 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnigram-Normalized Perplexity as a Language Model Performance Measure with Different Vocabulary Sizes
Nov 26, 2020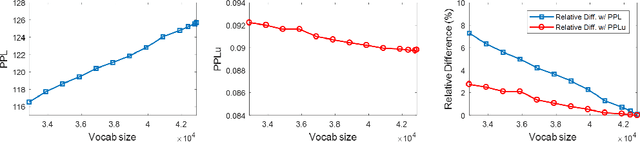


Although Perplexity is a widely used performance metric for language models, the values are highly dependent upon the number of words in the corpus and is useful to compare performance of the same corpus only. In this paper, we propose a new metric that can be used to evaluate language model performance with different vocabulary sizes. The proposed unigram-normalized Perplexity actually presents the performance improvement of the language models from that of simple unigram model, and is robust on the vocabulary size. Both theoretical analysis and computational experiments are reported.
Unpaired Speech Enhancement by Acoustic and Adversarial Supervision for Speech Recognition
Nov 06, 2018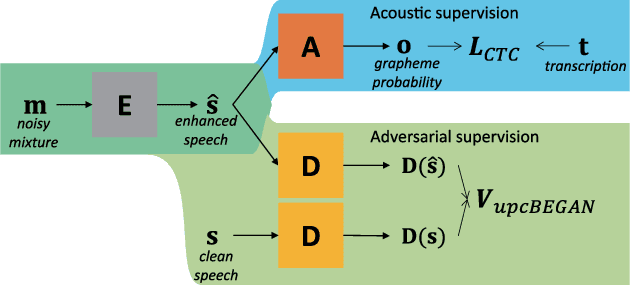
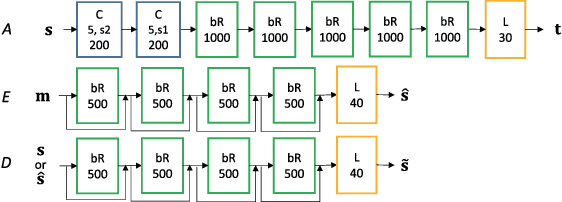

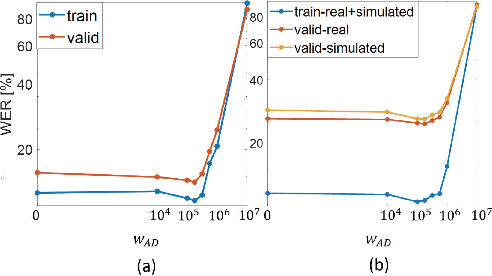
Many speech enhancement methods try to learn the relationship between noisy and clean speech, obtained using an acoustic room simulator. We point out several limitations of enhancement methods relying on clean speech targets; the goal of this work is proposing an alternative learning algorithm, called acoustic and adversarial supervision (AAS). AAS makes the enhanced output both maximizing the likelihood of transcription on the pre-trained acoustic model and having general characteristics of clean speech, which improve generalization on unseen noisy speeches. We employ the connectionist temporal classification and the unpaired conditional boundary equilibrium generative adversarial network as the loss function of AAS. AAS is tested on two datasets including additive noise without and with reverberation, Librispeech + DEMAND and CHiME-4. By visualizing the enhanced speech with different loss combinations, we demonstrate the role of each supervision. AAS achieves a lower word error rate than other state-of-the-art methods using the clean speech target in both datasets.
Deep CNNs along the Time Axis with Intermap Pooling for Robustness to Spectral Variations
Jul 12, 2016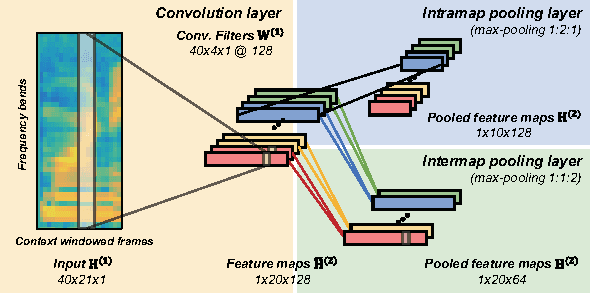
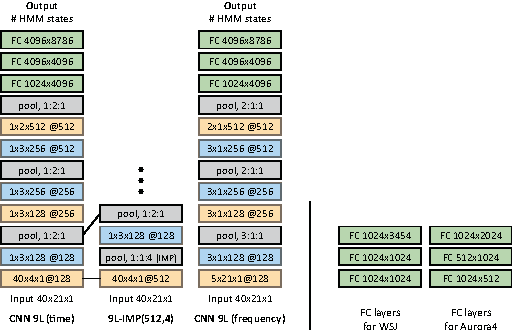
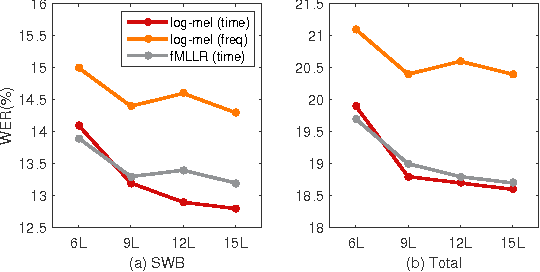
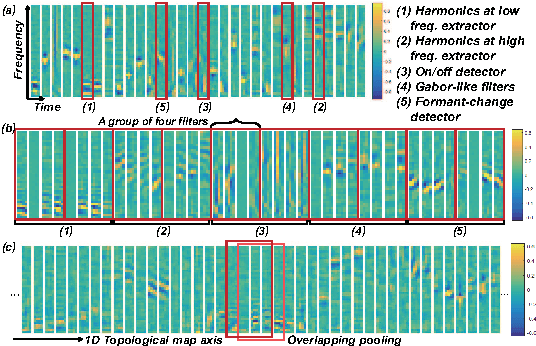
Convolutional neural networks (CNNs) with convolutional and pooling operations along the frequency axis have been proposed to attain invariance to frequency shifts of features. However, this is inappropriate with regard to the fact that acoustic features vary in frequency. In this paper, we contend that convolution along the time axis is more effective. We also propose the addition of an intermap pooling (IMP) layer to deep CNNs. In this layer, filters in each group extract common but spectrally variant features, then the layer pools the feature maps of each group. As a result, the proposed IMP CNN can achieve insensitivity to spectral variations characteristic of different speakers and utterances. The effectiveness of the IMP CNN architecture is demonstrated on several LVCSR tasks. Even without speaker adaptation techniques, the architecture achieved a WER of 12.7% on the SWB part of the Hub5'2000 evaluation test set, which is competitive with other state-of-the-art methods.