 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Active Learning for Pre-trained Transformer-based Models
Aug 10, 2022



Multi-task learning, in which several tasks are jointly learned by a single model, allows NLP models to share information from multiple annotations and may facilitate better predictions when the tasks are inter-related. This technique, however, requires annotating the same text with multiple annotation schemes which may be costly and laborious. Active learning (AL) has been demonstrated to optimize annotation processes by iteratively selecting unlabeled examples whose annotation is most valuable for the NLP model. Yet, multi-task active learning (MT-AL) has not been applied to state-of-the-art pre-trained Transformer-based NLP models. This paper aims to close this gap. We explore various multi-task selection criteria in three realistic multi-task scenarios, reflecting different relations between the participating tasks, and demonstrate the effectiveness of multi-task compared to single-task selection. Our results suggest that MT-AL can be effectively used in order to minimize annotation efforts for multi-task NLP models.
Learning Discrete Structured Variational Auto-Encoder using Natural Evolution Strategies
May 03, 2022


Discrete variational auto-encoders (VAEs) are able to represent semantic latent spaces in generative learning. In many real-life settings, the discrete latent space consists of high-dimensional structures, and propagating gradients through the relevant structures often requires enumerating over an exponentially large latent space. Recently, various approaches were devised to propagate approximated gradients without enumerating over the space of possible structures. In this work, we use Natural Evolution Strategies (NES), a class of gradient-free black-box optimization algorithms, to learn discrete structured VAEs. The NES algorithms are computationally appealing as they estimate gradients with forward pass evaluations only, thus they do not require to propagate gradients through their discrete structures. We demonstrate empirically that optimizing discrete structured VAEs using NES is as effective as gradient-based approximations. Lastly, we prove NES converges for non-Lipschitz functions as appear in discrete structured VAEs.
Designing an Automatic Agent for Repeated Language based Persuasion Games
May 11, 2021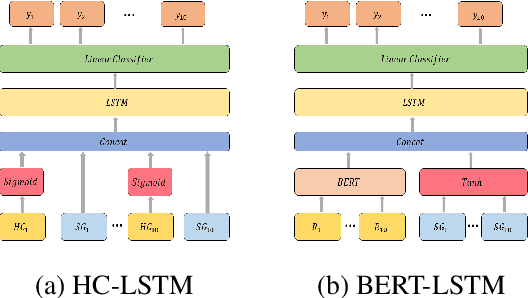

