 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Reach Real-Time AI on Consumer Devices? Solutions for Programmable and Custom Architectures
Paper and Code
Jun 21, 2021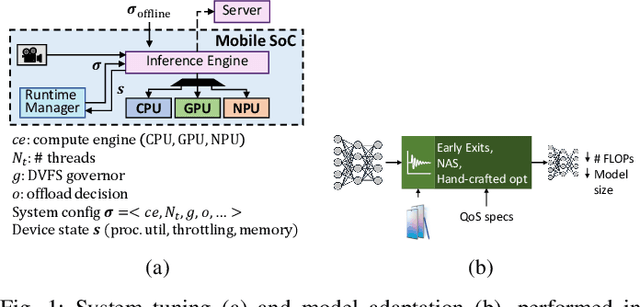
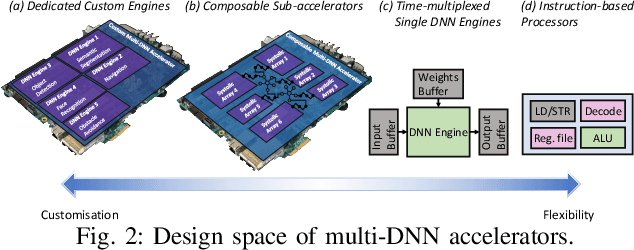
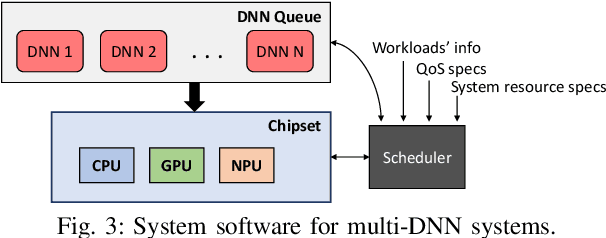
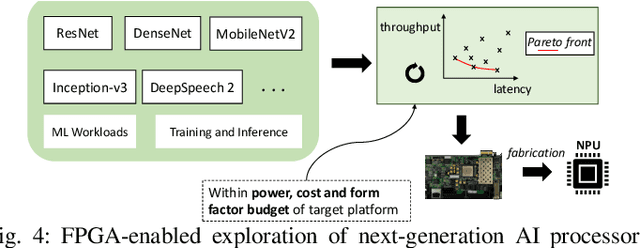
The unprecedented performance of deep neural networks (DNNs) has led to large strides in various Artificial Intelligence (AI) inference tasks, such as object and speech recognition. Nevertheless, deploying such AI models across commodity devices faces significant challenges: large computational cost, multiple performance objectives, hardware heterogeneity and a common need for high accuracy, together pose critical problems to the deployment of DNNs across the various embedded and mobile devices in the wild. As such, we have yet to witness the mainstream usage of state-of-the-art deep learning algorithms across consumer devices. In this paper, we provide preliminary answers to this potentially game-changing question by presenting an array of design techniques for efficient AI systems. We start by examining the major roadblocks when targeting both programmable processors and custom accelerators. Then, we present diverse methods for achieving real-time performance following a cross-stack approach. These span model-, system- and hardware-level techniques, and their combination. Our findings provide illustrative examples of AI systems that do not overburden mobile hardware, while also indicating how they can improve inference accuracy. Moreover, we showcase how custom ASIC- and FPGA-based accelerators can be an enabling factor for next-generation AI applications, such as multi-DNN systems. Collectively, these results highlight the critical need for further exploration as to how the various cross-stack solutions can be best combined in order to bring the latest advances in deep learning close to users, in a robust and efficient manner.