 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL: Distribution-Informed Adaptive Learning of Multi-Task Constraints for Safety-Critical Systems
Jan 30, 2025Safe reinforcement learning has traditionally relied on predefined constraint functions to ensure safety in complex real-world tasks, such as autonomous driving. However, defining these functions accurately for varied tasks is a persistent challenge. Recent research highlights the potential of leveraging pre-acquired task-agnostic knowledge to enhance both safety and sample efficiency in related tasks. Building on this insight, we propose a novel method to learn shared constraint distributions across multiple tasks. Our approach identifies the shared constraints through imitation learning and then adapts to new tasks by adjusting risk levels within these learned distributions. This adaptability addresses variations in risk sensitivity stemming from expert-specific biases, ensuring consistent adherence to general safety principles even with imperfect demonstrations. Our method can be applied to control and navigation domains, including multi-task and meta-task scenarios, accommodating constraints such as maintaining safe distances or adhering to speed limits. Experimental results validate the efficacy of our approach, demonstrating superior safety performance and success rates compared to baselines, all without requiring task-specific constraint definitions. These findings underscore the versatility and practicality of our method across a wide range of real-world tasks.
Traversability-aware Adaptive Optimization for Path Planning and Control in Mountainous Terrain
Apr 04, 2024
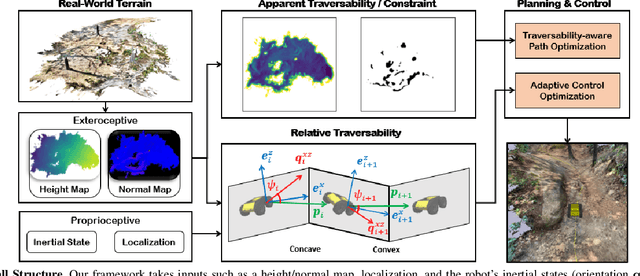
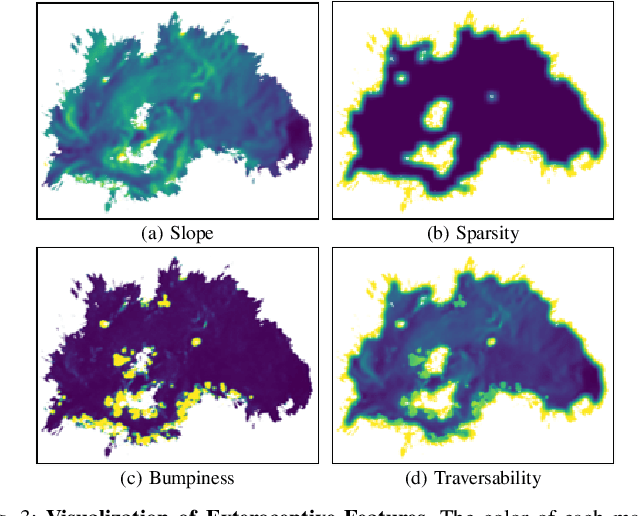

Autonomous navigation in extreme mountainous terrains poses challenges due to the presence of mobility-stressing elements and undulating surfaces, making it particularly difficult compared to conventional off-road driving scenarios. In such environments, estimating traversability solely based on exteroceptive sensors often leads to the inability to reach the goal due to a high prevalence of non-traversable areas. In this paper, we consider traversability as a relative value that integrates the robot's internal state, such as speed and torque to exhibit resilient behavior to reach its goal successfully. We separate traversability into apparent traversability and relative traversability, then incorporate these distinctions in the optimization process of sampling-based planning and motion predictive control. Our method enables the robots to execute the desired behaviors more accurately while avoiding hazardous regions and getting stuck. Experiments conducted on simulation with 27 diverse types of mountainous terrain and real-world demonstrate the robustness of the proposed framework, with increasingly better performance observed in more complex environments.
Learning Multi-Task Transferable Rewards via Variational Inverse Reinforcement Learning
Jun 19, 2022
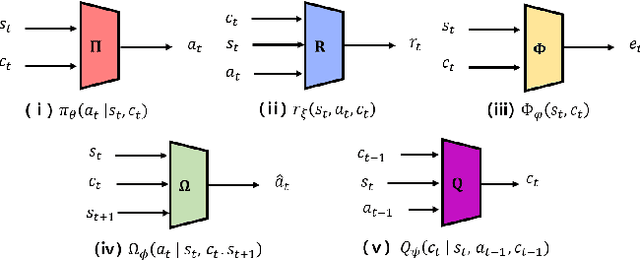


