 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Entropy Is All You Need To Invert the Data Generating Process
Oct 29, 2024



Supervised learning has become a cornerstone of modern machine learning, yet a comprehensive theory explaining its effectiveness remains elusive. Empirical phenomena, such as neural analogy-making and the linear representation hypothesis, suggest that supervised models can learn interpretable factors of variation in a linear fashion. Recent advances in self-supervised learning, particularly nonlinear Independent Component Analysis, have shown that these methods can recover latent structures by inverting the data generating process. We extend these identifiability results to parametric instance discrimination, then show how insights transfer to the ubiquitous setting of supervised learning with cross-entropy minimization. We prove that even in standard classification tasks, models learn representations of ground-truth factors of variation up to a linear transformation. We corroborate our theoretical contribution with a series of empirical studies. First, using simulated data matching our theoretical assumptions, we demonstrate successful disentanglement of latent factors. Second, we show that on DisLib, a widely-used disentanglement benchmark, simple classification tasks recover latent structures up to linear transformations. Finally, we reveal that models trained on ImageNet encode representations that permit linear decoding of proxy factors of variation. Together, our theoretical findings and experiments offer a compelling explanation for recent observations of linear representations, such as superposition in neural networks. This work takes a significant step toward a cohesive theory that accounts for the unreasonable effectiveness of supervised deep learning.
In Search of Forgotten Domain Generalization
Oct 10, 2024Out-of-Domain (OOD) generalization is the ability of a model trained on one or more domains to generalize to unseen domains. In the ImageNet era of computer vision, evaluation sets for measuring a model's OOD performance were designed to be strictly OOD with respect to style. However, the emergence of foundation models and expansive web-scale datasets has obfuscated this evaluation process, as datasets cover a broad range of domains and risk test domain contamination. In search of the forgotten domain generalization, we create large-scale datasets subsampled from LAION -- LAION-Natural and LAION-Rendition -- that are strictly OOD to corresponding ImageNet and DomainNet test sets in terms of style. Training CLIP models on these datasets reveals that a significant portion of their performance is explained by in-domain examples. This indicates that the OOD generalization challenges from the ImageNet era still prevail and that training on web-scale data merely creates the illusion of OOD generalization. Furthermore, through a systematic exploration of combining natural and rendition datasets in varying proportions, we identify optimal mixing ratios for model generalization across these domains. Our datasets and results re-enable meaningful assessment of OOD robustness at scale -- a crucial prerequisite for improving model robustness.
InfoNCE: Identifying the Gap Between Theory and Practice
Jun 28, 2024Previous theoretical work on contrastive learning (CL) with InfoNCE showed that, under certain assumptions, the learned representations uncover the ground-truth latent factors. We argue these theories overlook crucial aspects of how CL is deployed in practice. Specifically, they assume that within a positive pair, all latent factors either vary to a similar extent, or that some do not vary at all. However, in practice, positive pairs are often generated using augmentations such as strong cropping to just a few pixels. Hence, a more realistic assumption is that all latent factors change, with a continuum of variability across these factors. We introduce AnInfoNCE, a generalization of InfoNCE that can provably uncover the latent factors in this anisotropic setting, broadly generalizing previous identifiability results in CL. We validate our identifiability results in controlled experiments and show that AnInfoNCE increases the recovery of previously collapsed information in CIFAR10 and ImageNet, albeit at the cost of downstream accuracy. Additionally, we explore and discuss further mismatches between theoretical assumptions and practical implementations, including extensions to hard negative mining and loss ensembles.
Provable Compositional Generalization for Object-Centric Learning
Oct 09, 2023



Learning representations that generalize to novel compositions of known concepts is crucial for bridging the gap between human and machine perception. One prominent effort is learning object-centric representations, which are widely conjectured to enable compositional generalization. Yet, it remains unclear when this conjecture will be true, as a principled theoretical or empirical understanding of compositional generalization is lacking. In this work, we investigate when compositional generalization is guaranteed for object-centric representations through the lens of identifiability theory. We show that autoencoders that satisfy structural assumptions on the decoder and enforce encoder-decoder consistency will learn object-centric representations that provably generalize compositionally. We validate our theoretical result and highlight the practical relevance of our assumptions through experiments on synthetic image data.
