 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal de Finetti: On the Identification of Invariant Causal Structure in Exchangeable Data
Mar 29, 2022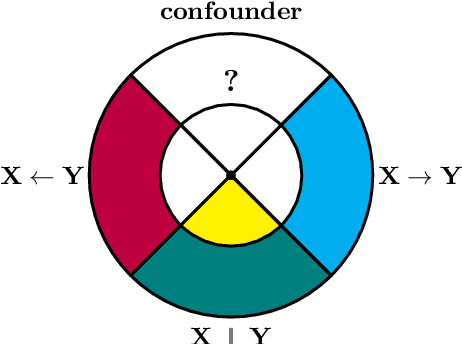
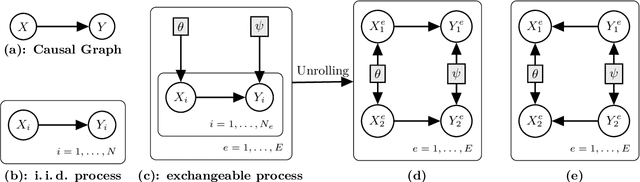
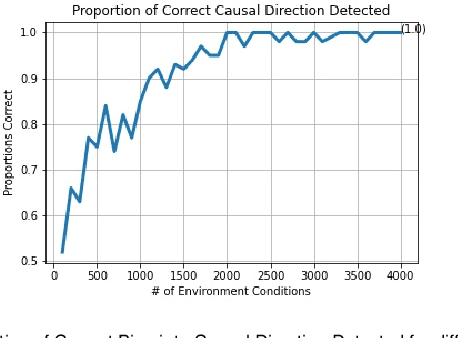
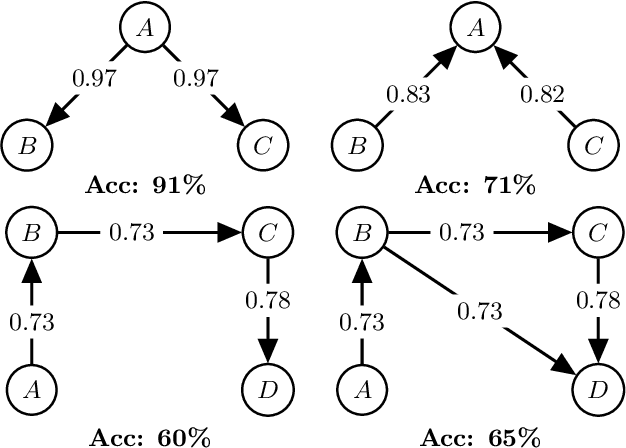
Learning invariant causal structure often relies on conditional independence testing and assumption of independent and identically distributed data. Recent work has explored inferring invariant causal structure using data coming from different environments. These approaches are based on independent causal mechanism (ICM) principle which postulates that the cause mechanism is independent of the effect given cause mechanism. Despite its wide application in machine learning and causal inference, there lacks a statistical formalization of what independent mechanism means. Here we present Causal de Finetti which offers a first statistical formalization of ICM principle.
Autoencoding sensory substitution
Jul 14, 2019



Tens of millions of people live blind, and their number is ever increasing. Visual-to-auditory sensory substitution (SS) encompasses a family of cheap, generic solutions to assist the visually impaired by conveying visual information through sound. The required SS training is lengthy: months of effort is necessary to reach a practical level of adaptation. There are two reasons for the tedious training process: the elongated substituting audio signal, and the disregard for the compressive characteristics of the human hearing system. To overcome these obstacles, we developed a novel class of SS methods, by training deep recurrent autoencoders for image-to-sound conversion. We successfully trained deep learning models on different datasets to execute visual-to-auditory stimulus conversion. By constraining the visual space, we demonstrated the viability of shortened substituting audio signals, while proposing mechanisms, such as the integration of computational hearing models, to optimally convey visual features in the substituting stimulus as perceptually discernible auditory components. We tested our approach in two separate cases. In the first experiment, the author went blindfolded for 5 days, while performing SS training on hand posture discrimination. The second experiment assessed the accuracy of reaching movements towards objects on a table. In both test cases, above-chance-level accuracy was attained after a few hours of training. Our novel SS architecture broadens the horizon of rehabilitation methods engineered for the visually impaired. Further improvements on the proposed model shall yield hastened rehabilitation of the blind and a wider adaptation of SS devices as a consequence.