 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-Based NLoS Pedestrian Localization for Darting-Out Scenarios Near Parked Vehicles with Camera-Assisted Point Cloud Interpretation
Aug 06, 2025



The presence of Non-Line-of-Sight (NLoS) blind spots resulting from roadside parking in urban environments poses a significant challenge to road safety, particularly due to the sudden emergence of pedestrians. mmWave technology leverages diffraction and reflection to observe NLoS regions, and recent studies have demonstrated its potential for detecting obscured objects. However, existing approaches predominantly rely on predefined spatial information or assume simple wall reflections, thereby limiting their generalizability and practical applicability. A particular challenge arises in scenarios where pedestrians suddenly appear from between parked vehicles, as these parked vehicles act as temporary spatial obstructions. Furthermore, since parked vehicles are dynamic and may relocate over time, spatial information obtained from satellite maps or other predefined sources may not accurately reflect real-time road conditions, leading to erroneous sensor interpretations. To address this limitation, we propose an NLoS pedestrian localization framework that integrates monocular camera image with 2D radar point cloud (PCD) data. The proposed method initially detects parked vehicles through image segmentation, estimates depth to infer approximate spatial characteristics, and subsequently refines this information using 2D radar PCD to achieve precise spatial inference. Experimental evaluations conducted in real-world urban road environments demonstrate that the proposed approach enhances early pedestrian detection and contributes to improved road safety. Supplementary materials are available at https://hiyeun.github.io/NLoS/.
Leveraging Language Models for Out-of-Distribution Recovery in Reinforcement Learning
Mar 21, 2025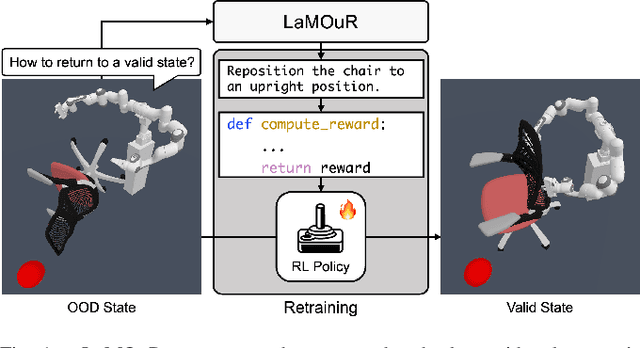



Deep Reinforcement Learning (DRL) has demonstrated strong performance in robotic control but remains susceptible to out-of-distribution (OOD) states, often resulting in unreliable actions and task failure. While previous methods have focused on minimizing or preventing OOD occurrences, they largely neglect recovery once an agent encounters such states. Although the latest research has attempted to address this by guiding agents back to in-distribution states, their reliance on uncertainty estimation hinders scalability in complex environments. To overcome this limitation, we introduce Language Models for Out-of-Distribution Recovery (LaMOuR), which enables recovery learning without relying on uncertainty estimation. LaMOuR generates dense reward codes that guide the agent back to a state where it can successfully perform its original task, leveraging the capabilities of LVLMs in image description, logical reasoning, and code generation. Experimental results show that LaMOuR substantially enhances recovery efficiency across diverse locomotion tasks and even generalizes effectively to complex environments, including humanoid locomotion and mobile manipulation, where existing methods struggle. The code and supplementary materials are available at \href{https://lamour-rl.github.io/}{https://lamour-rl.github.io/}.
GOTLoc: General Outdoor Text-based Localization Using Scene Graph Retrieval with OpenStreetMap
Jan 15, 2025We propose GOTLoc, a robust localization method capable of operating even in outdoor environments where GPS signals are unavailable. The method achieves this robust localization by leveraging comparisons between scene graphs generated from text descriptions and maps. Existing text-based localization studies typically represent maps as point clouds and identify the most similar scenes by comparing embeddings of text and point cloud data. However, point cloud maps have limited scalability as it is impractical to pre-generate maps for all outdoor spaces. Furthermore, their large data size makes it challenging to store and utilize them directly on actual robots. To address these issues, GOTLoc leverages compact data structures, such as scene graphs, to store spatial information, enabling individual robots to carry and utilize large amounts of map data. Additionally, by utilizing publicly available map data, such as OpenStreetMap, which provides global information on outdoor spaces, we eliminate the need for additional effort to create custom map data. For performance evaluation, we utilized the KITTI360Pose dataset in conjunction with corresponding OpenStreetMap data to compare the proposed method with existing approaches. Our results demonstrate that the proposed method achieves accuracy comparable to algorithms relying on point cloud maps. Moreover, in city-scale tests, GOTLoc required significantly less storage compared to point cloud-based methods and completed overall processing within a few seconds, validating its applicability to real-world robotics. Our code is available at https://github.com/donghwijung/GOTLoc.
Context-Based Visual-Language Place Recognition
Oct 25, 2024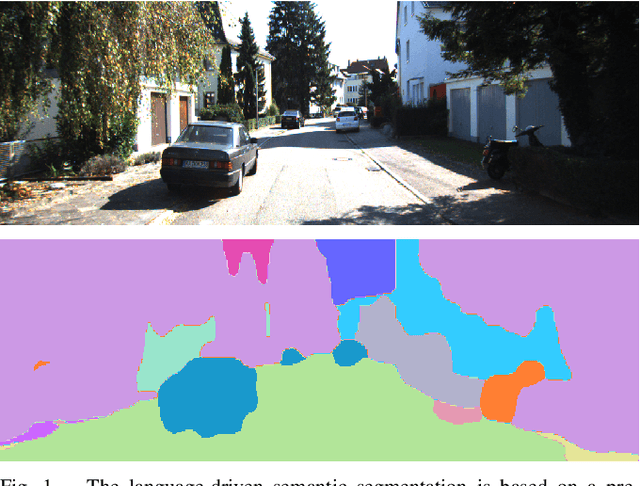
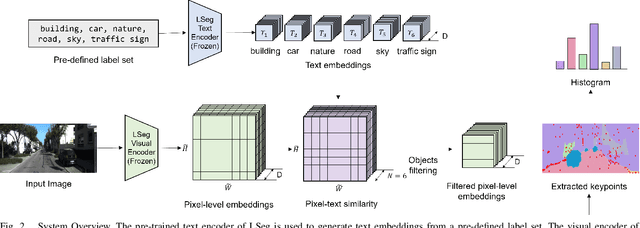
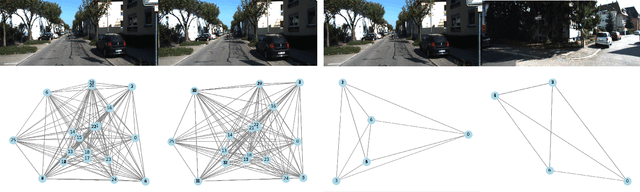

