 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Effect of Explicit Interaction Representations on Learning Scene-level Distributions of Human Trajectories
Nov 06, 2025Effectively capturing the joint distribution of all agents in a scene is relevant for predicting the true evolution of the scene and in turn providing more accurate information to the decision processes of autonomous vehicles. While new models have been developed for this purpose in recent years, it remains unclear how to best represent the joint distributions particularly from the perspective of the interactions between agents. Thus far there is no clear consensus on how best to represent interactions between agents; whether they should be learned implicitly from data by neural networks, or explicitly modeled using the spatial and temporal relations that are more grounded in human decision-making. This paper aims to study various means of describing interactions within the same network structure and their effect on the final learned joint distributions. Our findings show that more often than not, simply allowing a network to establish interactive connections between agents based on data has a detrimental effect on performance. Instead, having well defined interactions (such as which agent of an agent pair passes first at an intersection) can often bring about a clear boost in performance.
Out-of-distribution Tests Reveal Compositionality in Chess Transformers
Oct 23, 2025Chess is a canonical example of a task that requires rigorous reasoning and long-term planning. Modern decision Transformers - trained similarly to LLMs - are able to learn competent gameplay, but it is unclear to what extent they truly capture the rules of chess. To investigate this, we train a 270M parameter chess Transformer and test it on out-of-distribution scenarios, designed to reveal failures of systematic generalization. Our analysis shows that Transformers exhibit compositional generalization, as evidenced by strong rule extrapolation: they adhere to fundamental syntactic rules of the game by consistently choosing valid moves even in situations very different from the training data. Moreover, they also generate high-quality moves for OOD puzzles. In a more challenging test, we evaluate the models on variants including Chess960 (Fischer Random Chess) - a variant of chess where starting positions of pieces are randomized. We found that while the model exhibits basic strategy adaptation, they are inferior to symbolic AI algorithms that perform explicit search, but gap is smaller when playing against users on Lichess. Moreover, the training dynamics revealed that the model initially learns to move only its own pieces, suggesting an emergent compositional understanding of the game.
STEP: Structured Training and Evaluation Platform for benchmarking trajectory prediction models
Sep 18, 2025While trajectory prediction plays a critical role in enabling safe and effective path-planning in automated vehicles, standardized practices for evaluating such models remain underdeveloped. Recent efforts have aimed to unify dataset formats and model interfaces for easier comparisons, yet existing frameworks often fall short in supporting heterogeneous traffic scenarios, joint prediction models, or user documentation. In this work, we introduce STEP -- a new benchmarking framework that addresses these limitations by providing a unified interface for multiple datasets, enforcing consistent training and evaluation conditions, and supporting a wide range of prediction models. We demonstrate the capabilities of STEP in a number of experiments which reveal 1) the limitations of widely-used testing procedures, 2) the importance of joint modeling of agents for better predictions of interactions, and 3) the vulnerability of current state-of-the-art models against both distribution shifts and targeted attacks by adversarial agents. With STEP, we aim to shift the focus from the ``leaderboard'' approach to deeper insights about model behavior and generalization in complex multi-agent settings.
Understanding LLMs Requires More Than Statistical Generalization
May 03, 2024The last decade has seen blossoming research in deep learning theory attempting to answer, "Why does deep learning generalize?" A powerful shift in perspective precipitated this progress: the study of overparametrized models in the interpolation regime. In this paper, we argue that another perspective shift is due, since some of the desirable qualities of LLMs are not a consequence of good statistical generalization and require a separate theoretical explanation. Our core argument relies on the observation that AR probabilistic models are inherently non-identifiable: models zero or near-zero KL divergence apart -- thus, equivalent test loss -- can exhibit markedly different behaviors. We support our position with mathematical examples and empirical observations, illustrating why non-identifiability has practical relevance through three case studies: (1) the non-identifiability of zero-shot rule extrapolation; (2) the approximate non-identifiability of in-context learning; and (3) the non-identifiability of fine-tunability. We review promising research directions focusing on LLM-relevant generalization measures, transferability, and inductive biases.
Robust Multi-Modal Density Estimation
Jan 19, 2024

