 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
How Effective are State Space Models for Machine Translation?
Jul 07, 2024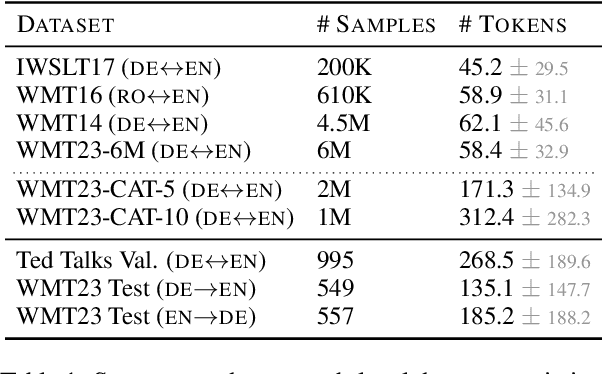
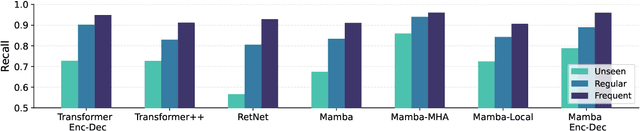
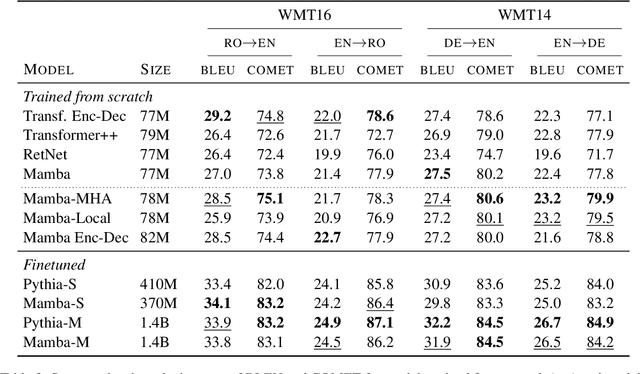
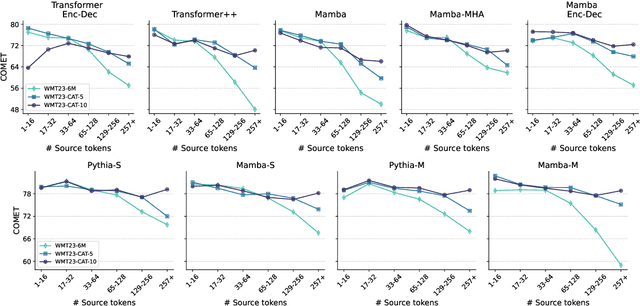
Transformers are the current architecture of choice for NLP, but their attention layers do not scale well to long contexts. Recent works propose to replace attention with linear recurrent layers -- this is the case for state space models, which enjoy efficient training and inference. However, it remains unclear whether these models are competitive with transformers in machine translation (MT). In this paper, we provide a rigorous and comprehensive experimental comparison between transformers and linear recurrent models for MT. Concretely, we experiment with RetNet, Mamba, and hybrid versions of Mamba which incorporate attention mechanisms. Our findings demonstrate that Mamba is highly competitive with transformers on sentence and paragraph-level datasets, where in the latter both models benefit from shifting the training distribution towards longer sequences. Further analysis show that integrating attention into Mamba improves translation quality, robustness to sequence length extrapolation, and the ability to recall named entities.
