 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes CLIP's Generalization Performance Mainly Stem from High Train-Test Similarity?
Paper and Code

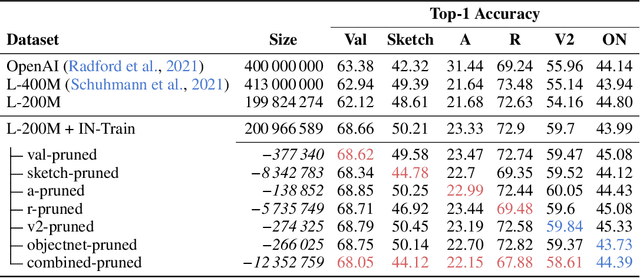


Foundation models like CLIP are trained on hundreds of millions of samples and effortlessly generalize to new tasks and inputs. Out of the box, CLIP shows stellar zero-shot and few-shot capabilities on a wide range of out-of-distribution (OOD) benchmarks, which prior works attribute mainly to today's large and comprehensive training dataset (like LAION). However, it is questionable how meaningful terms like out-of-distribution generalization are for CLIP as it seems likely that web-scale datasets like LAION simply contain many samples that are similar to common OOD benchmarks originally designed for ImageNet. To test this hypothesis, we retrain CLIP on pruned LAION splits that replicate ImageNet's train-test similarity with respect to common OOD benchmarks. While we observe a performance drop on some benchmarks, surprisingly, CLIP's overall performance remains high. This shows that high train-test similarity is insufficient to explain CLIP's OOD performance, and other properties of the training data must drive CLIP to learn more generalizable representations. Additionally, by pruning data points that are dissimilar to the OOD benchmarks, we uncover a 100M split of LAION ($\frac{1}{4}$th of its original size) on which CLIP can be trained to match its original OOD performance.