 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
BOOKCOREF: Coreference Resolution at Book Scale
Jul 16, 2025Coreference Resolution systems are typically evaluated on benchmarks containing small- to medium-scale documents. When it comes to evaluating long texts, however, existing benchmarks, such as LitBank, remain limited in length and do not adequately assess system capabilities at the book scale, i.e., when co-referring mentions span hundreds of thousands of tokens. To fill this gap, we first put forward a novel automatic pipeline that produces high-quality Coreference Resolution annotations on full narrative texts. Then, we adopt this pipeline to create the first book-scale coreference benchmark, BOOKCOREF, with an average document length of more than 200,000 tokens. We carry out a series of experiments showing the robustness of our automatic procedure and demonstrating the value of our resource, which enables current long-document coreference systems to gain up to +20 CoNLL-F1 points when evaluated on full books. Moreover, we report on the new challenges introduced by this unprecedented book-scale setting, highlighting that current models fail to deliver the same performance they achieve on smaller documents. We release our data and code to encourage research and development of new book-scale Coreference Resolution systems at https://github.com/sapienzanlp/bookcoref.
Beyond Correlation: Interpretable Evaluation of Machine Translation Metrics
Oct 07, 2024



Machine Translation (MT) evaluation metrics assess translation quality automatically. Recently, researchers have employed MT metrics for various new use cases, such as data filtering and translation re-ranking. However, most MT metrics return assessments as scalar scores that are difficult to interpret, posing a challenge to making informed design choices. Moreover, MT metrics' capabilities have historically been evaluated using correlation with human judgment, which, despite its efficacy, falls short of providing intuitive insights into metric performance, especially in terms of new metric use cases. To address these issues, we introduce an interpretable evaluation framework for MT metrics. Within this framework, we evaluate metrics in two scenarios that serve as proxies for the data filtering and translation re-ranking use cases. Furthermore, by measuring the performance of MT metrics using Precision, Recall, and F-score, we offer clearer insights into their capabilities than correlation with human judgments. Finally, we raise concerns regarding the reliability of manually curated data following the Direct Assessments+Scalar Quality Metrics (DA+SQM) guidelines, reporting a notably low agreement with Multidimensional Quality Metrics (MQM) annotations.
Incorporating Graph Information in Transformer-based AMR Parsing
Jun 23, 2023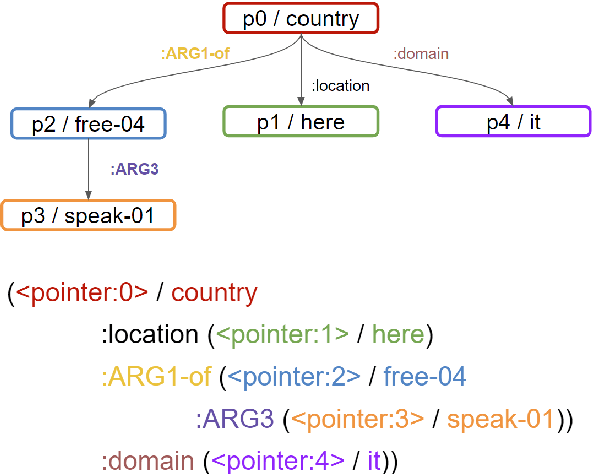
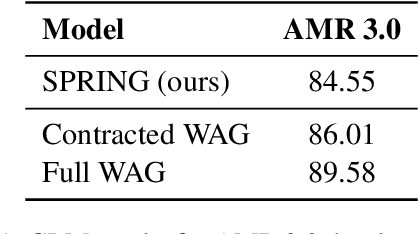
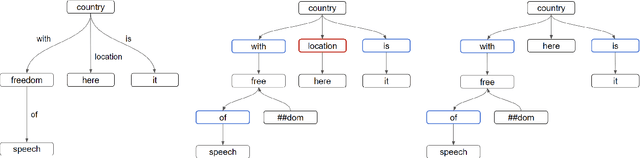

Abstract Meaning Representation (AMR) is a Semantic Parsing formalism that aims at providing a semantic graph abstraction representing a given text. Current approaches are based on autoregressive language models such as BART or T5, fine-tuned through Teacher Forcing to obtain a linearized version of the AMR graph from a sentence. In this paper, we present LeakDistill, a model and method that explores a modification to the Transformer architecture, using structural adapters to explicitly incorporate graph information into the learned representations and improve AMR parsing performance. Our experiments show how, by employing word-to-node alignment to embed graph structural information into the encoder at training time, we can obtain state-of-the-art AMR parsing through self-knowledge distillation, even without the use of additional data. We release the code at \url{http://www.github.com/sapienzanlp/LeakDistill}.
AMRs Assemble! Learning to Ensemble with Autoregressive Models for AMR Parsing
Jun 19, 2023