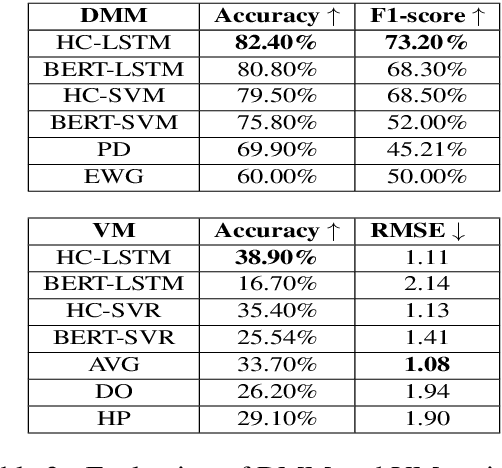

Persuasion games are fundamental in economics and AI research and serve as the basis for important applications. However, work on this setup assumes communication with stylized messages that do not consist of rich human language. In this paper we consider a repeated sender (expert) -- receiver (decision maker) game, where the sender is fully informed about the state of the world and aims to persuade the receiver to accept a deal by sending one of several possible natural language reviews. We design an automatic expert that plays this repeated game, aiming to achieve the maximal payoff. Our expert is implemented within the Monte Carlo Tree Search (MCTS) algorithm, with deep learning models that exploit behavioral and linguistic signals in order to predict the next action of the decision maker, and the future payoff of the expert given the state of the game and a candidate review. We demonstrate the superiority of our expert over strong baselines, its adaptability to different decision makers, and that its selected reviews are nicely adapted to the proposed deal.
Model Compression for Domain Adaptation through Causal Effect Estimation
Jan 18, 2021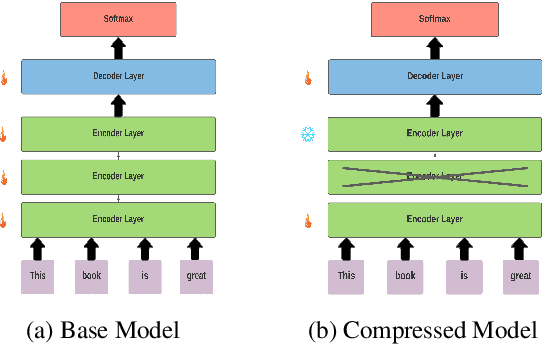
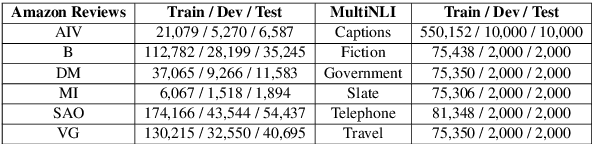
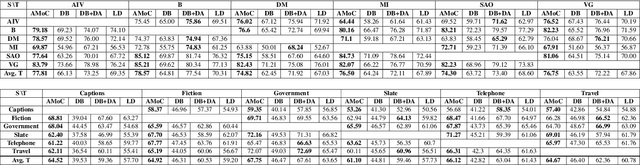
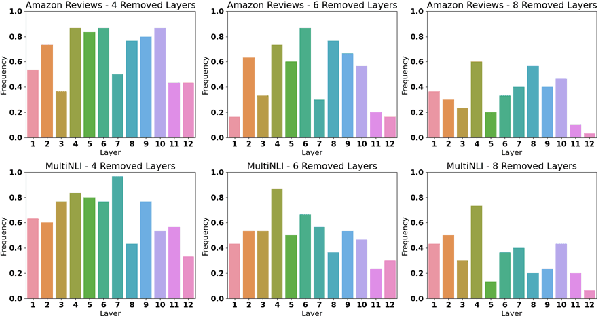
Recent improvements in the predictive quality of natural language processing systems are often dependent on a substantial increase in the number of model parameters. This has led to various attempts of compressing such models, but existing methods have not considered the differences in the predictive power of various model components or in the generalizability of the compressed models. To understand the connection between model compression and out-of-distribution generalization, we define the task of compressing language representation models such that they perform best in a domain adaptation setting. We choose to address this problem from a causal perspective, attempting to estimate the \textit{average treatment effect} (ATE) of a model component, such as a single layer, on the model's predictions. Our proposed ATE-guided Model Compression scheme (AMoC), generates many model candidates, differing by the model components that were removed. Then, we select the best candidate through a stepwise regression model that utilizes the ATE to predict the expected performance on the target domain. AMoC outperforms strong baselines on 46 of 60 domain pairs across two text classification tasks, with an average improvement of more than 3\% in F1 above the strongest baseline.
Deep Contextualized Self-training for Low Resource Dependency Parsing
Nov 11, 2019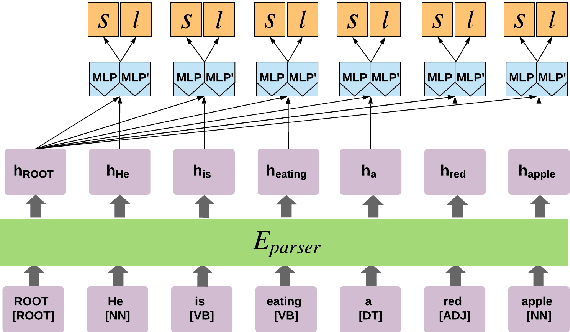
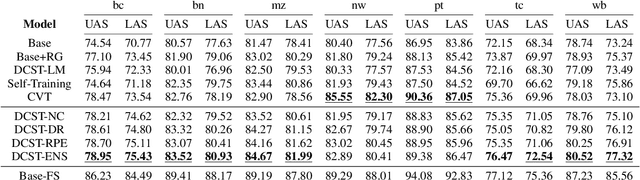
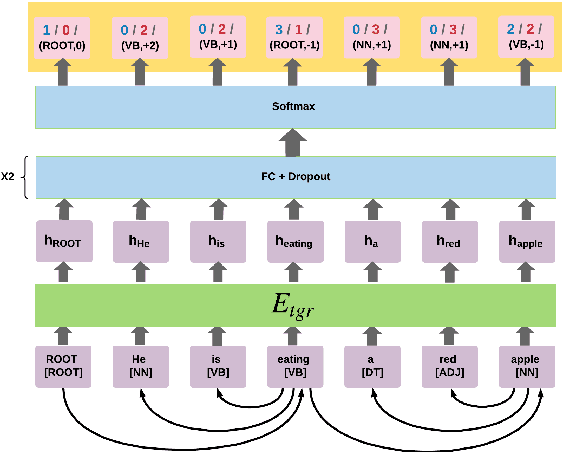
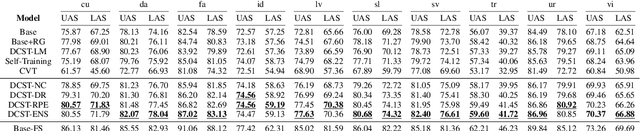
Neural dependency parsing has proven very effective, achieving state-of-the-art results on numerous domains and languages. Unfortunately, it requires large amounts of labeled data, that is costly and laborious to create. In this paper we propose a self-training algorithm that alleviates this annotation bottleneck by training a parser on its own output. Our Deep Contextualized Self-training (DCST) algorithm utilizes representation models trained on sequence labeling tasks that are derived from the parser's output when applied to unlabeled data, and integrates these models with the base parser through a gating mechanism. We conduct experiments across multiple languages, both in low resource in-domain and in cross-domain setups, and demonstrate that DCST substantially outperforms traditional self-training as well as recent semi-supervised training methods.