 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Generalizable Self-driving Policy with Sim-to-real Transfer
Jun 22, 2022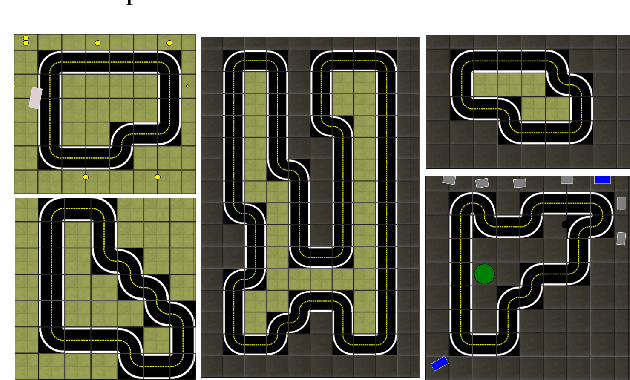
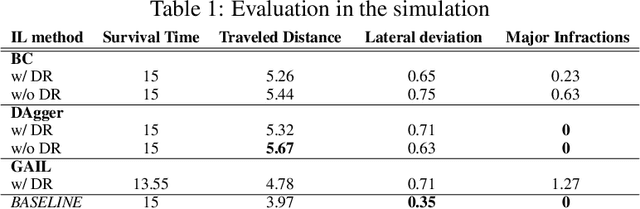

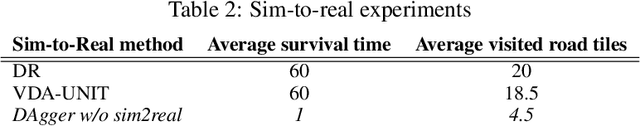
Imitation Learning uses the demonstrations of an expert to uncover the optimal policy and it is suitable for real-world robotics tasks as well. In this case, however, the training of the agent is carried out in a simulation environment due to safety, economic and time constraints. Later, the agent is applied in the real-life domain using sim-to-real methods. In this paper, we apply Imitation Learning methods that solve a robotics task in a simulated environment and use transfer learning to apply these solutions in the real-world environment. Our task is set in the Duckietown environment, where the robotic agent has to follow the right lane based on the input images of a single forward-facing camera. We present three Imitation Learning and two sim-to-real methods capable of achieving this task. A detailed comparison is provided on these techniques to highlight their advantages and disadvantages.
Residual Spatial Attention Network for Retinal Vessel Segmentation
Sep 18, 2020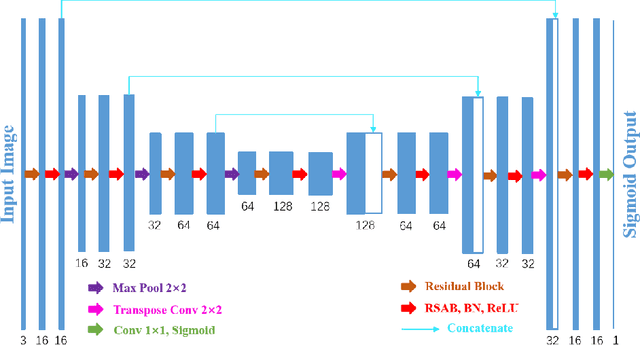
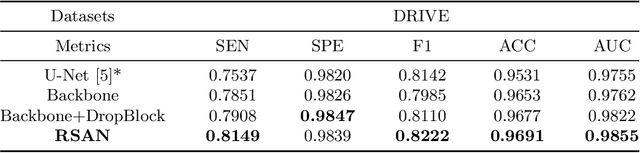

