 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Based Visual-Language Place Recognition
Oct 25, 2024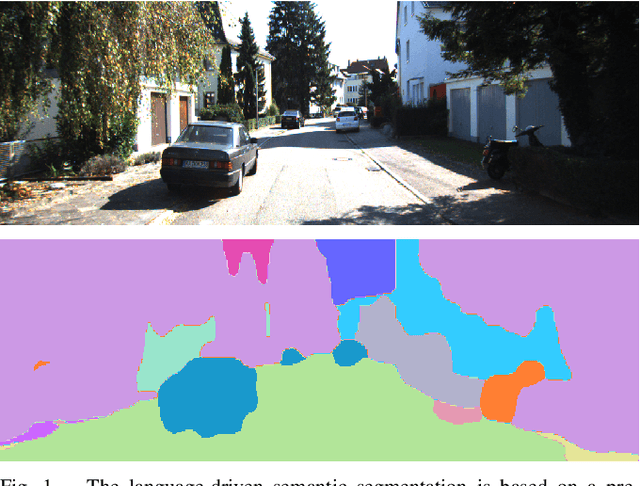
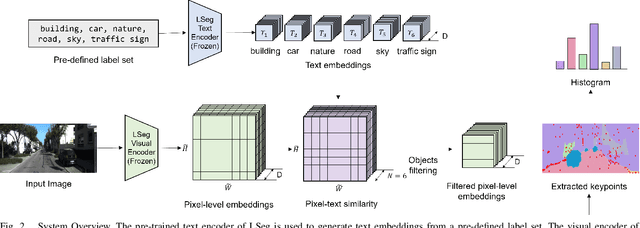
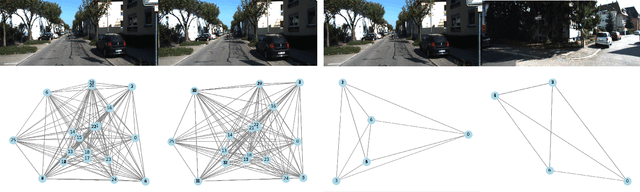

In vision-based robot localization and SLAM, Visual Place Recognition (VPR) is essential. This paper addresses the problem of VPR, which involves accurately recognizing the location corresponding to a given query image. A popular approach to vision-based place recognition relies on low-level visual features. Despite significant progress in recent years, place recognition based on low-level visual features is challenging when there are changes in scene appearance. To address this, end-to-end training approaches have been proposed to overcome the limitations of hand-crafted features. However, these approaches still fail under drastic changes and require large amounts of labeled data to train models, presenting a significant limitation. Methods that leverage high-level semantic information, such as objects or categories, have been proposed to handle variations in appearance. In this paper, we introduce a novel VPR approach that remains robust to scene changes and does not require additional training. Our method constructs semantic image descriptors by extracting pixel-level embeddings using a zero-shot, language-driven semantic segmentation model. We validate our approach in challenging place recognition scenarios using real-world public dataset. The experiments demonstrate that our method outperforms non-learned image representation techniques and off-the-shelf convolutional neural network (CNN) descriptors. Our code is available at https: //github.com/woo-soojin/context-based-vlpr.
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024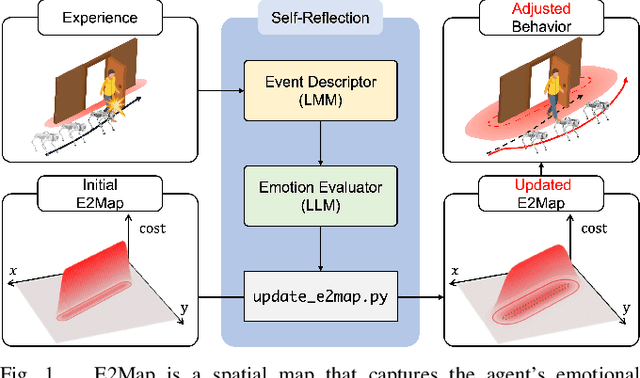



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
Non-verbal Interaction and Interface with a Quadruped Robot using Body and Hand Gestures: Design and User Experience Evaluation
Aug 30, 2024



In recent years, quadruped robots have attracted significant attention due to their practical advantages in maneuverability, particularly when navigating rough terrain and climbing stairs. As these robots become more integrated into various industries, including construction and healthcare, researchers have increasingly focused on developing intuitive interaction methods such as speech and gestures that do not require separate devices such as keyboards or joysticks. This paper aims at investigating a comfortable and efficient interaction method with quadruped robots that possess a familiar form factor. To this end, we conducted two preliminary studies to observe how individuals naturally interact with a quadruped robot in natural and controlled settings, followed by a prototype experiment to examine human preferences for body-based and hand-based gesture controls using a Unitree Go1 Pro quadruped robot. We assessed the user experience of 13 participants using the User Experience Questionnaire and measured the time taken to complete specific tasks. The findings of our preliminary results indicate that humans have a natural preference for communicating with robots through hand and body gestures rather than speech. In addition, participants reported higher satisfaction and completed tasks more quickly when using body gestures to interact with the robot. This contradicts the fact that most gesture-based control technologies for quadruped robots are hand-based. The video is available at https://youtu.be/rysv1p1zvp4.
No More Potentially Dynamic Objects: Static Point Cloud Map Generation based on 3D Object Detection and Ground Projection
Jul 01, 2024In this paper, we propose an algorithm to generate a static point cloud map based on LiDAR point cloud data. Our proposed pipeline detects dynamic objects using 3D object detectors and projects points of dynamic objects onto the ground. Typically, point cloud data acquired in real-time serves as a snapshot of the surrounding areas containing both static objects and dynamic objects. The static objects include buildings and trees, otherwise, the dynamic objects contain objects such as parked cars that change their position over time. Removing dynamic objects from the point cloud map is crucial as they can degrade the quality and localization accuracy of the map. To address this issue, in this paper, we propose an algorithm that creates a map only consisting of static objects. We apply a 3D object detection algorithm to the point cloud data which are obtained from LiDAR to implement our pipeline. We then stack the points to create the map after performing ground segmentation and projection. As a result, not only we can eliminate currently dynamic objects at the time of map generation but also potentially dynamic objects such as parked vehicles. We validate the performance of our method using two kinds of datasets collected on real roads: KITTI and our dataset. The result demonstrates the capability of our proposal to create an accurate static map excluding dynamic objects from input point clouds. Also, we verified the improved performance of localization using a generated map based on our method.