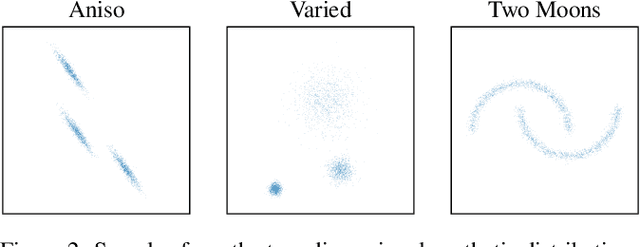

Development of multi-modal, probabilistic prediction models has lead to a need for comprehensive evaluation metrics. While several metrics can characterize the accuracy of machine-learned models (e.g., negative log-likelihood, Jensen-Shannon divergence), these metrics typically operate on probability densities. Applying them to purely sample-based prediction models thus requires that the underlying density function is estimated. However, common methods such as kernel density estimation (KDE) have been demonstrated to lack robustness, while more complex methods have not been evaluated in multi-modal estimation problems. In this paper, we present ROME (RObust Multi-modal density Estimator), a non-parametric approach for density estimation which addresses the challenge of estimating multi-modal, non-normal, and highly correlated distributions. ROME utilizes clustering to segment a multi-modal set of samples into multiple uni-modal ones and then combines simple KDE estimates obtained for individual clusters in a single multi-modal estimate. We compared our approach to state-of-the-art methods for density estimation as well as ablations of ROME, showing that it not only outperforms established methods but is also more robust to a variety of distributions. Our results demonstrate that ROME can overcome the issues of over-fitting and over-smoothing exhibited by other estimators, promising a more robust evaluation of probabilistic machine learning models.
TrajFlow: Learning the Distribution over Trajectories
Apr 11, 2023



Predicting the future behaviour of people remains an open challenge for the development of risk-aware autonomous vehicles. An important aspect of this challenge is effectively capturing the uncertainty which is inherent to human behaviour. This paper studies an approach for probabilistic motion forecasting with improved accuracy in the predicted sample likelihoods. We are able to learn multi-modal distributions over the motions of an agent solely from data, while also being able to provide predictions in real-time. Our approach achieves state-of-the-art results on the inD dataset when evaluated with the standard metrics employed for motion forecasting. Furthermore, our approach also achieves state-of-the-art results when evaluated with respect to the likelihoods it assigns to its generated trajectories. Evaluations on artificial datasets indicate that the distributions learned by our model closely correspond to the true distributions observed in data and are not as prone towards being over-confident in a single outcome in the face of uncertainty.
Rethinking Sharpness-Aware Minimization as Variational Inference
Oct 19, 2022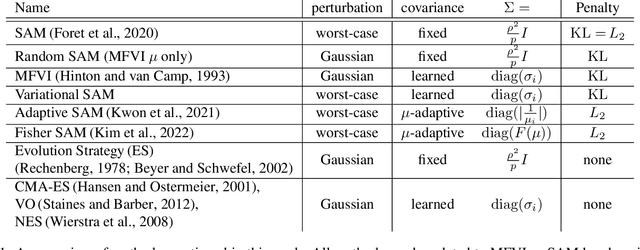
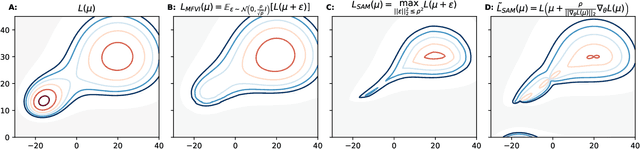
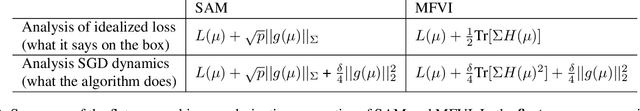
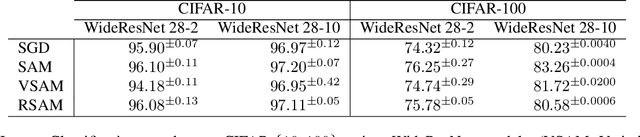
Sharpness-aware minimization (SAM) aims to improve the generalisation of gradient-based learning by seeking out flat minima. In this work, we establish connections between SAM and Mean-Field Variational Inference (MFVI) of neural network parameters. We show that both these methods have interpretations as optimizing notions of flatness, and when using the reparametrisation trick, they both boil down to calculating the gradient at a perturbed version of the current mean parameter. This thinking motivates our study of algorithms that combine or interpolate between SAM and MFVI. We evaluate the proposed variational algorithms on several benchmark datasets, and compare their performance to variants of SAM. Taking a broader perspective, our work suggests that SAM-like updates can be used as a drop-in replacement for the reparametrisation trick.
Depth Without the Magic: Inductive Bias of Natural Gradient Descent
Nov 22, 2021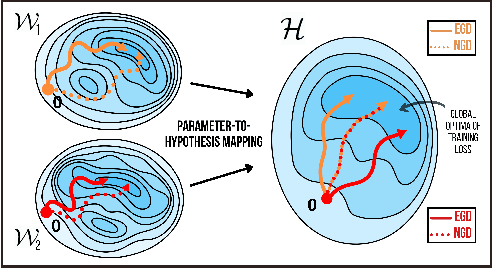
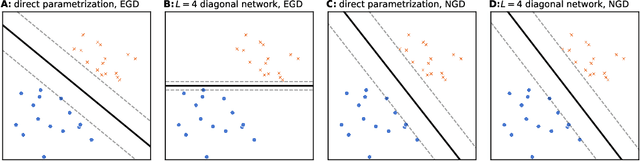
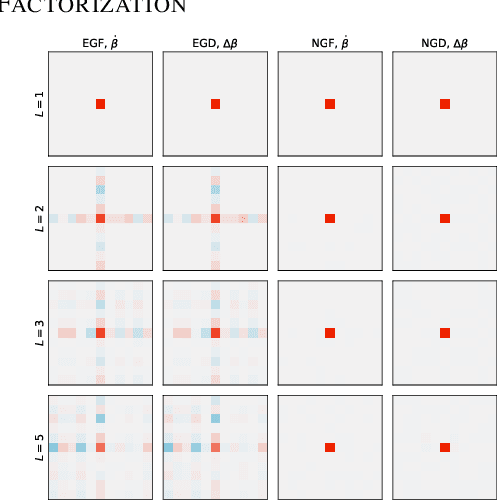
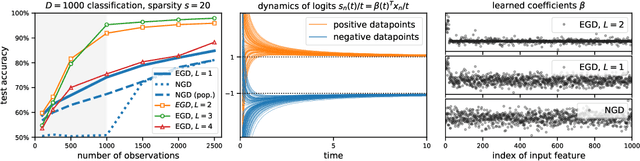
In gradient descent, changing how we parametrize the model can lead to drastically different optimization trajectories, giving rise to a surprising range of meaningful inductive biases: identifying sparse classifiers or reconstructing low-rank matrices without explicit regularization. This implicit regularization has been hypothesised to be a contributing factor to good generalization in deep learning. However, natural gradient descent is approximately invariant to reparameterization, it always follows the same trajectory and finds the same optimum. The question naturally arises: What happens if we eliminate the role of parameterization, which solution will be found, what new properties occur? We characterize the behaviour of natural gradient flow in deep linear networks for separable classification under logistic loss and deep matrix factorization. Some of our findings extend to nonlinear neural networks with sufficient but finite over-parametrization. We demonstrate that there exist learning problems where natural gradient descent fails to generalize, while gradient descent with the right architecture performs well.
Teaching Robots to Grasp Like Humans: An Interactive Approach
Oct 09, 2021


