 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025
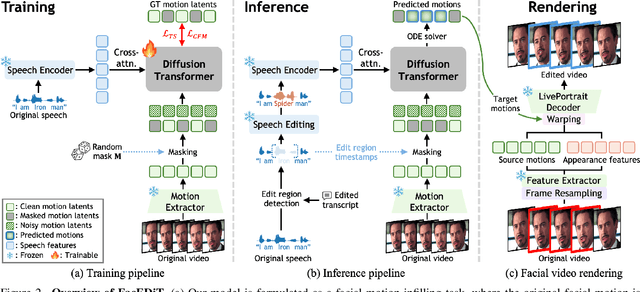


Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
CA^2ST: Cross-Attention in Audio, Space, and Time for Holistic Video Recognition
Mar 30, 2025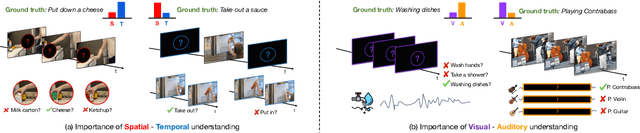
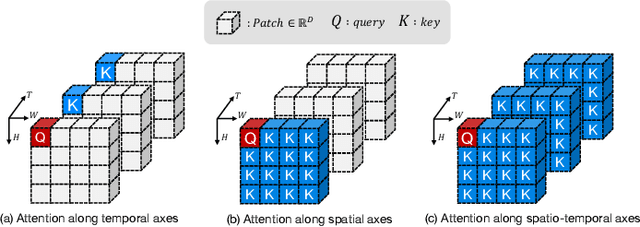
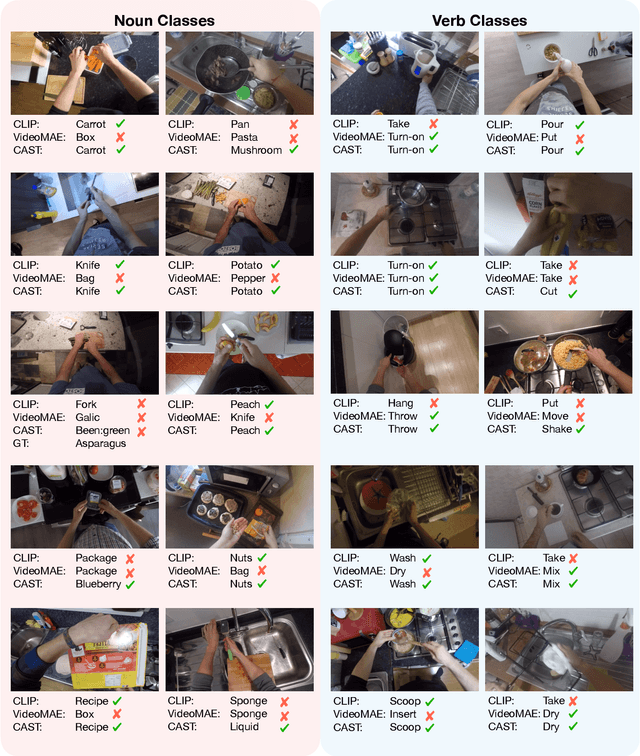
We propose Cross-Attention in Audio, Space, and Time (CA^2ST), a transformer-based method for holistic video recognition. Recognizing actions in videos requires both spatial and temporal understanding, yet most existing models lack a balanced spatio-temporal understanding of videos. To address this, we propose a novel two-stream architecture, called Cross-Attention in Space and Time (CAST), using only RGB input. In each layer of CAST, Bottleneck Cross-Attention (B-CA) enables spatial and temporal experts to exchange information and make synergistic predictions. For holistic video understanding, we extend CAST by integrating an audio expert, forming Cross-Attention in Visual and Audio (CAVA). We validate the CAST on benchmarks with different characteristics, EPIC-KITCHENS-100, Something-Something-V2, and Kinetics-400, consistently showing balanced performance. We also validate the CAVA on audio-visual action recognition benchmarks, including UCF-101, VGG-Sound, KineticsSound, and EPIC-SOUNDS. With a favorable performance of CAVA across these datasets, we demonstrate the effective information exchange among multiple experts within the B-CA module. In summary, CA^2ST combines CAST and CAVA by employing spatial, temporal, and audio experts through cross-attention, achieving balanced and holistic video understanding.