In vision-based robot localization and SLAM, Visual Place Recognition (VPR) is essential. This paper addresses the problem of VPR, which involves accurately recognizing the location corresponding to a given query image. A popular approach to vision-based place recognition relies on low-level visual features. Despite significant progress in recent years, place recognition based on low-level visual features is challenging when there are changes in scene appearance. To address this, end-to-end training approaches have been proposed to overcome the limitations of hand-crafted features. However, these approaches still fail under drastic changes and require large amounts of labeled data to train models, presenting a significant limitation. Methods that leverage high-level semantic information, such as objects or categories, have been proposed to handle variations in appearance. In this paper, we introduce a novel VPR approach that remains robust to scene changes and does not require additional training. Our method constructs semantic image descriptors by extracting pixel-level embeddings using a zero-shot, language-driven semantic segmentation model. We validate our approach in challenging place recognition scenarios using real-world public dataset. The experiments demonstrate that our method outperforms non-learned image representation techniques and off-the-shelf convolutional neural network (CNN) descriptors. Our code is available at https: //github.com/woo-soojin/context-based-vlpr.
A Data-Driven Odyssey in Solar Vehicles
Oct 23, 2024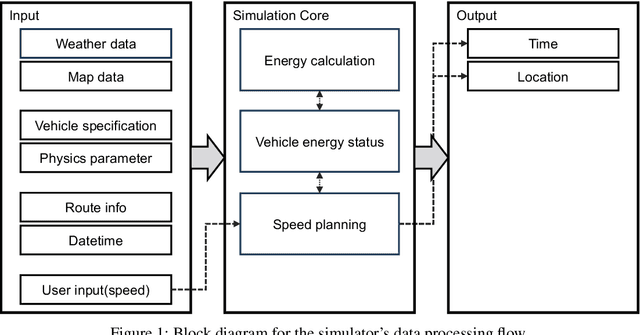
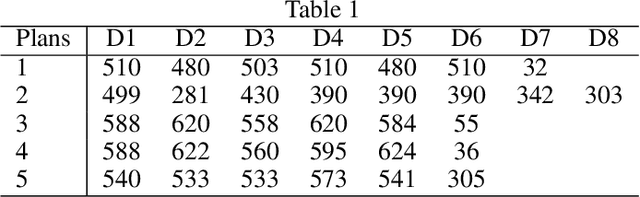
Solar vehicles, which simultaneously produce and consume energy, require meticulous energy management. However, potential users often feel uncertain about their operation compared to conventional vehicles. This study presents a simulator designed to help users understand long-distance travel in solar vehicles and recognize the importance of proper energy management. By utilizing Google Maps data and weather information, the simulator replicates real-world driving conditions and provides a dashboard displaying vehicle status, updated hourly based on user-inputted speed. Users can explore various speed policy scenarios and receive recommendations for optimal driving strategies. The simulator's effectiveness was validated using the route of the World Solar Challenge (WSC). This research enables users to monitor energy dynamics before a journey, enhancing their understanding of energy management and informing appropriate speed decisions.
Point Cloud Structural Similarity-based Underwater Sonar Loop Detection
Sep 21, 2024


