 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARIn: Constraint-Aware and Responsive Inference on Heterogeneous Devices for Single- and Multi-DNN Workloads
Sep 02, 2024


The relentless expansion of deep learning applications in recent years has prompted a pivotal shift toward on-device execution, driven by the urgent need for real-time processing, heightened privacy concerns, and reduced latency across diverse domains. This article addresses the challenges inherent in optimising the execution of deep neural networks (DNNs) on mobile devices, with a focus on device heterogeneity, multi-DNN execution, and dynamic runtime adaptation. We introduce CARIn, a novel framework designed for the optimised deployment of both single- and multi-DNN applications under user-defined service-level objectives. Leveraging an expressive multi-objective optimisation framework and a runtime-aware sorting and search algorithm (RASS) as the MOO solver, CARIn facilitates efficient adaptation to dynamic conditions while addressing resource contention issues associated with multi-DNN execution. Notably, RASS generates a set of configurations, anticipating subsequent runtime adaptation, ensuring rapid, low-overhead adjustments in response to environmental fluctuations. Extensive evaluation across diverse tasks, including text classification, scene recognition, and face analysis, showcases the versatility of CARIn across various model architectures, such as Convolutional Neural Networks and Transformers, and realistic use cases. We observe a substantial enhancement in the fair treatment of the problem's objectives, reaching 1.92x when compared to single-model designs and up to 10.69x in contrast to the state-of-the-art OODIn framework. Additionally, we achieve a significant gain of up to 4.06x over hardware-unaware designs in multi-DNN applications. Finally, our framework sustains its performance while effectively eliminating the time overhead associated with identifying the optimal design in response to environmental challenges.
Exploring the Performance and Efficiency of Transformer Models for NLP on Mobile Devices
Jun 20, 2023Deep learning (DL) is characterised by its dynamic nature, with new deep neural network (DNN) architectures and approaches emerging every few years, driving the field's advancement. At the same time, the ever-increasing use of mobile devices (MDs) has resulted in a surge of DNN-based mobile applications. Although traditional architectures, like CNNs and RNNs, have been successfully integrated into MDs, this is not the case for Transformers, a relatively new model family that has achieved new levels of accuracy across AI tasks, but poses significant computational challenges. In this work, we aim to make steps towards bridging this gap by examining the current state of Transformers' on-device execution. To this end, we construct a benchmark of representative models and thoroughly evaluate their performance across MDs with different computational capabilities. Our experimental results show that Transformers are not accelerator-friendly and indicate the need for software and hardware optimisations to achieve efficient deployment.
How to Reach Real-Time AI on Consumer Devices? Solutions for Programmable and Custom Architectures
Jun 21, 2021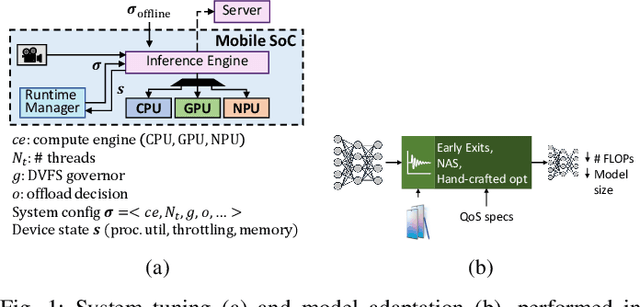
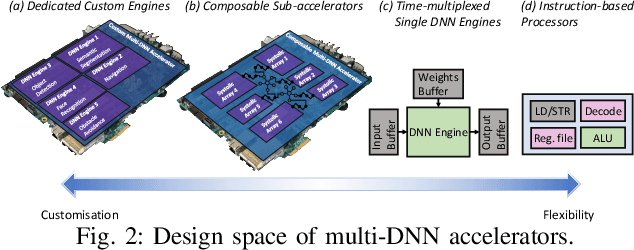
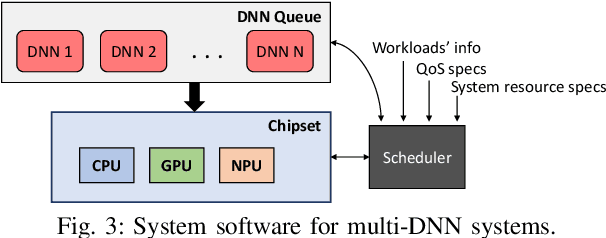
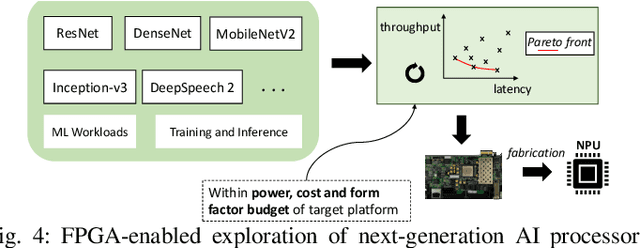
The unprecedented performance of deep neural networks (DNNs) has led to large strides in various Artificial Intelligence (AI) inference tasks, such as object and speech recognition. Nevertheless, deploying such AI models across commodity devices faces significant challenges: large computational cost, multiple performance objectives, hardware heterogeneity and a common need for high accuracy, together pose critical problems to the deployment of DNNs across the various embedded and mobile devices in the wild. As such, we have yet to witness the mainstream usage of state-of-the-art deep learning algorithms across consumer devices. In this paper, we provide preliminary answers to this potentially game-changing question by presenting an array of design techniques for efficient AI systems. We start by examining the major roadblocks when targeting both programmable processors and custom accelerators. Then, we present diverse methods for achieving real-time performance following a cross-stack approach. These span model-, system- and hardware-level techniques, and their combination. Our findings provide illustrative examples of AI systems that do not overburden mobile hardware, while also indicating how they can improve inference accuracy. Moreover, we showcase how custom ASIC- and FPGA-based accelerators can be an enabling factor for next-generation AI applications, such as multi-DNN systems. Collectively, these results highlight the critical need for further exploration as to how the various cross-stack solutions can be best combined in order to bring the latest advances in deep learning close to users, in a robust and efficient manner.