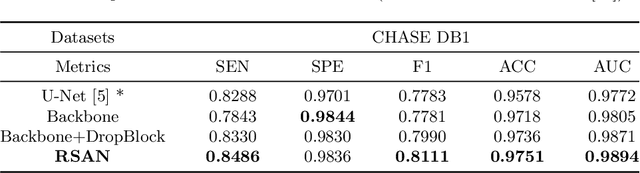
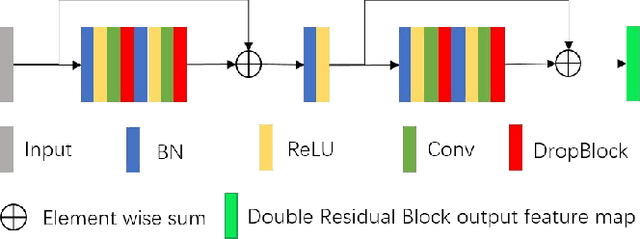
Reliable segmentation of retinal vessels can be employed as a way of monitoring and diagnosing certain diseases, such as diabetes and hypertension, as they affect the retinal vascular structure. In this work, we propose the Residual Spatial Attention Network (RSAN) for retinal vessel segmentation. RSAN employs a modified residual block structure that integrates DropBlock, which can not only be utilized to construct deep networks to extract more complex vascular features, but can also effectively alleviate the overfitting. Moreover, in order to further improve the representation capability of the network, based on this modified residual block, we introduce the spatial attention (SA) and propose the Residual Spatial Attention Block (RSAB) to build RSAN. We adopt the public DRIVE and CHASE DB1 color fundus image datasets to evaluate the proposed RSAN. Experiments show that the modified residual structure and the spatial attention are effective in this work, and our proposed RSAN achieves the state-of-the-art performance.
Channel Attention Residual U-Net for Retinal Vessel Segmentation
Apr 07, 2020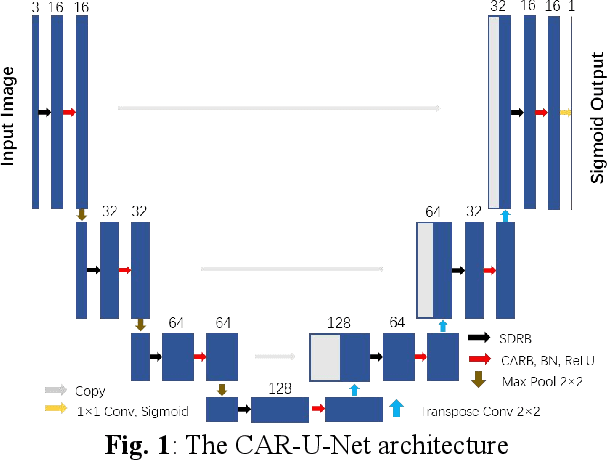
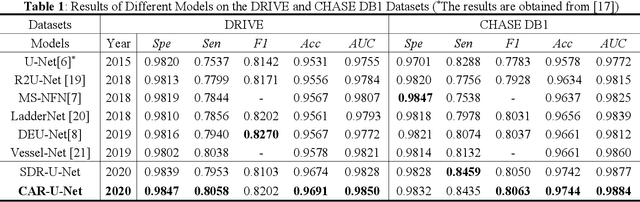

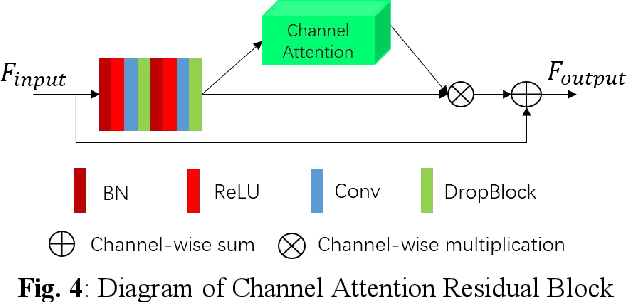
Retinal vessel segmentation is a vital step for the diagnosis of many early eye-related diseases. In this work, we propose a new deep learning model, namely Channel Attention Residual U-Net (CAR-U-Net), to accurately segment retinal vascular and non-vascular pixels. In this model, the channel attention mechanism was introduced into Residual Block and a Channel Attention Residual Block (CARB) was proposed to enhance the discriminative ability of the network by considering the interdependence between the feature channels. Moreover, to prevent the convolutional networks from overfitting, a Structured Dropout Residual Block (SDRB) was proposed, consisting of pre-activated residual block and DropBlock. The results show that our proposed CAR-U-Net has reached the state-of-the-art performance on two publicly available retinal vessel datasets: DRIVE and CHASE DB1.
Dense Residual Network for Retinal Vessel Segmentation
Apr 07, 2020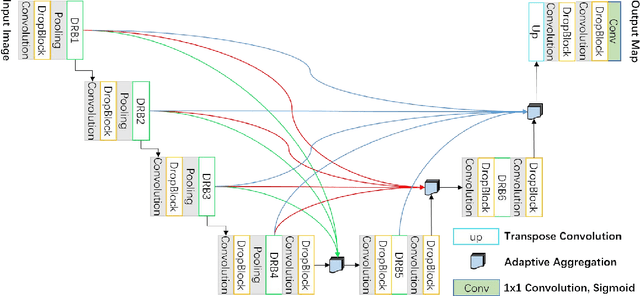
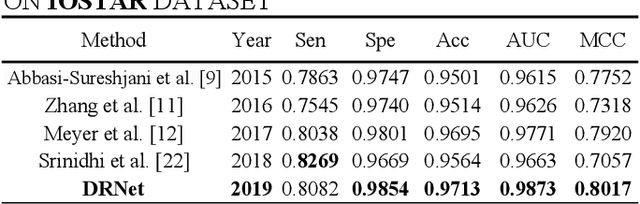
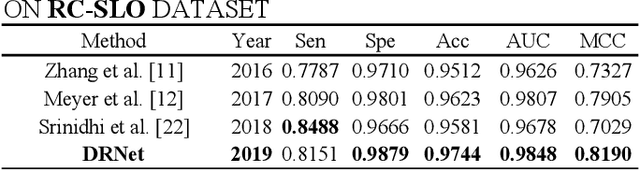
Retinal vessel segmentation plays an imaportant role in the field of retinal image analysis because changes in retinal vascular structure can aid in the diagnosis of diseases such as hypertension and diabetes. In recent research, numerous successful segmentation methods for fundus images have been proposed. But for other retinal imaging modalities, more research is needed to explore vascular extraction. In this work, we propose an efficient method to segment blood vessels in Scanning Laser Ophthalmoscopy (SLO) retinal images. Inspired by U-Net, "feature map reuse" and residual learning, we propose a deep dense residual network structure called DRNet. In DRNet, feature maps of previous blocks are adaptively aggregated into subsequent layers as input, which not only facilitates spatial reconstruction, but also learns more efficiently due to more stable gradients. Furthermore, we introduce DropBlock to alleviate the overfitting problem of the network. We train and test this model on the recent SLO public dataset. The results show that our method achieves the state-of-the-art performance even without data augmentation.
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Apr 07, 2020
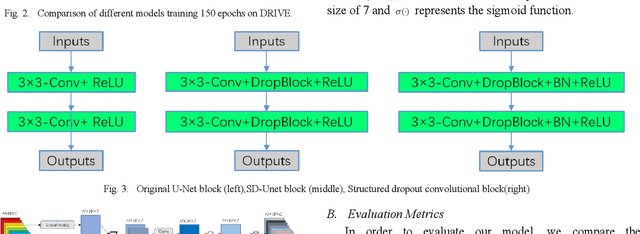
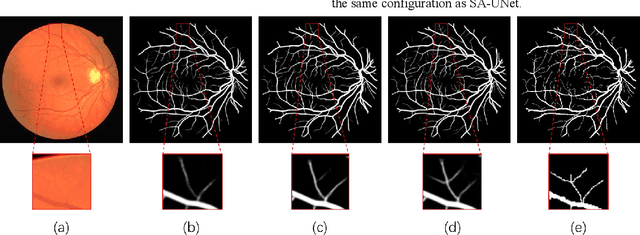

