 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Multimodal Differential Evolution: A Comprehensive Review and Future Perspectives
Apr 01, 2025Multi-modal optimization involves identifying multiple global and local optima of a function, offering valuable insights into diverse optimal solutions within the search space. Evolutionary algorithms (EAs) excel at finding multiple solutions in a single run, providing a distinct advantage over classical optimization techniques that often require multiple restarts without guarantee of obtaining diverse solutions. Among these EAs, differential evolution (DE) stands out as a powerful and versatile optimizer for continuous parameter spaces. DE has shown significant success in multi-modal optimization by utilizing its population-based search to promote the formation of multiple stable subpopulations, each targeting different optima. Recent advancements in DE for multi-modal optimization have focused on niching methods, parameter adaptation, hybridization with other algorithms including machine learning, and applications across various domains. Given these developments, it is an opportune moment to present a critical review of the latest literature and identify key future research directions. This paper offers a comprehensive overview of recent DE advancements in multimodal optimization, including methods for handling multiple optima, hybridization with EAs, and machine learning, and highlights a range of real-world applications. Additionally, the paper outlines a set of compelling open problems and future research issues from multiple perspectives
GOTLoc: General Outdoor Text-based Localization Using Scene Graph Retrieval with OpenStreetMap
Jan 15, 2025We propose GOTLoc, a robust localization method capable of operating even in outdoor environments where GPS signals are unavailable. The method achieves this robust localization by leveraging comparisons between scene graphs generated from text descriptions and maps. Existing text-based localization studies typically represent maps as point clouds and identify the most similar scenes by comparing embeddings of text and point cloud data. However, point cloud maps have limited scalability as it is impractical to pre-generate maps for all outdoor spaces. Furthermore, their large data size makes it challenging to store and utilize them directly on actual robots. To address these issues, GOTLoc leverages compact data structures, such as scene graphs, to store spatial information, enabling individual robots to carry and utilize large amounts of map data. Additionally, by utilizing publicly available map data, such as OpenStreetMap, which provides global information on outdoor spaces, we eliminate the need for additional effort to create custom map data. For performance evaluation, we utilized the KITTI360Pose dataset in conjunction with corresponding OpenStreetMap data to compare the proposed method with existing approaches. Our results demonstrate that the proposed method achieves accuracy comparable to algorithms relying on point cloud maps. Moreover, in city-scale tests, GOTLoc required significantly less storage compared to point cloud-based methods and completed overall processing within a few seconds, validating its applicability to real-world robotics. Our code is available at https://github.com/donghwijung/GOTLoc.
Point Cloud Structural Similarity-based Underwater Sonar Loop Detection
Sep 21, 2024


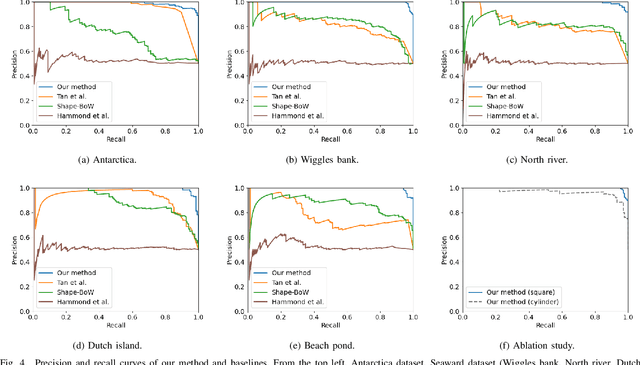
In order to enable autonomous navigation in underwater environments, a map needs to be created in advance using a Simultaneous Localization and Mapping (SLAM) algorithm that utilizes sensors like a sonar. At this time, loop closure is employed to reduce the pose error accumulated during the SLAM process. In the case of loop detection using a sonar, some previous studies have used a method of projecting the 3D point cloud into 2D, then extracting keypoints and matching them. However, during the 2D projection process, data loss occurs due to image resolution, and in monotonous underwater environments such as rivers or lakes, it is difficult to extract keypoints. Additionally, methods that use neural networks or are based on Bag of Words (BoW) have the disadvantage of requiring additional preprocessing tasks, such as training the model in advance or pre-creating a vocabulary. To address these issues, in this paper, we utilize the point cloud obtained from sonar data without any projection to prevent performance degradation due to data loss. Additionally, by calculating the point-wise structural feature map of the point cloud using mathematical formulas and comparing the similarity between point clouds, we eliminate the need for keypoint extraction and ensure that the algorithm can operate in new environments without additional learning or tasks. To evaluate the method, we validated the performance of the proposed algorithm using the Antarctica dataset obtained from deep underwater and the Seaward dataset collected from rivers and lakes. Experimental results show that our proposed method achieves the best loop detection performance in both datasets. Our code is available at https://github.com/donghwijung/point_cloud_structural_similarity_based_underwater_sonar_loop_detection.
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024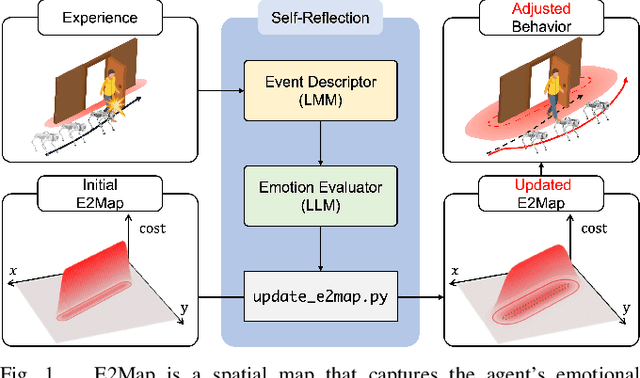



