 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Similarity between the Laplace and Neural Tangent Kernels
Paper and Code
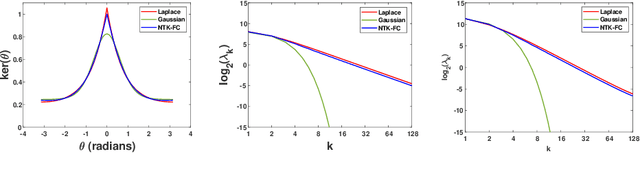
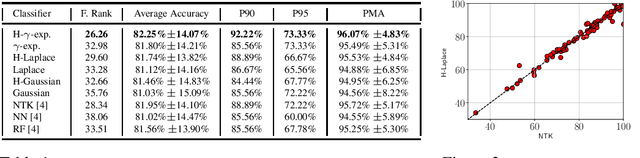
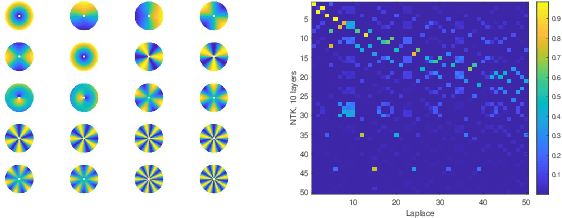

Recent theoretical work has shown that massively overparameterized neural networks are equivalent to kernel regressors that use Neural Tangent Kernels(NTK). Experiments show that these kernel methods perform similarly to real neural networks. Here we show that NTK for fully connected networks is closely related to the standard Laplace kernel. We show theoretically that for normalized data on the hypersphere both kernels have the same eigenfunctions and their eigenvalues decay polynomially at the same rate, implying that their Reproducing Kernel Hilbert Spaces (RKHS) include the same sets of functions. This means that both kernels give rise to classes of functions with the same smoothness properties. The two kernels differ for data off the hypersphere, but experiments indicate that when data is properly normalized these differences are not significant. Finally, we provide experiments on real data comparing NTK and the Laplace kernel, along with a larger class of{\gamma}-exponential kernels. We show that these perform almost identically. Our results suggest that much insight about neural networks can be obtained from analysis of the well-known Laplace kernel, which has a simple closed-form.