 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Language Models for Out-of-Distribution Recovery in Reinforcement Learning
Paper and Code
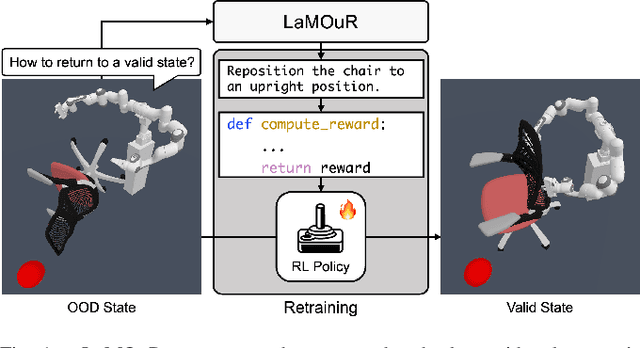



Deep Reinforcement Learning (DRL) has demonstrated strong performance in robotic control but remains susceptible to out-of-distribution (OOD) states, often resulting in unreliable actions and task failure. While previous methods have focused on minimizing or preventing OOD occurrences, they largely neglect recovery once an agent encounters such states. Although the latest research has attempted to address this by guiding agents back to in-distribution states, their reliance on uncertainty estimation hinders scalability in complex environments. To overcome this limitation, we introduce Language Models for Out-of-Distribution Recovery (LaMOuR), which enables recovery learning without relying on uncertainty estimation. LaMOuR generates dense reward codes that guide the agent back to a state where it can successfully perform its original task, leveraging the capabilities of LVLMs in image description, logical reasoning, and code generation. Experimental results show that LaMOuR substantially enhances recovery efficiency across diverse locomotion tasks and even generalizes effectively to complex environments, including humanoid locomotion and mobile manipulation, where existing methods struggle. The code and supplementary materials are available at \href{https://lamour-rl.github.io/}{https://lamour-rl.github.io/}.