discrete structures, it uses optimization in discrete space to compute gradients through a discrete argmax operation. In this paper, we develop reinforcement learning algorithms that use direct optimization to compute gradients of the expected return in environments with discrete actions. We call the resulting algorithms "direct policy gradient" algorithms and investigate their properties, showing that there is a built-in variance reduction technique and that a parameter that was previously viewed as a numerical approximation can be interpreted as controlling risk sensitivity. We also tackle challenges in algorithm design, leveraging ideas from A$^\star$ Sampling to develop a practical algorithm. Empirically, we show that the algorithm performs well in illustrative domains, and that it can make use of domain knowledge about upper bounds on return-to-go to speed up training.