 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSVisLoc: Generalizable Visual Localization for Gaussian Splatting Scene Representations
Aug 25, 2025We introduce GSVisLoc, a visual localization method designed for 3D Gaussian Splatting (3DGS) scene representations. Given a 3DGS model of a scene and a query image, our goal is to estimate the camera's position and orientation. We accomplish this by robustly matching scene features to image features. Scene features are produced by downsampling and encoding the 3D Gaussians while image features are obtained by encoding image patches. Our algorithm proceeds in three steps, starting with coarse matching, then fine matching, and finally by applying pose refinement for an accurate final estimate. Importantly, our method leverages the explicit 3DGS scene representation for visual localization without requiring modifications, retraining, or additional reference images. We evaluate GSVisLoc on both indoor and outdoor scenes, demonstrating competitive localization performance on standard benchmarks while outperforming existing 3DGS-based baselines. Moreover, our approach generalizes effectively to novel scenes without additional training.
Consensus Learning with Deep Sets for Essential Matrix Estimation
Jun 25, 2024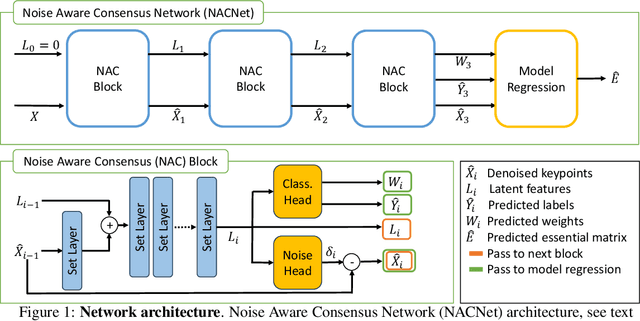
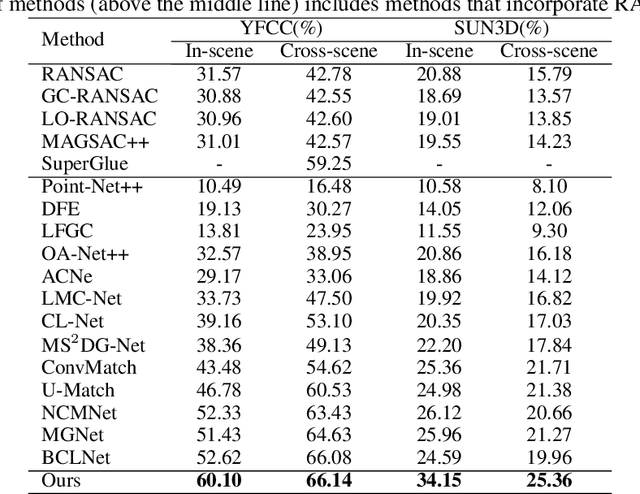
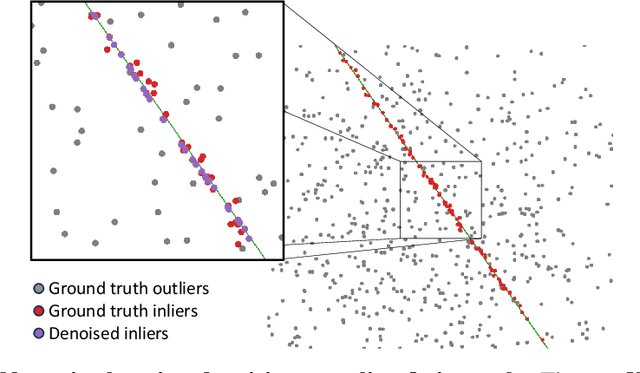
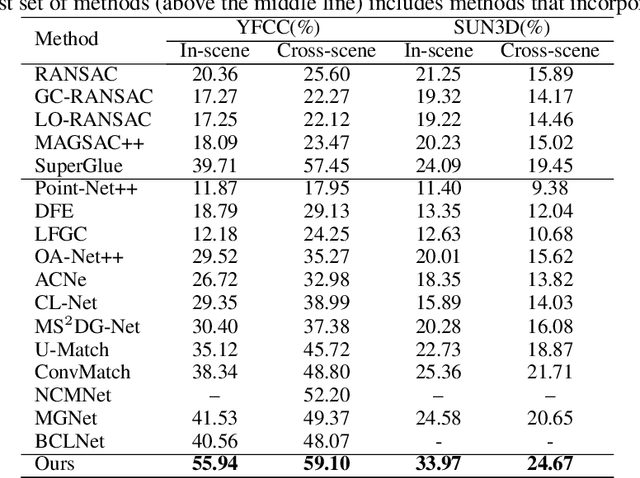
Robust estimation of the essential matrix, which encodes the relative position and orientation of two cameras, is a fundamental step in structure from motion pipelines. Recent deep-based methods achieved accurate estimation by using complex network architectures that involve graphs, attention layers, and hard pruning steps. Here, we propose a simpler network architecture based on Deep Sets. Given a collection of point matches extracted from two images, our method identifies outlier point matches and models the displacement noise in inlier matches. A weighted DLT module uses these predictions to regress the essential matrix. Our network achieves accurate recovery that is superior to existing networks with significantly more complex architectures.
RESFM: Robust Equivariant Multiview Structure from Motion
Apr 22, 2024



Multiview Structure from Motion is a fundamental and challenging computer vision problem. A recent deep-based approach was proposed utilizing matrix equivariant architectures for the simultaneous recovery of camera pose and 3D scene structure from large image collections. This work however made the unrealistic assumption that the point tracks given as input are clean of outliers. Here we propose an architecture suited to dealing with outliers by adding an inlier/outlier classifying module that respects the model equivariance and by adding a robust bundle adjustment step. Experiments demonstrate that our method can be successfully applied in realistic settings that include large image collections and point tracks extracted with common heuristics and include many outliers.
GRelPose: Generalizable End-to-End Relative Camera Pose Regression
Nov 27, 2022This paper proposes a generalizable, end-to-end deep learning-based method for relative pose regression between two images. Given two images of the same scene captured from different viewpoints, our algorithm predicts the relative rotation and translation between the two respective cameras. Despite recent progress in the field, current deep-based methods exhibit only limited generalization to scenes not seen in training. Our approach introduces a network architecture that extracts a grid of coarse features for each input image using the pre-trained LoFTR network. It subsequently relates corresponding features in the two images, and finally uses a convolutional network to recover the relative rotation and translation between the respective cameras. Our experiments indicate that the proposed architecture can generalize to novel scenes, obtaining higher accuracy than existing deep-learning-based methods in various settings and datasets, in particular with limited training data.