 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Feb 02, 2026Frontier models are transitioning from multimodal large language models (MLLMs) that merely ingest visual information to unified multimodal models (UMMs) capable of native interleaved generation. This shift has sparked interest in using intermediate visualizations as a reasoning aid, akin to human mental imagery. Central to this idea is the ability to form, maintain, and manipulate visual representations in a goal-oriented manner. To evaluate and probe this capability, we develop MentisOculi, a procedural, stratified suite of multi-step reasoning problems amenable to visual solution, tuned to challenge frontier models. Evaluating visual strategies ranging from latent tokens to explicit generated imagery, we find they generally fail to improve performance. Analysis of UMMs specifically exposes a critical limitation: While they possess the textual reasoning capacity to solve a task and can sometimes generate correct visuals, they suffer from compounding generation errors and fail to leverage even ground-truth visualizations. Our findings suggest that despite their inherent appeal, visual thoughts do not yet benefit model reasoning. MentisOculi establishes the necessary foundation to analyze and close this gap across diverse model families.
LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
Feb 17, 2025Scaling laws guide the development of large language models (LLMs) by offering estimates for the optimal balance of model size, tokens, and compute. More recently, loss-to-loss scaling laws that relate losses across pretraining datasets and downstream tasks have emerged as a powerful tool for understanding and improving LLM performance. In this work, we investigate which factors most strongly influence loss-to-loss scaling. Our experiments reveal that the pretraining data and tokenizer determine the scaling trend. In contrast, model size, optimization hyperparameters, and even significant architectural differences, such as between transformer-based models like Llama and state-space models like Mamba, have limited impact. Consequently, practitioners should carefully curate suitable pretraining datasets for optimal downstream performance, while architectures and other settings can be freely optimized for training efficiency.
In Search of Forgotten Domain Generalization
Oct 10, 2024Out-of-Domain (OOD) generalization is the ability of a model trained on one or more domains to generalize to unseen domains. In the ImageNet era of computer vision, evaluation sets for measuring a model's OOD performance were designed to be strictly OOD with respect to style. However, the emergence of foundation models and expansive web-scale datasets has obfuscated this evaluation process, as datasets cover a broad range of domains and risk test domain contamination. In search of the forgotten domain generalization, we create large-scale datasets subsampled from LAION -- LAION-Natural and LAION-Rendition -- that are strictly OOD to corresponding ImageNet and DomainNet test sets in terms of style. Training CLIP models on these datasets reveals that a significant portion of their performance is explained by in-domain examples. This indicates that the OOD generalization challenges from the ImageNet era still prevail and that training on web-scale data merely creates the illusion of OOD generalization. Furthermore, through a systematic exploration of combining natural and rendition datasets in varying proportions, we identify optimal mixing ratios for model generalization across these domains. Our datasets and results re-enable meaningful assessment of OOD robustness at scale -- a crucial prerequisite for improving model robustness.
Does CLIP's Generalization Performance Mainly Stem from High Train-Test Similarity?
Oct 14, 2023
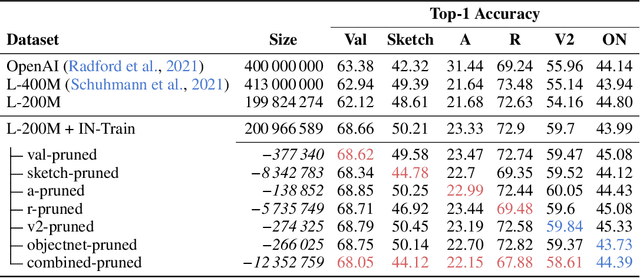


Foundation models like CLIP are trained on hundreds of millions of samples and effortlessly generalize to new tasks and inputs. Out of the box, CLIP shows stellar zero-shot and few-shot capabilities on a wide range of out-of-distribution (OOD) benchmarks, which prior works attribute mainly to today's large and comprehensive training dataset (like LAION). However, it is questionable how meaningful terms like out-of-distribution generalization are for CLIP as it seems likely that web-scale datasets like LAION simply contain many samples that are similar to common OOD benchmarks originally designed for ImageNet. To test this hypothesis, we retrain CLIP on pruned LAION splits that replicate ImageNet's train-test similarity with respect to common OOD benchmarks. While we observe a performance drop on some benchmarks, surprisingly, CLIP's overall performance remains high. This shows that high train-test similarity is insufficient to explain CLIP's OOD performance, and other properties of the training data must drive CLIP to learn more generalizable representations. Additionally, by pruning data points that are dissimilar to the OOD benchmarks, we uncover a 100M split of LAION ($\frac{1}{4}$th of its original size) on which CLIP can be trained to match its original OOD performance.
Compositional Generalization from First Principles
Jul 10, 2023Leveraging the compositional nature of our world to expedite learning and facilitate generalization is a hallmark of human perception. In machine learning, on the other hand, achieving compositional generalization has proven to be an elusive goal, even for models with explicit compositional priors. To get a better handle on compositional generalization, we here approach it from the bottom up: Inspired by identifiable representation learning, we investigate compositionality as a property of the data-generating process rather than the data itself. This reformulation enables us to derive mild conditions on only the support of the training distribution and the model architecture, which are sufficient for compositional generalization. We further demonstrate how our theoretical framework applies to real-world scenarios and validate our findings empirically. Our results set the stage for a principled theoretical study of compositional generalization.