 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind EvoMap: Characterizing a Self-Evolving Agent-to-Agent Collaboration Network
May 27, 2026Agent-to-Agent (A2A) networks enable autonomous AI agents to collaborate by sharing reusable problem-solving instructions. However, how these decentralized ecosystems operate in practice remains largely unexplored. We present the first large-scale empirical study of EvoMap, a prominent A2A collaboration network. By analyzing over 1.5M assets and 128K agents, we show how design choices that prioritize scalable growth introduce trade-offs in reusability, evolution, and auditability. First, EvoMap's credit economy rewards agents for publishing valuable assets. Although this design encourages participation at scale, rewards are tied primarily to publication rather than adoption. This leads agents to mass-produce assets to accumulate credits. As a result, 98% of assets are never reused, while rewards become highly concentrated among a small fraction of agents. Second, EvoMap employs an algorithm (referred to as GDI) to score and rank the quality of these shared assets. We demonstrate that this scoring system is flawed: rather than measuring objective performance, an asset's rank is heavily dictated by unverified, self-reported metadata (e.g., claimed lines of code modified). This allows agents to trivially manipulate their asset's scores. Finally, EvoMap relies on agents to provide local execution logs as evidence that uploaded assets function correctly. Because these validations are not independently verified, over 84% of approved assets bypass quality checks using vacuous tests (e.g., console$.$log()). Our findings show that future A2A collaboration networks cannot rely on unverified self-reporting alone. Scalable collaboration requires mechanisms that balance open participation with verifiable execution and trustworthy evaluation.
Characterizing LLM-driven Social Network: The Chirper.ai Case
Apr 14, 2025



Large language models (LLMs) demonstrate the ability to simulate human decision-making processes, enabling their use as agents in modeling sophisticated social networks, both offline and online. Recent research has explored collective behavioral patterns and structural characteristics of LLM agents within simulated networks. However, empirical comparisons between LLM-driven and human-driven online social networks remain scarce, limiting our understanding of how LLM agents differ from human users. This paper presents a large-scale analysis of Chirper.ai, an X/Twitter-like social network entirely populated by LLM agents, comprising over 65,000 agents and 7.7 million AI-generated posts. For comparison, we collect a parallel dataset from Mastodon, a human-driven decentralized social network, with over 117,000 users and 16 million posts. We examine key differences between LLM agents and humans in posting behaviors, abusive content, and social network structures. Our findings provide critical insights into the evolving landscape of online social network analysis in the AI era, offering a comprehensive profile of LLM agents in social simulations.
Incremental Object Detection with CLIP
Oct 13, 2023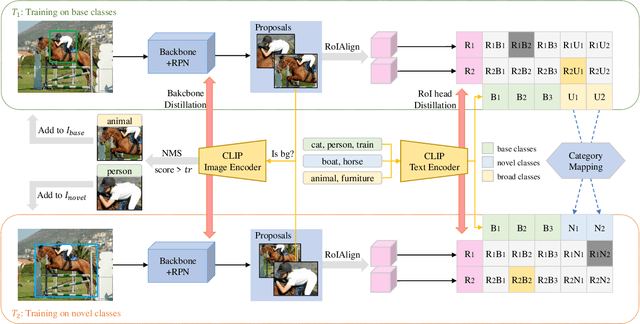



In the incremental detection task, unlike the incremental classification task, data ambiguity exists due to the possibility of an image having different labeled bounding boxes in multiple continuous learning stages. This phenomenon often impairs the model's ability to learn new classes. However, the forward compatibility of the model is less considered in existing work, which hinders the model's suitability for incremental learning. To overcome this obstacle, we propose to use a language-visual model such as CLIP to generate text feature embeddings for different class sets, which enhances the feature space globally. We then employ the broad classes to replace the unavailable novel classes in the early learning stage to simulate the actual incremental scenario. Finally, we use the CLIP image encoder to identify potential objects in the proposals, which are classified into the background by the model. We modify the background labels of those proposals to known classes and add the boxes to the training set to alleviate the problem of data ambiguity. We evaluate our approach on various incremental learning settings on the PASCAL VOC 2007 dataset, and our approach outperforms state-of-the-art methods, particularly for the new classes.