 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroadband Ground Motion Synthesis by Diffusion Model with Minimal Condition
Dec 23, 2024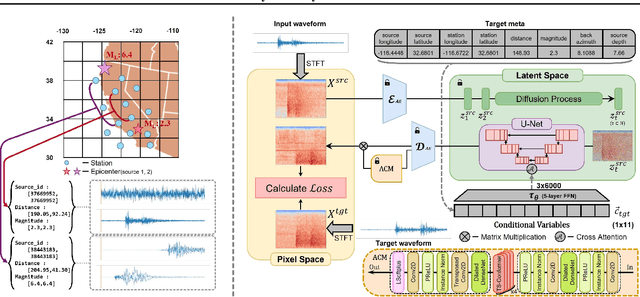
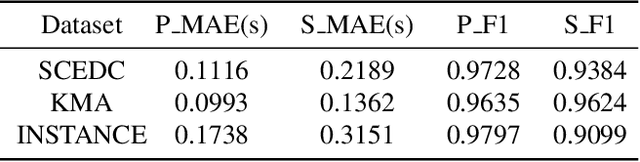
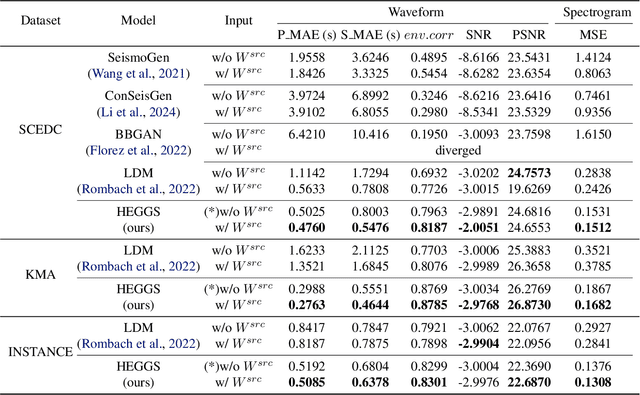
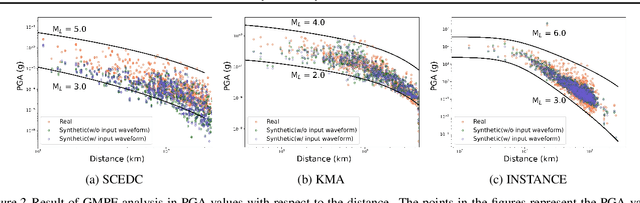
Earthquakes are rare. Hence there is a fundamental call for reliable methods to generate realistic ground motion data for data-driven approaches in seismology. Recent GAN-based methods fall short of the call, as the methods either require special information such as geological traits or generate subpar waveforms that fail to satisfy seismological constraints such as phase arrival times. We propose a specialized Latent Diffusion Model (LDM) that reliably generates realistic waveforms after learning from real earthquake data with minimal conditions: location and magnitude. We also design a domain-specific training method that exploits the traits of earthquake dataset: multiple observed waveforms time-aligned and paired to each earthquake source that are tagged with seismological metadata comprised of earthquake magnitude, depth of focus, and the locations of epicenter and seismometers. We construct the time-aligned earthquake dataset using Southern California Earthquake Data Center (SCEDC) API, and train our model with the dataset and our proposed training method for performance evaluation. Our model surpasses all comparable data-driven methods in various test criteria not only from waveform generation domain but also from seismology such as phase arrival time, GMPE analysis, and spectrum analysis. Our result opens new future research directions for deep learning applications in seismology.
Enhancement of text recognition for hanja handwritten documents of Ancient Korea
Dec 14, 2024We implemented a high-performance optical character recognition model for classical handwritten documents using data augmentation with highly variable cropping within the document region. Optical character recognition in handwritten documents, especially classical documents, has been a challenging topic in many countries and research organizations due to its difficulty. Although many researchers have conducted research on this topic, the quality of classical texts over time and the unique stylistic characteristics of various authors have made it difficult, and it is clear that the recognition of hanja handwritten documents is a meaningful and special challenge, especially since hanja, which has been developed by reflecting the vocabulary, semantic, and syntactic features of the Joseon Dynasty, is different from classical Chinese characters. To study this challenge, we used 1100 cursive documents, which are small in size, and augmented 100 documents per document by cropping a randomly sized region within each document for training, and trained them using a two-stage object detection model, High resolution neural network (HRNet), and applied the resulting model to achieve a high inference recognition rate of 90% for cursive documents. Through this study, we also confirmed that the performance of OCR is affected by the simplified characters, variants, variant characters, common characters, and alternators of Chinese characters that are difficult to see in other studies, and we propose that the results of this study can be applied to optical character recognition of modern documents in multiple languages as well as other typefaces in classical documents.
Transfer Learning across Several Centuries: Machine and Historian Integrated Method to Decipher Royal Secretary's Diary
Jun 26, 2023



A named entity recognition and classification plays the first and foremost important role in capturing semantics in data and anchoring in translation as well as downstream study for history. However, NER in historical text has faced challenges such as scarcity of annotated corpus, multilanguage variety, various noise, and different convention far different from the contemporary language model. This paper introduces Korean historical corpus (Diary of Royal secretary which is named SeungJeongWon) recorded over several centuries and recently added with named entity information as well as phrase markers which historians carefully annotated. We fined-tuned the language model on history corpus, conducted extensive comparative experiments using our language model and pretrained muti-language models. We set up the hypothesis of combination of time and annotation information and tested it based on statistical t test. Our finding shows that phrase markers clearly improve the performance of NER model in predicting unseen entity in documents written far different time period. It also shows that each of phrase marker and corpus-specific trained model does not improve the performance. We discuss the future research directions and practical strategies to decipher the history document.