 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Judge a Language Model by Its Last Layer: Contrastive Learning with Layer-Wise Attention Pooling
Paper and Code
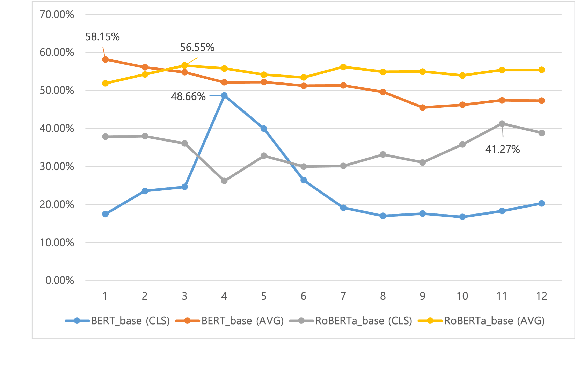
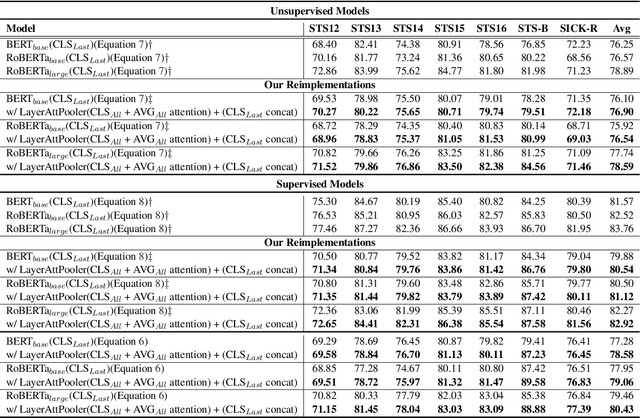
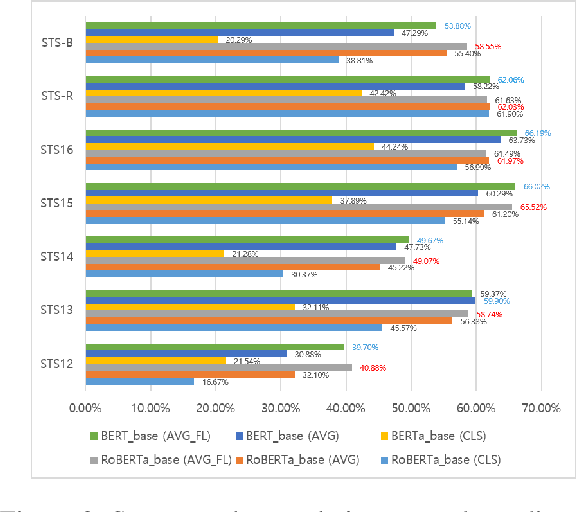

Recent pre-trained language models (PLMs) achieved great success on many natural language processing tasks through learning linguistic features and contextualized sentence representation. Since attributes captured in stacked layers of PLMs are not clearly identified, straightforward approaches such as embedding the last layer are commonly preferred to derive sentence representations from PLMs. This paper introduces the attention-based pooling strategy, which enables the model to preserve layer-wise signals captured in each layer and learn digested linguistic features for downstream tasks. The contrastive learning objective can adapt the layer-wise attention pooling to both unsupervised and supervised manners. It results in regularizing the anisotropic space of pre-trained embeddings and being more uniform. We evaluate our model on standard semantic textual similarity (STS) and semantic search tasks. As a result, our method improved the performance of the base contrastive learned BERT_base and variants.