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
No More Potentially Dynamic Objects: Static Point Cloud Map Generation based on 3D Object Detection and Ground Projection
Jul 01, 2024In this paper, we propose an algorithm to generate a static point cloud map based on LiDAR point cloud data. Our proposed pipeline detects dynamic objects using 3D object detectors and projects points of dynamic objects onto the ground. Typically, point cloud data acquired in real-time serves as a snapshot of the surrounding areas containing both static objects and dynamic objects. The static objects include buildings and trees, otherwise, the dynamic objects contain objects such as parked cars that change their position over time. Removing dynamic objects from the point cloud map is crucial as they can degrade the quality and localization accuracy of the map. To address this issue, in this paper, we propose an algorithm that creates a map only consisting of static objects. We apply a 3D object detection algorithm to the point cloud data which are obtained from LiDAR to implement our pipeline. We then stack the points to create the map after performing ground segmentation and projection. As a result, not only we can eliminate currently dynamic objects at the time of map generation but also potentially dynamic objects such as parked vehicles. We validate the performance of our method using two kinds of datasets collected on real roads: KITTI and our dataset. The result demonstrates the capability of our proposal to create an accurate static map excluding dynamic objects from input point clouds. Also, we verified the improved performance of localization using a generated map based on our method.
3D Operation of Autonomous Excavator based on Reinforcement Learning through Independent Reward for Individual Joints
Jun 28, 2024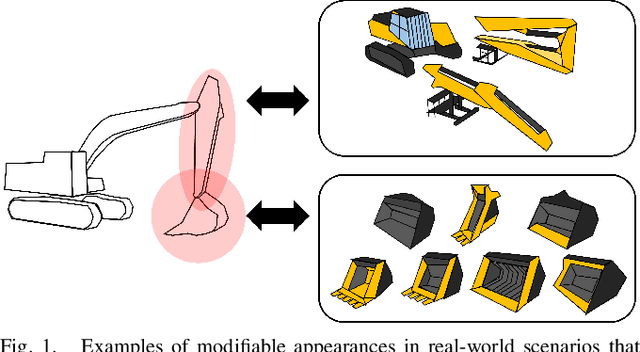
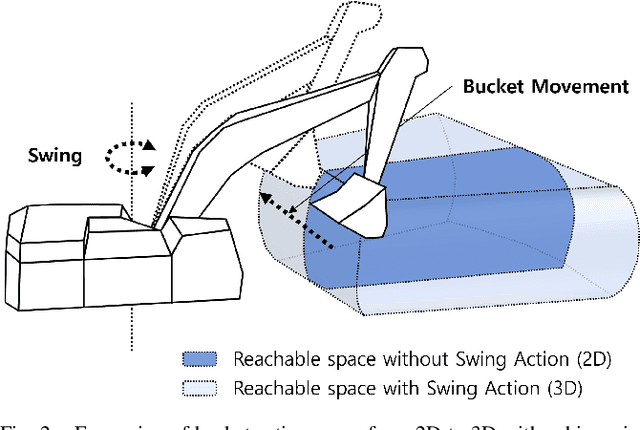
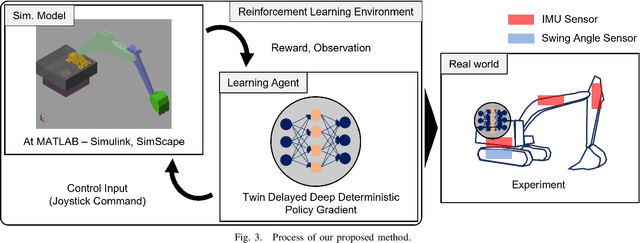