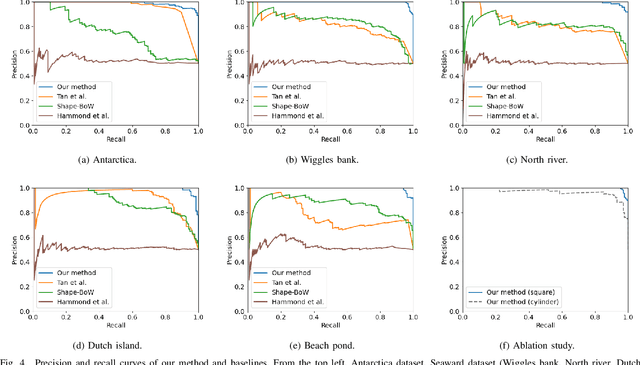
In order to enable autonomous navigation in underwater environments, a map needs to be created in advance using a Simultaneous Localization and Mapping (SLAM) algorithm that utilizes sensors like a sonar. At this time, loop closure is employed to reduce the pose error accumulated during the SLAM process. In the case of loop detection using a sonar, some previous studies have used a method of projecting the 3D point cloud into 2D, then extracting keypoints and matching them. However, during the 2D projection process, data loss occurs due to image resolution, and in monotonous underwater environments such as rivers or lakes, it is difficult to extract keypoints. Additionally, methods that use neural networks or are based on Bag of Words (BoW) have the disadvantage of requiring additional preprocessing tasks, such as training the model in advance or pre-creating a vocabulary. To address these issues, in this paper, we utilize the point cloud obtained from sonar data without any projection to prevent performance degradation due to data loss. Additionally, by calculating the point-wise structural feature map of the point cloud using mathematical formulas and comparing the similarity between point clouds, we eliminate the need for keypoint extraction and ensure that the algorithm can operate in new environments without additional learning or tasks. To evaluate the method, we validated the performance of the proposed algorithm using the Antarctica dataset obtained from deep underwater and the Seaward dataset collected from rivers and lakes. Experimental results show that our proposed method achieves the best loop detection performance in both datasets. Our code is available at https://github.com/donghwijung/point_cloud_structural_similarity_based_underwater_sonar_loop_detection.
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024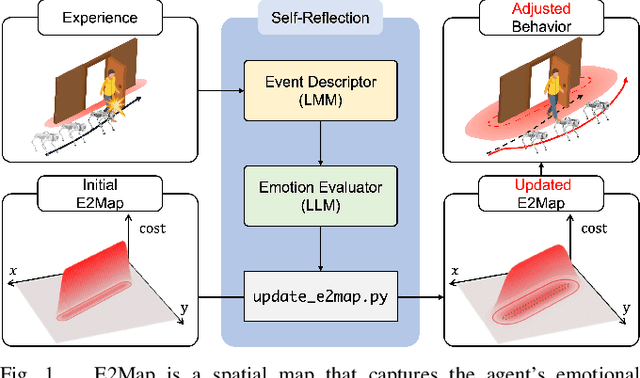



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
Non-verbal Interaction and Interface with a Quadruped Robot using Body and Hand Gestures: Design and User Experience Evaluation
Aug 30, 2024



