 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA^2ST: Cross-Attention in Audio, Space, and Time for Holistic Video Recognition
Mar 30, 2025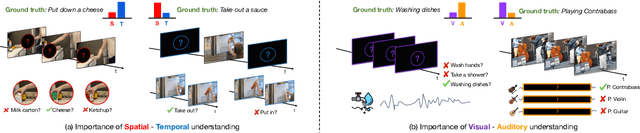
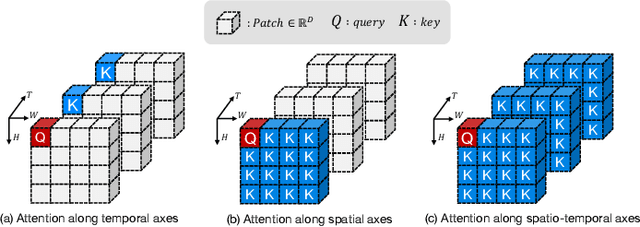
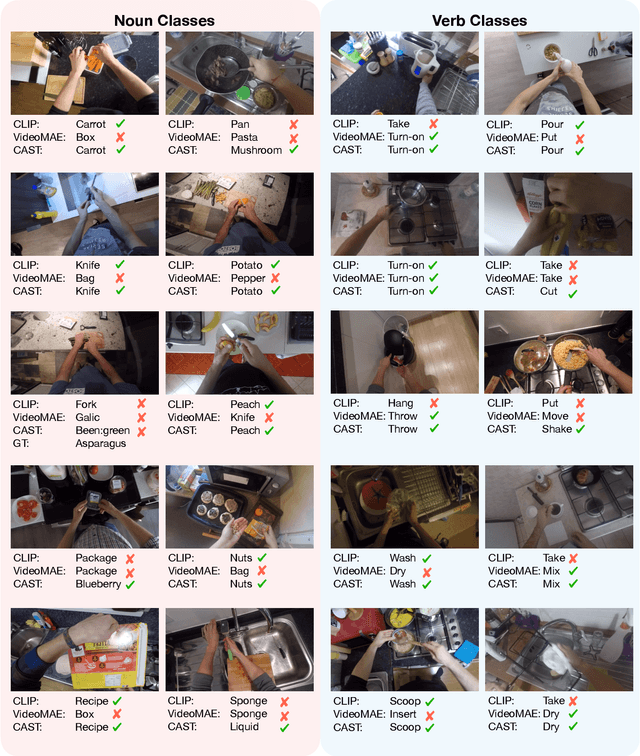
We propose Cross-Attention in Audio, Space, and Time (CA^2ST), a transformer-based method for holistic video recognition. Recognizing actions in videos requires both spatial and temporal understanding, yet most existing models lack a balanced spatio-temporal understanding of videos. To address this, we propose a novel two-stream architecture, called Cross-Attention in Space and Time (CAST), using only RGB input. In each layer of CAST, Bottleneck Cross-Attention (B-CA) enables spatial and temporal experts to exchange information and make synergistic predictions. For holistic video understanding, we extend CAST by integrating an audio expert, forming Cross-Attention in Visual and Audio (CAVA). We validate the CAST on benchmarks with different characteristics, EPIC-KITCHENS-100, Something-Something-V2, and Kinetics-400, consistently showing balanced performance. We also validate the CAVA on audio-visual action recognition benchmarks, including UCF-101, VGG-Sound, KineticsSound, and EPIC-SOUNDS. With a favorable performance of CAVA across these datasets, we demonstrate the effective information exchange among multiple experts within the B-CA module. In summary, CA^2ST combines CAST and CAVA by employing spatial, temporal, and audio experts through cross-attention, achieving balanced and holistic video understanding.
CAST: Cross-Attention in Space and Time for Video Action Recognition
Nov 30, 2023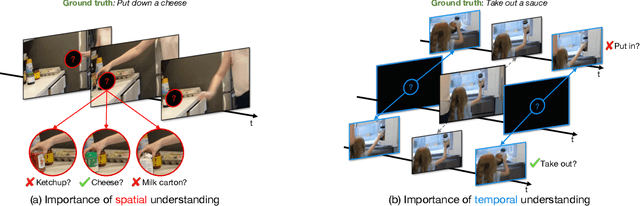
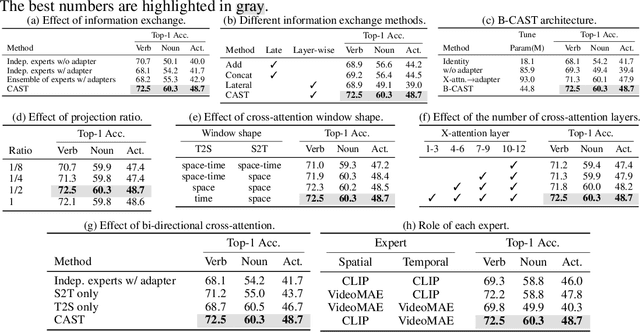
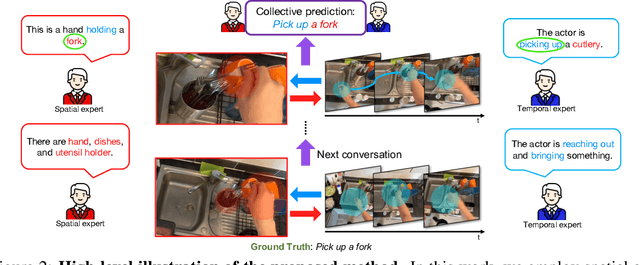
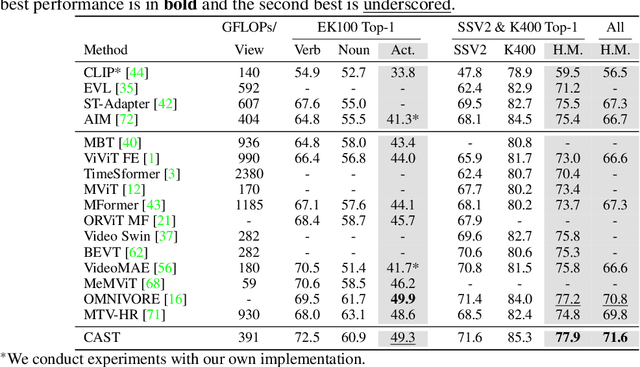
Recognizing human actions in videos requires spatial and temporal understanding. Most existing action recognition models lack a balanced spatio-temporal understanding of videos. In this work, we propose a novel two-stream architecture, called Cross-Attention in Space and Time (CAST), that achieves a balanced spatio-temporal understanding of videos using only RGB input. Our proposed bottleneck cross-attention mechanism enables the spatial and temporal expert models to exchange information and make synergistic predictions, leading to improved performance. We validate the proposed method with extensive experiments on public benchmarks with different characteristics: EPIC-KITCHENS-100, Something-Something-V2, and Kinetics-400. Our method consistently shows favorable performance across these datasets, while the performance of existing methods fluctuates depending on the dataset characteristics.