The precise segmentation of retinal blood vessel is of great significance for early diagnosis of eye-related diseases such as diabetes and hypertension. In this work, we propose a lightweight network named Spatial Attention U-Net (SA-UNet) that does not require thousands of annotated training samples and can be utilized in a data augmentation manner to use the available annotated samples more efficiently. SA-UNet introduces a spatial attention module which infers the attention map along the spatial dimension, and then multiply the attention map by the input feature map for adaptive feature refinement. In addition, the proposed network employees a kind of structured dropout convolutional block instead of the original convolutional block of U-Net to prevent the network from overfitting. We evaluate SA-UNet based on two benchmark retinal datasets: the Vascular Extraction (DRIVE) dataset and the Child Heart and Health Study (CHASE_DB1) dataset. The results show that our proposed SA-UNet achieves the state-of-the-art retinal vessel segmentation accuracy on both datasets.
Attention-based Curiosity-driven Exploration in Deep Reinforcement Learning
Oct 23, 2019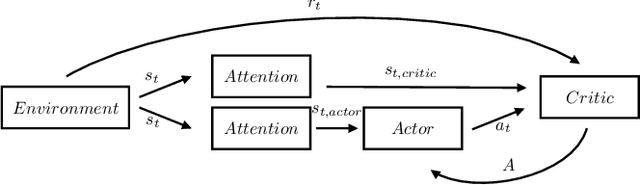



Reinforcement Learning enables to train an agent via interaction with the environment. However, in the majority of real-world scenarios, the extrinsic feedback is sparse or not sufficient, thus intrinsic reward formulations are needed to successfully train the agent. This work investigates and extends the paradigm of curiosity-driven exploration. First, a probabilistic approach is taken to exploit the advantages of the attention mechanism, which is successfully applied in other domains of Deep Learning. Combining them, we propose new methods, such as AttA2C, an extension of the Actor-Critic framework. Second, another curiosity-based approach - ICM - is extended. The proposed model utilizes attention to emphasize features for the dynamic models within ICM, moreover, we also modify the loss function, resulting in a new curiosity formulation, which we call rational curiosity. The corresponding implementation can be found at https://github.com/rpatrik96/AttA2C/.