 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTASC++: A Continuously Adaptive Scheduler for Edge-Based Multi-Device Cascade Inference
Dec 05, 2024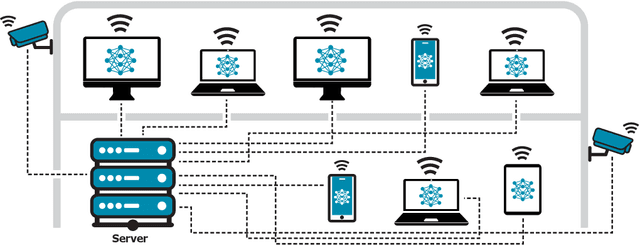
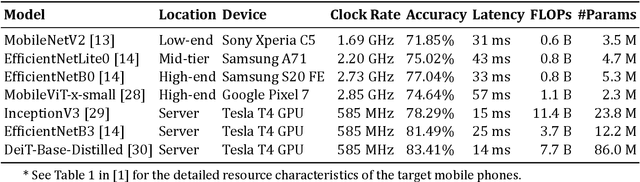
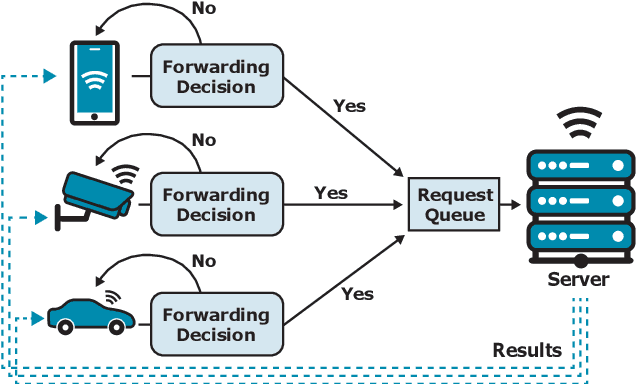
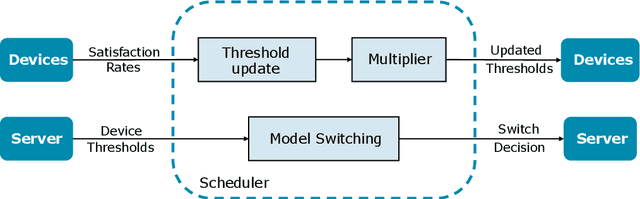
Cascade systems, consisting of a lightweight model processing all samples and a heavier, high-accuracy model refining challenging samples, have become a widely-adopted distributed inference approach to achieving high accuracy and maintaining a low computational burden for mobile and IoT devices. As intelligent indoor environments, like smart homes, continue to expand, a new scenario emerges, the multi-device cascade. In this setting, multiple diverse devices simultaneously utilize a shared heavy model hosted on a server, often situated within or close to the consumer environment. This work introduces MultiTASC++, a continuously adaptive multi-tenancy-aware scheduler that dynamically controls the forwarding decision functions of devices to optimize system throughput while maintaining high accuracy and low latency. Through extensive experimentation in diverse device environments and with varying server-side models, we demonstrate the scheduler's efficacy in consistently maintaining a targeted satisfaction rate while providing the highest available accuracy across different device tiers and workloads of up to 100 devices. This demonstrates its scalability and efficiency in addressing the unique challenges of collaborative DNN inference in dynamic and diverse IoT environments.
MultiTASC: A Multi-Tenancy-Aware Scheduler for Cascaded DNN Inference at the Consumer Edge
Jun 22, 2023
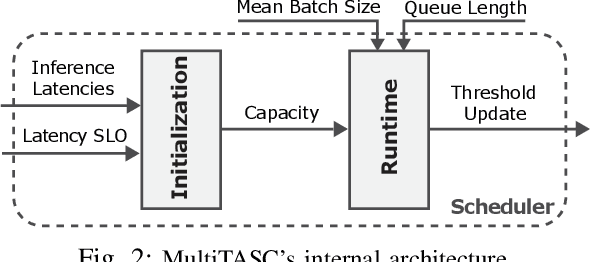

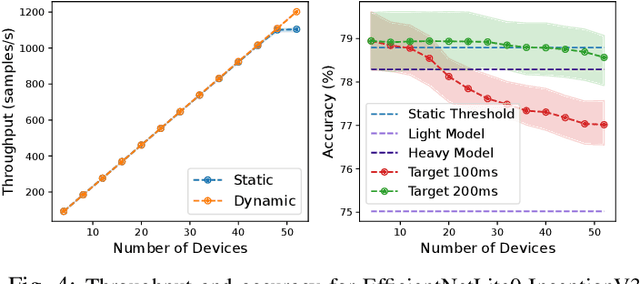
Cascade systems comprise a two-model sequence, with a lightweight model processing all samples and a heavier, higher-accuracy model conditionally refining harder samples to improve accuracy. By placing the light model on the device side and the heavy model on a server, model cascades constitute a widely used distributed inference approach. With the rapid expansion of intelligent indoor environments, such as smart homes, the new setting of Multi-Device Cascade is emerging where multiple and diverse devices are to simultaneously use a shared heavy model on the same server, typically located within or close to the consumer environment. This work presents MultiTASC, a multi-tenancy-aware scheduler that adaptively controls the forwarding decision functions of the devices in order to maximize the system throughput, while sustaining high accuracy and low latency. By explicitly considering device heterogeneity, our scheduler improves the latency service-level objective (SLO) satisfaction rate by 20-25 percentage points (pp) over state-of-the-art cascade methods in highly heterogeneous setups, while serving over 40 devices, showcasing its scalability.
Exploring the Performance and Efficiency of Transformer Models for NLP on Mobile Devices
Jun 20, 2023Deep learning (DL) is characterised by its dynamic nature, with new deep neural network (DNN) architectures and approaches emerging every few years, driving the field's advancement. At the same time, the ever-increasing use of mobile devices (MDs) has resulted in a surge of DNN-based mobile applications. Although traditional architectures, like CNNs and RNNs, have been successfully integrated into MDs, this is not the case for Transformers, a relatively new model family that has achieved new levels of accuracy across AI tasks, but poses significant computational challenges. In this work, we aim to make steps towards bridging this gap by examining the current state of Transformers' on-device execution. To this end, we construct a benchmark of representative models and thoroughly evaluate their performance across MDs with different computational capabilities. Our experimental results show that Transformers are not accelerator-friendly and indicate the need for software and hardware optimisations to achieve efficient deployment.