 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Object Detection with CLIP
Paper and Code
Oct 13, 2023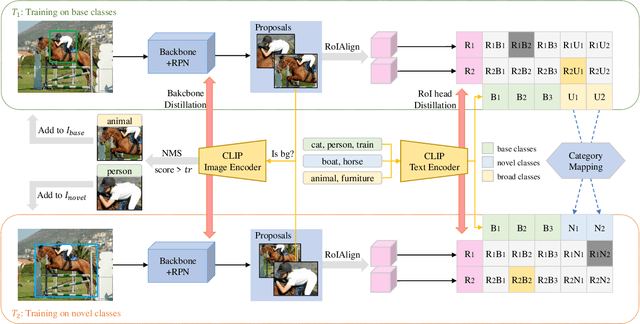



In the incremental detection task, unlike the incremental classification task, data ambiguity exists due to the possibility of an image having different labeled bounding boxes in multiple continuous learning stages. This phenomenon often impairs the model's ability to learn new classes. However, the forward compatibility of the model is less considered in existing work, which hinders the model's suitability for incremental learning. To overcome this obstacle, we propose to use a language-visual model such as CLIP to generate text feature embeddings for different class sets, which enhances the feature space globally. We then employ the broad classes to replace the unavailable novel classes in the early learning stage to simulate the actual incremental scenario. Finally, we use the CLIP image encoder to identify potential objects in the proposals, which are classified into the background by the model. We modify the background labels of those proposals to known classes and add the boxes to the training set to alleviate the problem of data ambiguity. We evaluate our approach on various incremental learning settings on the PASCAL VOC 2007 dataset, and our approach outperforms state-of-the-art methods, particularly for the new classes.