Many robotic tasks are composed of a lot of temporally correlated sub-tasks in a highly complex environment. It is important to discover situational intentions and proper actions by deliberating on temporal abstractions to solve problems effectively. To understand the intention separated from changing task dynamics, we extend an empowerment-based regularization technique to situations with multiple tasks based on the framework of a generative adversarial network. Under the multitask environments with unknown dynamics, we focus on learning a reward and policy from the unlabeled expert examples. In this study, we define situational empowerment as the maximum of mutual information representing how an action conditioned on both a certain state and sub-task affects the future. Our proposed method derives the variational lower bound of the situational mutual information to optimize it. We simultaneously learn the transferable multi-task reward function and policy by adding an induced term to the objective function. By doing so, the multi-task reward function helps to learn a robust policy for environmental change. We validate the advantages of our approach on multi-task learning and multi-task transfer learning. We demonstrate our proposed method has the robustness of both randomness and changing task dynamics. Finally, we prove that our method has significantly better performance and data efficiency than existing imitation learning methods on various benchmarks.
GINK: Graph-based Interaction-aware Kinodynamic Planning via Reinforcement Learning for Autonomous Driving
Jun 03, 2022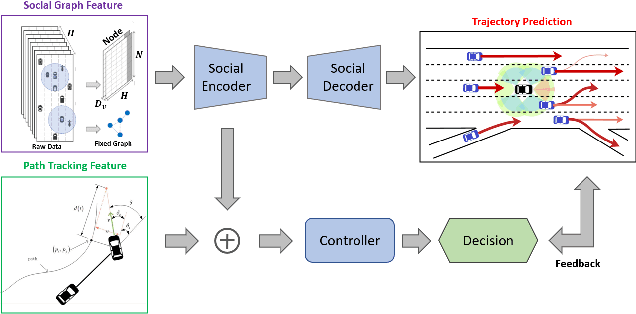
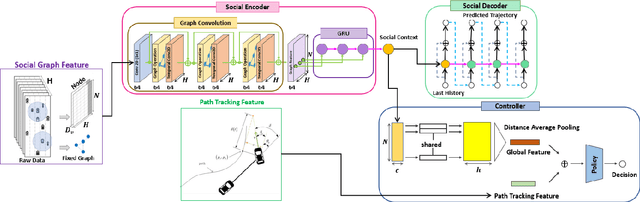


There are many challenges in applying deep reinforcement learning (DRL) to autonomous driving in a structured environment such as an urban area. This is because the massive traffic flows moving along the road network change dynamically. It is a key factor to detect changes in the intentions of surrounding vehicles and quickly find a response strategy. In this paper, we suggest a new framework that effectively combines graph-based intention representation learning and reinforcement learning for kinodynamic planning. Specifically, the movement of dynamic agents is expressed as a graph. The spatio-temporal locality of node features is conserved and the features are aggregated by considering the interaction between adjacent nodes. We simultaneously learn motion planner and controller that share the aggregated information via a safe RL framework. We intuitively interpret a given situation with predicted trajectories to generate additional cost signals. The dense cost signals encourage the policy to be safe for dynamic risk. Moreover, by utilizing the data obtained through the direct rollout of learned policy, robust intention inference is achieved for various situations encountered in training. We set up a navigation scenario in which various situations exist by using CARLA, an urban driving simulator. The experiments show the state-of-the-art performance of our approach compared to the existing baselines.