In recent years, quadruped robots have attracted significant attention due to their practical advantages in maneuverability, particularly when navigating rough terrain and climbing stairs. As these robots become more integrated into various industries, including construction and healthcare, researchers have increasingly focused on developing intuitive interaction methods such as speech and gestures that do not require separate devices such as keyboards or joysticks. This paper aims at investigating a comfortable and efficient interaction method with quadruped robots that possess a familiar form factor. To this end, we conducted two preliminary studies to observe how individuals naturally interact with a quadruped robot in natural and controlled settings, followed by a prototype experiment to examine human preferences for body-based and hand-based gesture controls using a Unitree Go1 Pro quadruped robot. We assessed the user experience of 13 participants using the User Experience Questionnaire and measured the time taken to complete specific tasks. The findings of our preliminary results indicate that humans have a natural preference for communicating with robots through hand and body gestures rather than speech. In addition, participants reported higher satisfaction and completed tasks more quickly when using body gestures to interact with the robot. This contradicts the fact that most gesture-based control technologies for quadruped robots are hand-based. The video is available at https://youtu.be/rysv1p1zvp4.
No More Potentially Dynamic Objects: Static Point Cloud Map Generation based on 3D Object Detection and Ground Projection
Jul 01, 2024In this paper, we propose an algorithm to generate a static point cloud map based on LiDAR point cloud data. Our proposed pipeline detects dynamic objects using 3D object detectors and projects points of dynamic objects onto the ground. Typically, point cloud data acquired in real-time serves as a snapshot of the surrounding areas containing both static objects and dynamic objects. The static objects include buildings and trees, otherwise, the dynamic objects contain objects such as parked cars that change their position over time. Removing dynamic objects from the point cloud map is crucial as they can degrade the quality and localization accuracy of the map. To address this issue, in this paper, we propose an algorithm that creates a map only consisting of static objects. We apply a 3D object detection algorithm to the point cloud data which are obtained from LiDAR to implement our pipeline. We then stack the points to create the map after performing ground segmentation and projection. As a result, not only we can eliminate currently dynamic objects at the time of map generation but also potentially dynamic objects such as parked vehicles. We validate the performance of our method using two kinds of datasets collected on real roads: KITTI and our dataset. The result demonstrates the capability of our proposal to create an accurate static map excluding dynamic objects from input point clouds. Also, we verified the improved performance of localization using a generated map based on our method.
3D Operation of Autonomous Excavator based on Reinforcement Learning through Independent Reward for Individual Joints
Jun 28, 2024
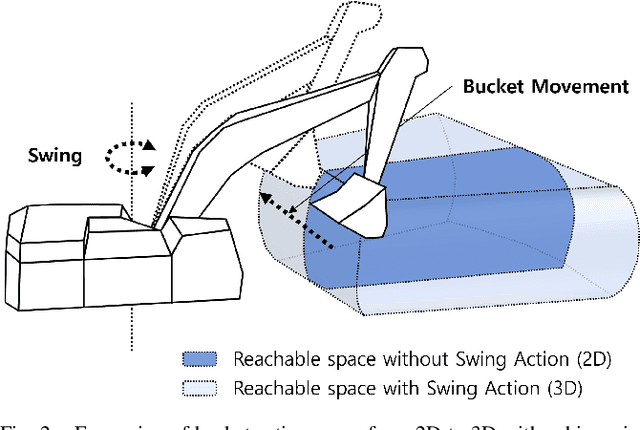
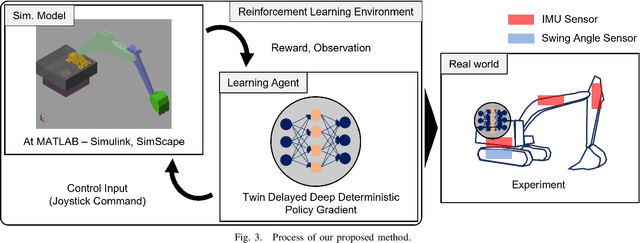

In this paper, we propose a control algorithm based on reinforcement learning, employing independent rewards for each joint to control excavators in a 3D space. The aim of this research is to address the challenges associated with achieving precise control of excavators, which are extensively utilized in construction sites but prove challenging to control with precision due to their hydraulic structures. Traditional methods relied on operator expertise for precise excavator operation, occasionally resulting in safety accidents. Therefore, there have been endeavors to attain precise excavator control through equation-based control algorithms. However, these methods had the limitation of necessitating prior information related to physical values of the excavator, rendering them unsuitable for the diverse range of excavators used in the field. To overcome these limitations, we have explored reinforcement learning-based control methods that do not demand prior knowledge of specific equipment but instead utilize data to train models. Nevertheless, existing reinforcement learning-based methods overlooked cabin swing rotation and confined the bucket's workspace to a 2D plane. Control confined within such a limited area diminishes the applicability of the algorithm in construction sites. We address this issue by expanding the previous 2D plane workspace of the bucket operation into a 3D space, incorporating cabin swing rotation. By expanding the workspace into 3D, excavators can execute continuous operations without requiring human intervention. To accomplish this objective, distinct targets were established for each joint, facilitating the training of action values for each joint independently, regardless of the progress of other joint learning.