 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Based Visual-Language Place Recognition
Paper and Code
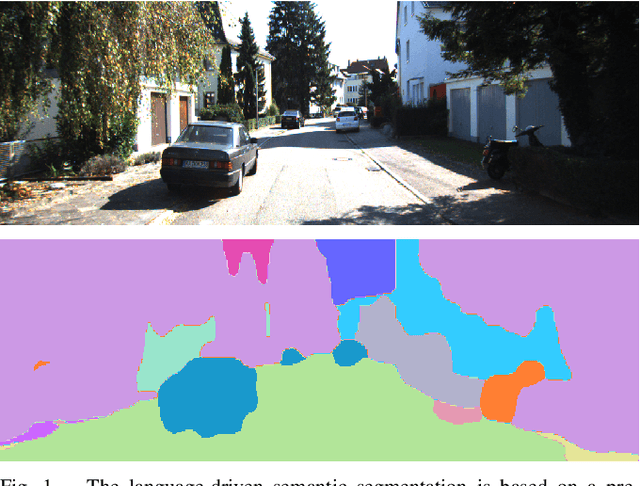
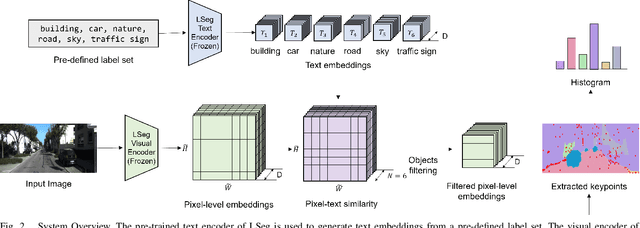
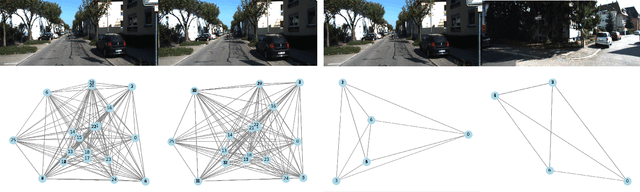

In vision-based robot localization and SLAM, Visual Place Recognition (VPR) is essential. This paper addresses the problem of VPR, which involves accurately recognizing the location corresponding to a given query image. A popular approach to vision-based place recognition relies on low-level visual features. Despite significant progress in recent years, place recognition based on low-level visual features is challenging when there are changes in scene appearance. To address this, end-to-end training approaches have been proposed to overcome the limitations of hand-crafted features. However, these approaches still fail under drastic changes and require large amounts of labeled data to train models, presenting a significant limitation. Methods that leverage high-level semantic information, such as objects or categories, have been proposed to handle variations in appearance. In this paper, we introduce a novel VPR approach that remains robust to scene changes and does not require additional training. Our method constructs semantic image descriptors by extracting pixel-level embeddings using a zero-shot, language-driven semantic segmentation model. We validate our approach in challenging place recognition scenarios using real-world public dataset. The experiments demonstrate that our method outperforms non-learned image representation techniques and off-the-shelf convolutional neural network (CNN) descriptors. Our code is available at https: //github.com/woo-soojin/context-based-vlpr.