In this paper, we propose a control algorithm based on reinforcement learning, employing independent rewards for each joint to control excavators in a 3D space. The aim of this research is to address the challenges associated with achieving precise control of excavators, which are extensively utilized in construction sites but prove challenging to control with precision due to their hydraulic structures. Traditional methods relied on operator expertise for precise excavator operation, occasionally resulting in safety accidents. Therefore, there have been endeavors to attain precise excavator control through equation-based control algorithms. However, these methods had the limitation of necessitating prior information related to physical values of the excavator, rendering them unsuitable for the diverse range of excavators used in the field. To overcome these limitations, we have explored reinforcement learning-based control methods that do not demand prior knowledge of specific equipment but instead utilize data to train models. Nevertheless, existing reinforcement learning-based methods overlooked cabin swing rotation and confined the bucket's workspace to a 2D plane. Control confined within such a limited area diminishes the applicability of the algorithm in construction sites. We address this issue by expanding the previous 2D plane workspace of the bucket operation into a 3D space, incorporating cabin swing rotation. By expanding the workspace into 3D, excavators can execute continuous operations without requiring human intervention. To accomplish this objective, distinct targets were established for each joint, facilitating the training of action values for each joint independently, regardless of the progress of other joint learning.
MuNES: Multifloor Navigation Including Elevators and Stairs
Feb 07, 2024



We propose a scheme called MuNES for single mapping and trajectory planning including elevators and stairs. Optimized multifloor trajectories are important for optimal interfloor movements of robots. However, given two or more options of moving between floors, it is difficult to select the best trajectory because there are no suitable indoor multifloor maps in the existing methods. To solve this problem, MuNES creates a single multifloor map including elevators and stairs by estimating altitude changes based on pressure data. In addition, the proposed method performs floor-based loop detection for faster and more accurate loop closure. The single multifloor map is then voxelized leaving only the parts needed for trajectory planning. An optimal and realistic multifloor trajectory is generated by exploring the voxels using an A* algorithm based on the proposed cost function, which affects realistic factors. We tested this algorithm using data acquired from around a campus and note that a single accurate multifloor map could be created. Furthermore, optimal and realistic multifloor trajectory could be found by selecting the means of motion between floors between elevators and stairs according to factors such as the starting point, ending point, and elevator waiting time. The code and data used in this work are available at https://github.com/donghwijung/MuNES.
LoRCoN-LO: Long-term Recurrent Convolutional Network-based LiDAR Odometry
Mar 21, 2023


We propose a deep learning-based LiDAR odometry estimation method called LoRCoN-LO that utilizes the long-term recurrent convolutional network (LRCN) structure. The LRCN layer is a structure that can process spatial and temporal information at once by using both CNN and LSTM layers. This feature is suitable for predicting continuous robot movements as it uses point clouds that contain spatial information. Therefore, we built a LoRCoN-LO model using the LRCN layer, and predicted the pose of the robot through this model. For performance verification, we conducted experiments exploiting a public dataset (KITTI). The results of the experiment show that LoRCoN-LO displays accurate odometry prediction in the dataset. The code is available at https://github.com/donghwijung/LoRCoN-LO.
A Robotic Dating Coaching System Leveraging Online Communities Posts
Nov 24, 2020
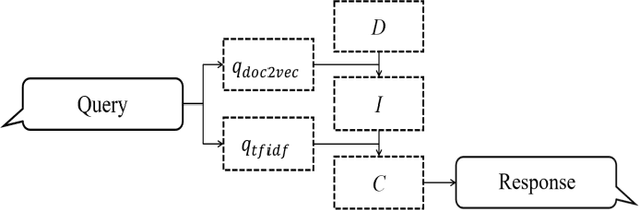
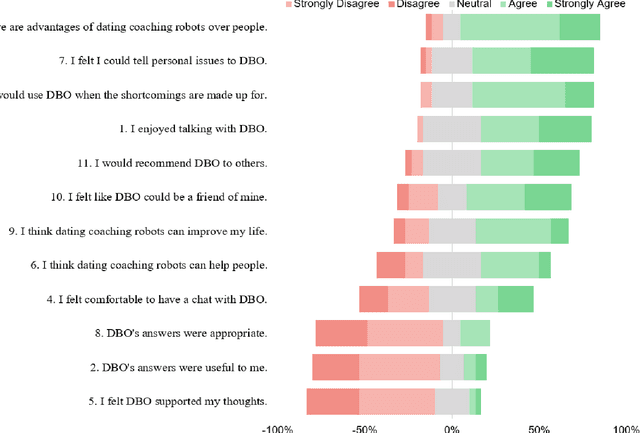
Can a robot be a personal dating coach? Even with the increasing amount of conversational data on the internet, the implementation of conversational robots remains a challenge. In particular, a detailed and professional counseling log is expensive and not publicly accessible. In this paper, we develop a robot dating coaching system leveraging corpus from online communities. We examine people's perceptions of the dating coaching robot with a dialogue module. 97 participants joined to have a conversation with the robot, and 30 of them evaluated the robot. The results indicate that participants thought the robot could become a dating coach while considering the robot is entertaining rather than helpful.