 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable Multi-Domain Language Model for Transformer ASR
Aug 14, 2020



We propose an adapter based multi-domain Transformer based language model (LM) for Transformer ASR. The model consists of a big size common LM and small size adapters. The model can perform multi-domain adaptation with only the small size adapters and its related layers. The proposed model can reuse the full fine-tuned LM which is fine-tuned using all layers of an original model. The proposed LM can be expanded to new domains by adding about 2% of parameters for a first domain and 13% parameters for after second domain. The proposed model is also effective in reducing the model maintenance cost because it is possible to omit the costly and time-consuming common LM pre-training process. Using proposed adapter based approach, we observed that a general LM with adapter can outperform a dedicated music domain LM in terms of word error rate (WER).
Deep CNNs along the Time Axis with Intermap Pooling for Robustness to Spectral Variations
Jul 12, 2016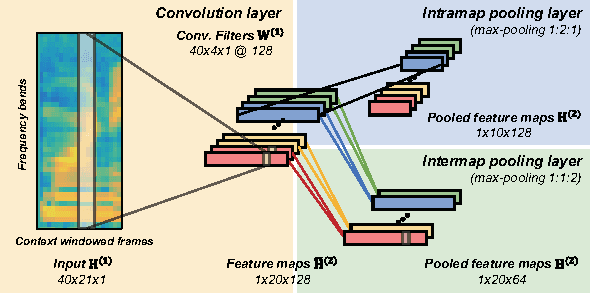
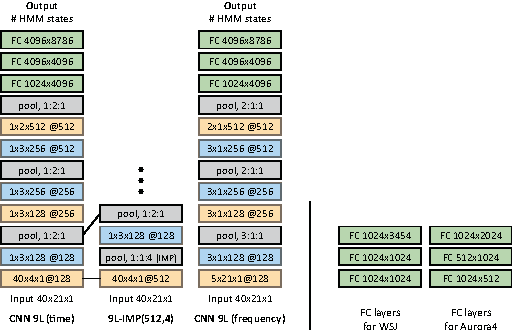
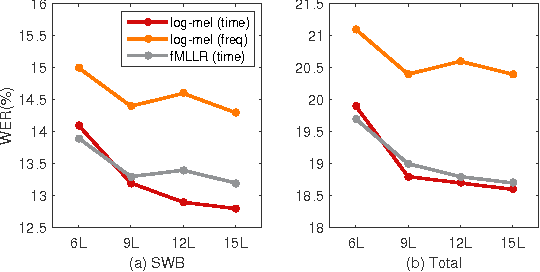
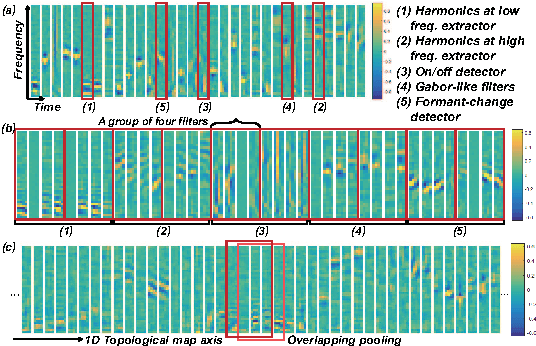
Convolutional neural networks (CNNs) with convolutional and pooling operations along the frequency axis have been proposed to attain invariance to frequency shifts of features. However, this is inappropriate with regard to the fact that acoustic features vary in frequency. In this paper, we contend that convolution along the time axis is more effective. We also propose the addition of an intermap pooling (IMP) layer to deep CNNs. In this layer, filters in each group extract common but spectrally variant features, then the layer pools the feature maps of each group. As a result, the proposed IMP CNN can achieve insensitivity to spectral variations characteristic of different speakers and utterances. The effectiveness of the IMP CNN architecture is demonstrated on several LVCSR tasks. Even without speaker adaptation techniques, the architecture achieved a WER of 12.7% on the SWB part of the Hub5'2000 evaluation test set, which is competitive with other state-of-the-art methods.