 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Graph Information in Transformer-based AMR Parsing
Jun 23, 2023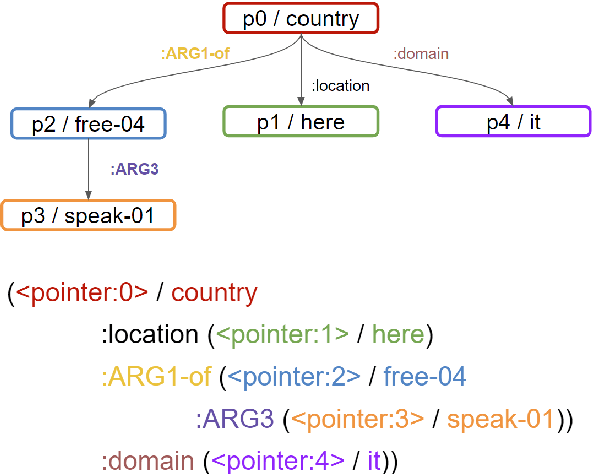
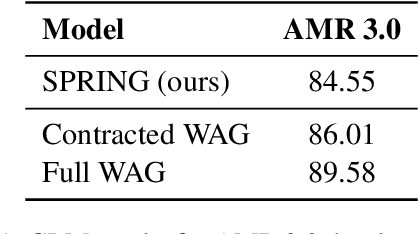
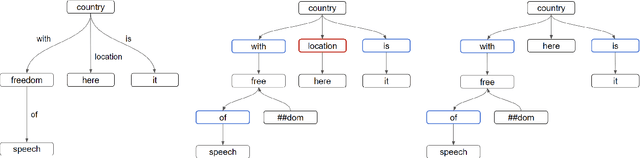

Abstract Meaning Representation (AMR) is a Semantic Parsing formalism that aims at providing a semantic graph abstraction representing a given text. Current approaches are based on autoregressive language models such as BART or T5, fine-tuned through Teacher Forcing to obtain a linearized version of the AMR graph from a sentence. In this paper, we present LeakDistill, a model and method that explores a modification to the Transformer architecture, using structural adapters to explicitly incorporate graph information into the learned representations and improve AMR parsing performance. Our experiments show how, by employing word-to-node alignment to embed graph structural information into the encoder at training time, we can obtain state-of-the-art AMR parsing through self-knowledge distillation, even without the use of additional data. We release the code at \url{http://www.github.com/sapienzanlp/LeakDistill}.
AMRs Assemble! Learning to Ensemble with Autoregressive Models for AMR Parsing
Jun 19, 2023

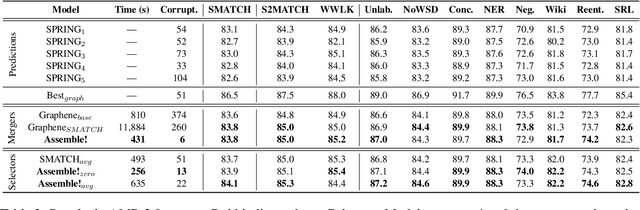

In this paper, we examine the current state-of-the-art in AMR parsing, which relies on ensemble strategies by merging multiple graph predictions. Our analysis reveals that the present models often violate AMR structural constraints. To address this issue, we develop a validation method, and show how ensemble models can exploit SMATCH metric weaknesses to obtain higher scores, but sometimes result in corrupted graphs. Additionally, we highlight the demanding need to compute the SMATCH score among all possible predictions. To overcome these challenges, we propose two novel ensemble strategies based on Transformer models, improving robustness to structural constraints, while also reducing the computational time. Our methods provide new insights for enhancing AMR parsers and metrics. Our code is available at \href{https://www.github.com/babelscape/AMRs-Assemble}{github.com/babelscape/AMRs-Assemble}.
AMR Alignment: Paying Attention to Cross-Attention
Jun 15, 2022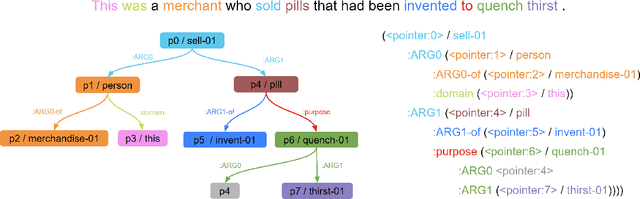
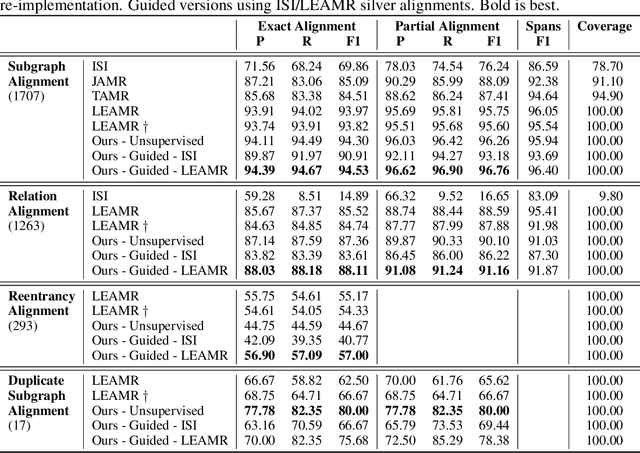

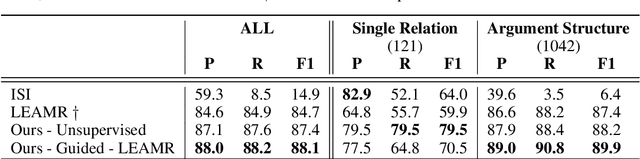
With the surge of Transformer models, many have investigated how attention acts on the learned representations. However, attention is still overlooked for specific tasks, such as Semantic Parsing. A popular approach to the formal representation of a sentence's meaning is Abstract Meaning Representation (AMR). Until now, the alignment between a sentence and its AMR representation has been explored in different ways, such as through rules or via the Expectation Maximization (EM) algorithm. In this paper, we investigate the ability of Transformer-based parsing models to yield effective alignments without ad-hoc strategies. We present the first in-depth exploration of cross-attention for AMR by proxy of alignment between the sentence spans and the semantic units in the graph. We show how current Transformer-based parsers implicitly encode the alignment information in the cross-attention weights and how to leverage it to extract such alignment. Furthermore, we supervise and guide cross-attention using alignment, dropping the need for English- and AMR-specific rules.