CNN-based regularisation for CT image reconstructions
Jan 22, 2022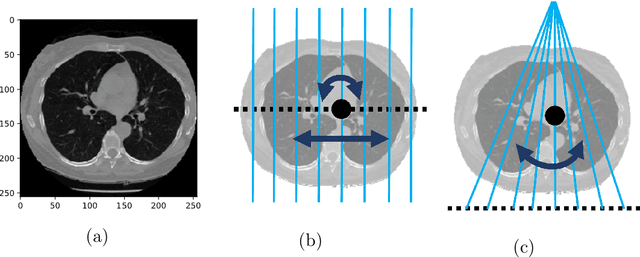
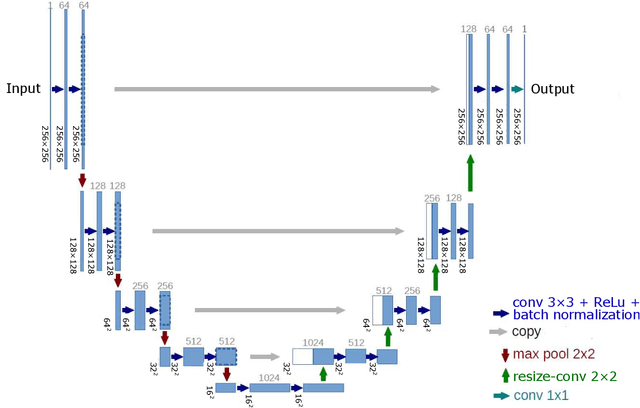
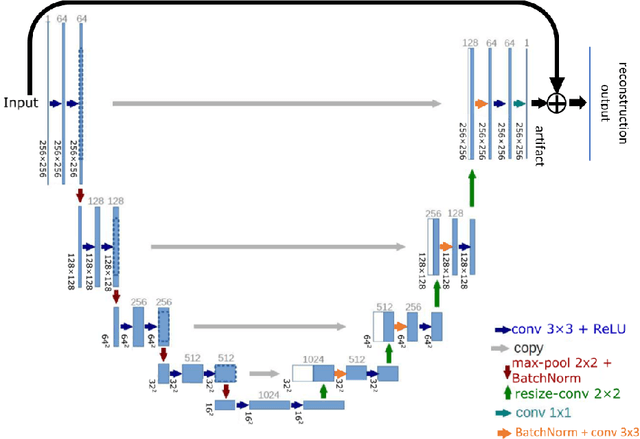
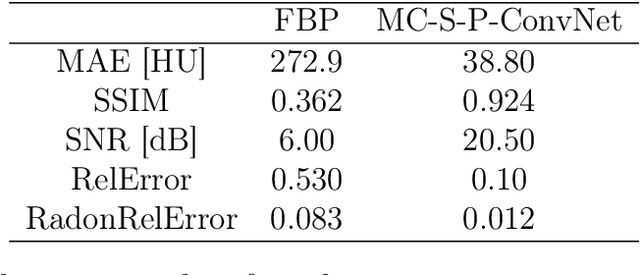
X-ray computed tomographic infrastructures are medical imaging modalities that rely on the acquisition of rays crossing examined objects while measuring their intensity decrease. Physical measurements are post-processed by mathematical reconstruction algorithms that may offer weaker or top-notch consistency guarantees on the computed volumetric field. Superior results are provided on the account of an abundance of low-noise measurements being supplied. Nonetheless, such a scanning process would expose the examined body to an undesirably large-intensity and long-lasting ionising radiation, imposing severe health risks. One main objective of the ongoing research is the reduction of the number of projections while keeping the quality performance stable. Due to the under-sampling, the noise occurring inherently because of photon-electron interactions is now supplemented by reconstruction artifacts. Recently, deep learning methods, especially fully convolutional networks have been extensively investigated and proven to be efficient in filtering such deviations. In this report algorithms are presented that take as input a slice of a low-quality reconstruction of the volume in question and aim to map it to the reconstruction that is considered ideal, the ground truth. Above that, the first system comprises two additional elements: firstly, it ensures the consistency with the measured sinogram, secondly it adheres to constraints proposed in classical compressive sampling theory. The second one, inspired by classical ways of solving the inverse problem of reconstruction, takes an iterative approach to regularise the hypothesis in the direction of the correct result.