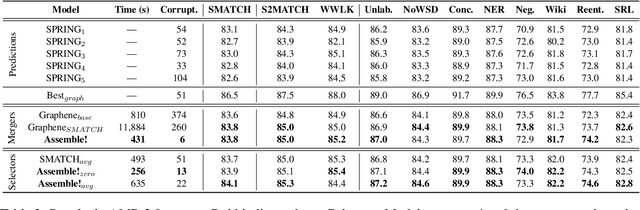

In this paper, we examine the current state-of-the-art in AMR parsing, which relies on ensemble strategies by merging multiple graph predictions. Our analysis reveals that the present models often violate AMR structural constraints. To address this issue, we develop a validation method, and show how ensemble models can exploit SMATCH metric weaknesses to obtain higher scores, but sometimes result in corrupted graphs. Additionally, we highlight the demanding need to compute the SMATCH score among all possible predictions. To overcome these challenges, we propose two novel ensemble strategies based on Transformer models, improving robustness to structural constraints, while also reducing the computational time. Our methods provide new insights for enhancing AMR parsers and metrics. Our code is available at \href{https://www.github.com/babelscape/AMRs-Assemble}{github.com/babelscape/AMRs-Assemble}.
RED$^{\rm FM}$: a Filtered and Multilingual Relation Extraction Dataset
Jun 19, 2023Relation Extraction (RE) is a task that identifies relationships between entities in a text, enabling the acquisition of relational facts and bridging the gap between natural language and structured knowledge. However, current RE models often rely on small datasets with low coverage of relation types, particularly when working with languages other than English. In this paper, we address the above issue and provide two new resources that enable the training and evaluation of multilingual RE systems. First, we present SRED$^{\rm FM}$, an automatically annotated dataset covering 18 languages, 400 relation types, 13 entity types, totaling more than 40 million triplet instances. Second, we propose RED$^{\rm FM}$, a smaller, human-revised dataset for seven languages that allows for the evaluation of multilingual RE systems. To demonstrate the utility of these novel datasets, we experiment with the first end-to-end multilingual RE model, mREBEL, that extracts triplets, including entity types, in multiple languages. We release our resources and model checkpoints at https://www.github.com/babelscape/rebel
AMR Alignment: Paying Attention to Cross-Attention
Jun 15, 2022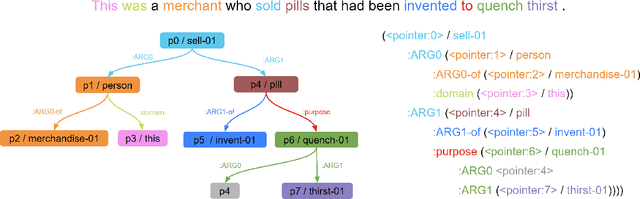
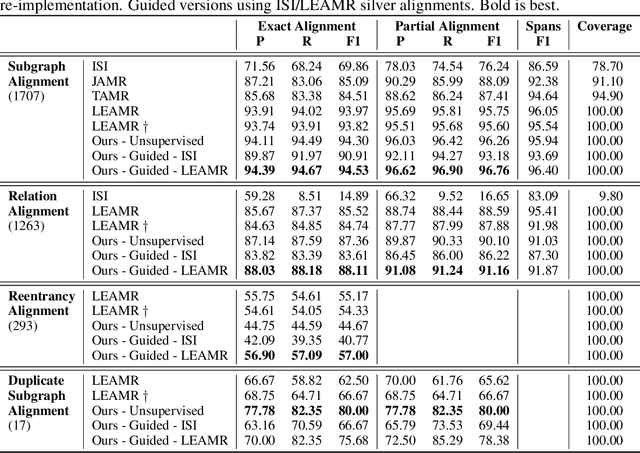

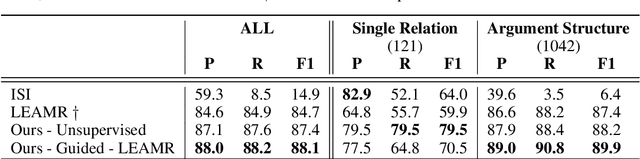
With the surge of Transformer models, many have investigated how attention acts on the learned representations. However, attention is still overlooked for specific tasks, such as Semantic Parsing. A popular approach to the formal representation of a sentence's meaning is Abstract Meaning Representation (AMR). Until now, the alignment between a sentence and its AMR representation has been explored in different ways, such as through rules or via the Expectation Maximization (EM) algorithm. In this paper, we investigate the ability of Transformer-based parsing models to yield effective alignments without ad-hoc strategies. We present the first in-depth exploration of cross-attention for AMR by proxy of alignment between the sentence spans and the semantic units in the graph. We show how current Transformer-based parsers implicitly encode the alignment information in the cross-attention weights and how to leverage it to extract such alignment. Furthermore, we supervise and guide cross-attention using alignment, dropping the need for English- and AMR-specific rules.