This work investigates how the intricate task of grasping may be learned from humans based on demonstrations and corrections. Due to the complexity of the task, these demonstrations are often slow and even slightly flawed, particularly at moments when multiple aspects (i.e., end-effector movement, orientation, and gripper width) have to be demonstrated at once. Rather than training a person to provide better demonstrations, non-expert users are provided with the ability to interactively modify the dynamics of their initial demonstration through teleoperated corrective feedback. This in turn allows them to teach motions outside of their own physical capabilities. In the end, the goal is to obtain a faster but reliable execution of the task. The presented framework learns the desired movement dynamics based on the current Cartesian Position with Gaussian Processes (GP), resulting in a reactive, time-invariant policy. Using GPs also allows online interactive corrections and active disturbance rejection through epistemic uncertainty minimization. The experimental evaluation of the framework is carried out on a Franka-Emika Panda.
ILoSA: Interactive Learning of Stiffness and Attractors
Mar 04, 2021

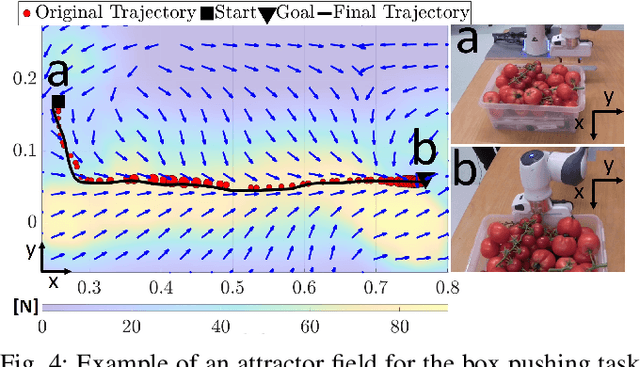

Teaching robots how to apply forces according to our preferences is still an open challenge that has to be tackled from multiple engineering perspectives. This paper studies how to learn variable impedance policies where both the Cartesian stiffness and the attractor can be learned from human demonstrations and corrections with a user-friendly interface. The presented framework, named ILoSA, uses Gaussian Processes for policy learning, identifying regions of uncertainty and allowing interactive corrections, stiffness modulation and active disturbance rejection. The experimental evaluation of the framework is carried out on a Franka-Emika Panda in three separate cases with unique force interaction properties: 1) pulling a plug wherein a sudden force discontinuity occurs upon successful removal of the plug, 2) pushing a box where a sustained force is required to keep the robot in motion, and 3) wiping a whiteboard in which the force is applied perpendicular to the direction of movement.