 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024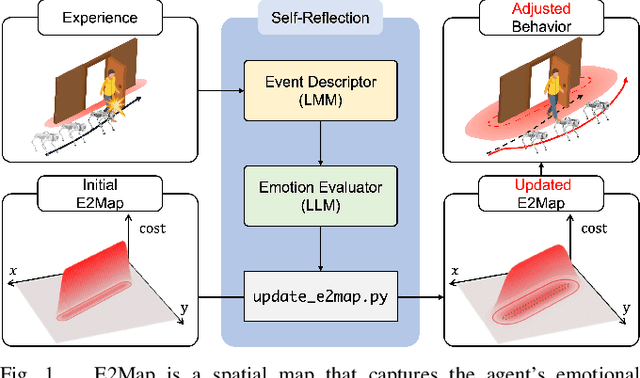



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
Aria-NeRF: Multimodal Egocentric View Synthesis
Nov 11, 2023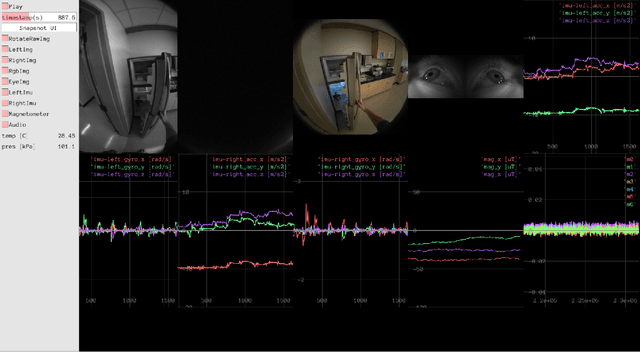
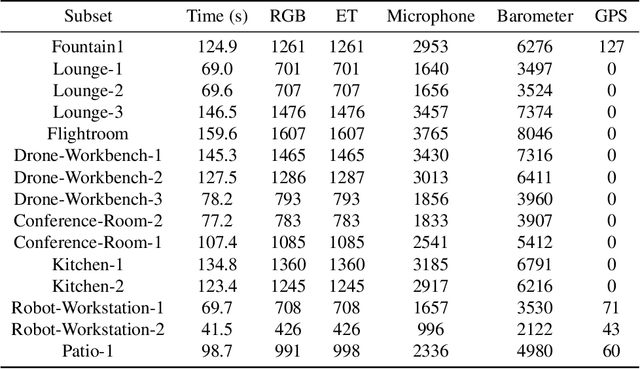

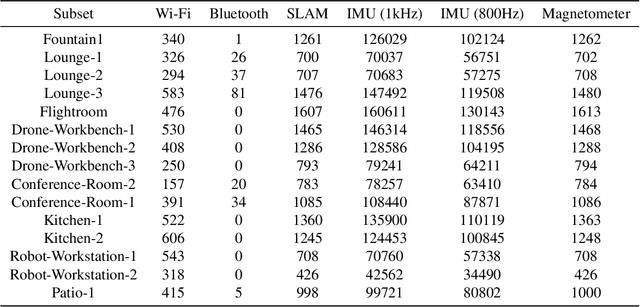
We seek to accelerate research in developing rich, multimodal scene models trained from egocentric data, based on differentiable volumetric ray-tracing inspired by Neural Radiance Fields (NeRFs). The construction of a NeRF-like model from an egocentric image sequence plays a pivotal role in understanding human behavior and holds diverse applications within the realms of VR/AR. Such egocentric NeRF-like models may be used as realistic simulations, contributing significantly to the advancement of intelligent agents capable of executing tasks in the real-world. The future of egocentric view synthesis may lead to novel environment representations going beyond today's NeRFs by augmenting visual data with multimodal sensors such as IMU for egomotion tracking, audio sensors to capture surface texture and human language context, and eye-gaze trackers to infer human attention patterns in the scene. To support and facilitate the development and evaluation of egocentric multimodal scene modeling, we present a comprehensive multimodal egocentric video dataset. This dataset offers a comprehensive collection of sensory data, featuring RGB images, eye-tracking camera footage, audio recordings from a microphone, atmospheric pressure readings from a barometer, positional coordinates from GPS, connectivity details from Wi-Fi and Bluetooth, and information from dual-frequency IMU datasets (1kHz and 800Hz) paired with a magnetometer. The dataset was collected with the Meta Aria Glasses wearable device platform. The diverse data modalities and the real-world context captured within this dataset serve as a robust foundation for furthering our understanding of human behavior and enabling more immersive and intelligent experiences in the realms of VR, AR, and robotics.