 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing LLM-driven Social Network: The Chirper.ai Case
Apr 14, 2025Large language models (LLMs) demonstrate the ability to simulate human decision-making processes, enabling their use as agents in modeling sophisticated social networks, both offline and online. Recent research has explored collective behavioral patterns and structural characteristics of LLM agents within simulated networks. However, empirical comparisons between LLM-driven and human-driven online social networks remain scarce, limiting our understanding of how LLM agents differ from human users. This paper presents a large-scale analysis of Chirper.ai, an X/Twitter-like social network entirely populated by LLM agents, comprising over 65,000 agents and 7.7 million AI-generated posts. For comparison, we collect a parallel dataset from Mastodon, a human-driven decentralized social network, with over 117,000 users and 16 million posts. We examine key differences between LLM agents and humans in posting behaviors, abusive content, and social network structures. Our findings provide critical insights into the evolving landscape of online social network analysis in the AI era, offering a comprehensive profile of LLM agents in social simulations.
Exploring the Capability of ChatGPT to Reproduce Human Labels for Social Computing Tasks (Extended Version)
Jul 08, 2024



Harnessing the potential of large language models (LLMs) like ChatGPT can help address social challenges through inclusive, ethical, and sustainable means. In this paper, we investigate the extent to which ChatGPT can annotate data for social computing tasks, aiming to reduce the complexity and cost of undertaking web research. To evaluate ChatGPT's potential, we re-annotate seven datasets using ChatGPT, covering topics related to pressing social issues like COVID-19 misinformation, social bot deception, cyberbully, clickbait news, and the Russo-Ukrainian War. Our findings demonstrate that ChatGPT exhibits promise in handling these data annotation tasks, albeit with some challenges. Across the seven datasets, ChatGPT achieves an average annotation F1-score of 72.00%. Its performance excels in clickbait news annotation, correctly labeling 89.66% of the data. However, we also observe significant variations in performance across individual labels. Our study reveals predictable patterns in ChatGPT's annotation performance. Thus, we propose GPT-Rater, a tool to predict if ChatGPT can correctly label data for a given annotation task. Researchers can use this to identify where ChatGPT might be suitable for their annotation requirements. We show that GPT-Rater effectively predicts ChatGPT's performance. It performs best on a clickbait headlines dataset by achieving an average F1-score of 95.00%. We believe that this research opens new avenues for analysis and can reduce barriers to engaging in social computing research.
APT-Pipe: An Automatic Prompt-Tuning Tool for Social Computing Data Annotation
Feb 08, 2024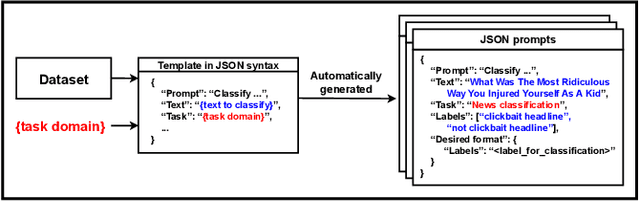

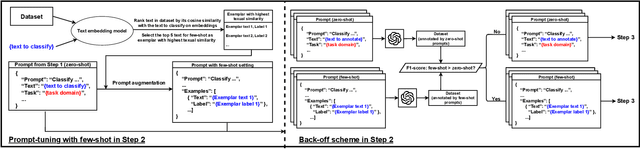
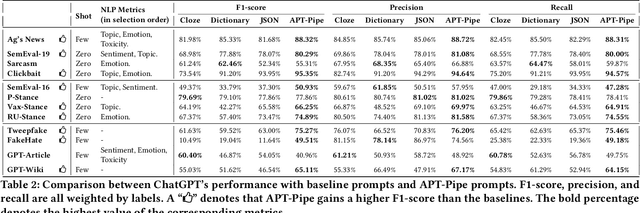
Recent research has highlighted the potential of LLM applications, like ChatGPT, for performing label annotation on social computing text. However, it is already well known that performance hinges on the quality of the input prompts. To address this, there has been a flurry of research into prompt tuning -- techniques and guidelines that attempt to improve the quality of prompts. Yet these largely rely on manual effort and prior knowledge of the dataset being annotated. To address this limitation, we propose APT-Pipe, an automated prompt-tuning pipeline. APT-Pipe aims to automatically tune prompts to enhance ChatGPT's text classification performance on any given dataset. We implement APT-Pipe and test it across twelve distinct text classification datasets. We find that prompts tuned by APT-Pipe help ChatGPT achieve higher weighted F1-score on nine out of twelve experimented datasets, with an improvement of 7.01% on average. We further highlight APT-Pipe's flexibility as a framework by showing how it can be extended to support additional tuning mechanisms.
Can ChatGPT Reproduce Human-Generated Labels? A Study of Social Computing Tasks
Apr 22, 2023



The release of ChatGPT has uncovered a range of possibilities whereby large language models (LLMs) can substitute human intelligence. In this paper, we seek to understand whether ChatGPT has the potential to reproduce human-generated label annotations in social computing tasks. Such an achievement could significantly reduce the cost and complexity of social computing research. As such, we use ChatGPT to relabel five seminal datasets covering stance detection (2x), sentiment analysis, hate speech, and bot detection. Our results highlight that ChatGPT does have the potential to handle these data annotation tasks, although a number of challenges remain. ChatGPT obtains an average accuracy 0.609. Performance is highest for the sentiment analysis dataset, with ChatGPT correctly annotating 64.9% of tweets. Yet, we show that performance varies substantially across individual labels. We believe this work can open up new lines of analysis and act as a basis for future research into the exploitation of ChatGPT for human annotation tasks.
Twitter Dataset for 2022 Russo-Ukrainian Crisis
Mar 06, 2022



Online Social Networks (OSNs) play a significant role in information sharing during a crisis. The data collected during such a crisis can reflect the large scale public opinions and sentiment. In addition, OSN data can also be used to study different campaigns that are employed by various entities to engineer public opinions. Such information sharing campaigns can range from spreading factual information to propaganda and misinformation. We provide a Twitter dataset of the 2022 Russo-Ukrainian conflict. In the first release, we share over 1.6 million tweets shared during the 1st week of the crisis.