OODIn: An Optimised On-Device Inference Framework for Heterogeneous Mobile Devices
Jun 08, 2021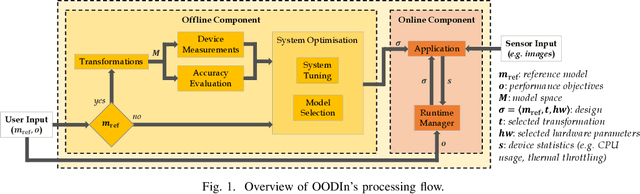
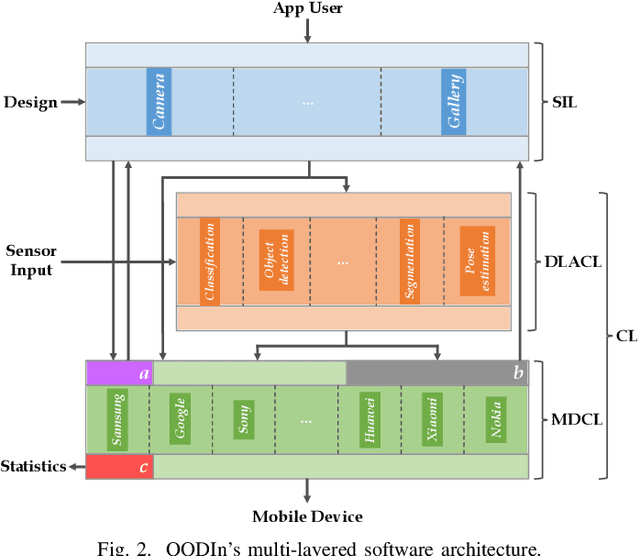
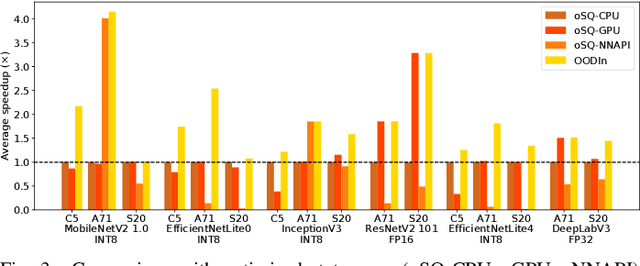
Radical progress in the field of deep learning (DL) has led to unprecedented accuracy in diverse inference tasks. As such, deploying DL models across mobile platforms is vital to enable the development and broad availability of the next-generation intelligent apps. Nevertheless, the wide and optimised deployment of DL models is currently hindered by the vast system heterogeneity of mobile devices, the varying computational cost of different DL models and the variability of performance needs across DL applications. This paper proposes OODIn, a framework for the optimised deployment of DL apps across heterogeneous mobile devices. OODIn comprises a novel DL-specific software architecture together with an analytical framework for modelling DL applications that: (1) counteract the variability in device resources and DL models by means of a highly parametrised multi-layer design; and (2) perform a principled optimisation of both model- and system-level parameters through a multi-objective formulation, designed for DL inference apps, in order to adapt the deployment to the user-specified performance requirements and device capabilities. Quantitative evaluation shows that the proposed framework consistently outperforms status-quo designs across heterogeneous devices and delivers up to 4.3x and 3.5x performance gain over highly optimised platform- and model-aware designs respectively, while effectively adapting execution to dynamic changes in resource availability.