TopoBenchmarkX: A Framework for Benchmarking Topological Deep Learning
Jun 09, 2024
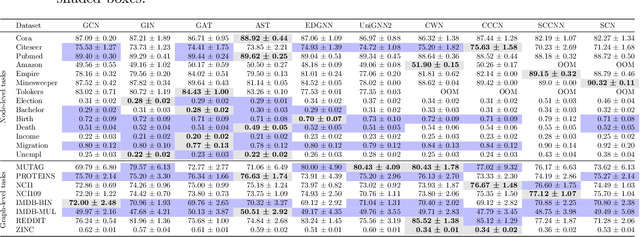
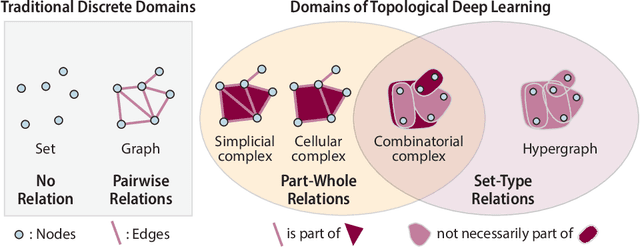
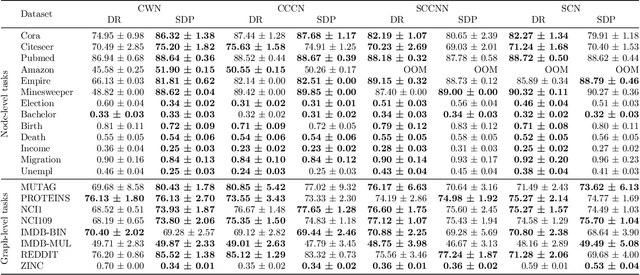
This work introduces TopoBenchmarkX, a modular open-source library designed to standardize benchmarking and accelerate research in Topological Deep Learning (TDL). TopoBenchmarkX maps the TDL pipeline into a sequence of independent and modular components for data loading and processing, as well as model training, optimization, and evaluation. This modular organization provides flexibility for modifications and facilitates the adaptation and optimization of various TDL pipelines. A key feature of TopoBenchmarkX is that it allows for the transformation and lifting between topological domains. This enables, for example, to obtain richer data representations and more fine-grained analyses by mapping the topology and features of a graph to higher-order topological domains such as simplicial and cell complexes. The range of applicability of TopoBenchmarkX is demonstrated by benchmarking several TDL architectures for various tasks and datasets.
Incorporating Graph Information in Transformer-based AMR Parsing
Jun 23, 2023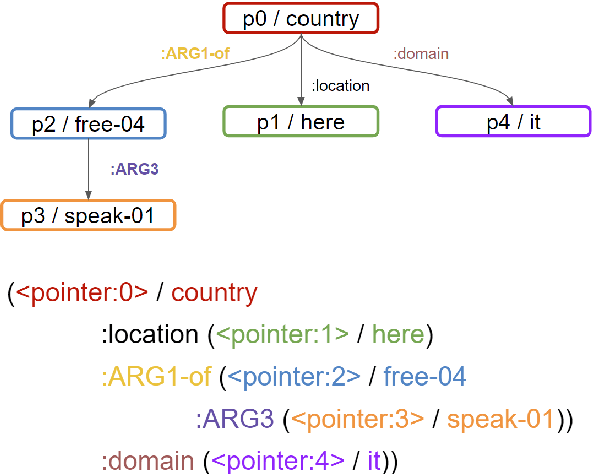
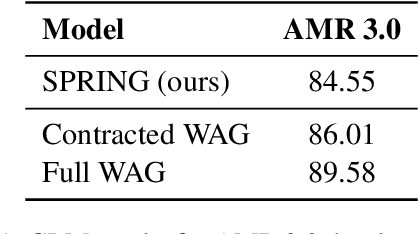
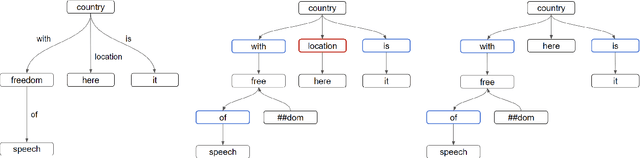

Abstract Meaning Representation (AMR) is a Semantic Parsing formalism that aims at providing a semantic graph abstraction representing a given text. Current approaches are based on autoregressive language models such as BART or T5, fine-tuned through Teacher Forcing to obtain a linearized version of the AMR graph from a sentence. In this paper, we present LeakDistill, a model and method that explores a modification to the Transformer architecture, using structural adapters to explicitly incorporate graph information into the learned representations and improve AMR parsing performance. Our experiments show how, by employing word-to-node alignment to embed graph structural information into the encoder at training time, we can obtain state-of-the-art AMR parsing through self-knowledge distillation, even without the use of additional data. We release the code at \url{http://www.github.com/sapienzanlp/LeakDistill}.