 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOOKCOREF: Coreference Resolution at Book Scale
Jul 16, 2025Coreference Resolution systems are typically evaluated on benchmarks containing small- to medium-scale documents. When it comes to evaluating long texts, however, existing benchmarks, such as LitBank, remain limited in length and do not adequately assess system capabilities at the book scale, i.e., when co-referring mentions span hundreds of thousands of tokens. To fill this gap, we first put forward a novel automatic pipeline that produces high-quality Coreference Resolution annotations on full narrative texts. Then, we adopt this pipeline to create the first book-scale coreference benchmark, BOOKCOREF, with an average document length of more than 200,000 tokens. We carry out a series of experiments showing the robustness of our automatic procedure and demonstrating the value of our resource, which enables current long-document coreference systems to gain up to +20 CoNLL-F1 points when evaluated on full books. Moreover, we report on the new challenges introduced by this unprecedented book-scale setting, highlighting that current models fail to deliver the same performance they achieve on smaller documents. We release our data and code to encourage research and development of new book-scale Coreference Resolution systems at https://github.com/sapienzanlp/bookcoref.
Maverick: Efficient and Accurate Coreference Resolution Defying Recent Trends
Jul 31, 2024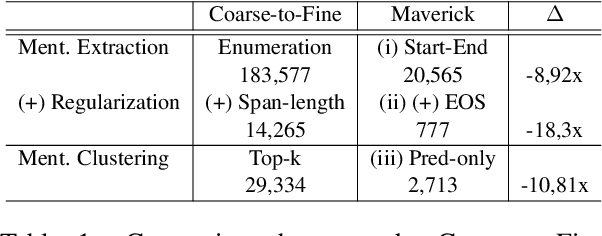


Large autoregressive generative models have emerged as the cornerstone for achieving the highest performance across several Natural Language Processing tasks. However, the urge to attain superior results has, at times, led to the premature replacement of carefully designed task-specific approaches without exhaustive experimentation. The Coreference Resolution task is no exception; all recent state-of-the-art solutions adopt large generative autoregressive models that outperform encoder-based discriminative systems. In this work,we challenge this recent trend by introducing Maverick, a carefully designed - yet simple - pipeline, which enables running a state-of-the-art Coreference Resolution system within the constraints of an academic budget, outperforming models with up to 13 billion parameters with as few as 500 million parameters. Maverick achieves state-of-the-art performance on the CoNLL-2012 benchmark, training with up to 0.006x the memory resources and obtaining a 170x faster inference compared to previous state-of-the-art systems. We extensively validate the robustness of the Maverick framework with an array of diverse experiments, reporting improvements over prior systems in data-scarce, long-document, and out-of-domain settings. We release our code and models for research purposes at https://github.com/SapienzaNLP/maverick-coref.